Sklearn专题实战——针对Category特征进行分类
文章目录
- 1.前言
- 2.数据处理
- 3.模型构建
- 3.1.支持向量机
- 3.2.贝叶斯
- 4.网格搜索寻找最优结果
- 5.保存模型+提取模型
- 6.混淆矩阵查看分类效果
1.前言
上次回我们是对文本进行情感分类,这次将实战一个稍微复杂的Category分类,即针对每个文本分类处是属于什么类型的文本,如属于电子类、服装类等等。
2.数据处理
class Category:
ELECTRONICS = "ELECTRONICS"
BOOKS = "BOOKS"
CLOTHING = "CLOTHING"
GROCERY = "GROCERY"
PATIO = "PATIO"
class Sentiment:
POSITIVE = "POSITIVE"
NEGATIVE = "NEGATIVE"
NEUTRAL = "NEUTRAL"
class Review:
def __init__(self, category, text, score):
self.category = category
self.text = text
self.score = score
self.sentiment = self.get_sentiment()
def get_sentiment(self):
if self.score <= 2:
return Sentiment.NEGATIVE
elif self.score == 3:
return Sentiment.NEUTRAL
else:
return Sentiment.POSITIVE
class ReviewContainer:
def __init__(self, reviews):
self.reviews = reviews
def get_text(self):
return [x.text for x in self.reviews]
# 将get_text()用vectorizer.transform转化
def get_x(self, vectorizer):
return vectorizer.transform(self.get_text())
def get_y(self):
return [x.sentiment for x in self.reviews]
def get_category(self):
return [x.category for x in self.reviews]
def evenly_distribute(self):
negative = list(filter(lambda x: x.sentiment == Sentiment.NEGATIVE, self.reviews))
positive = list(filter(lambda x: x.sentiment == Sentiment.POSITIVE, self.reviews))
positive_shrunk = positive[:len(negative)]
#print(len(positive_shrunk))
self.reviews = negative + positive_shrunk
random.shuffle(self.reviews)
#print(self.reviews[0])
然后读取五个文件的数据并将它们放在一个变量中:
file_names = ['category/Electronics_small.json', 'category/Books_small.json','category/Clothing_small.json',
'category/Grocery_small.json', 'category/Patio_small.json']
file_categories = [Category.ELECTRONICS, Category.BOOKS, Category.CLOTHING, Category.GROCERY, Category.PATIO]
reviews = []
for i in range(len(file_names)):
file_name = file_names[i]
category = file_categories[i]
with open(file_name) as f:
for line in f:
review_json = json.loads(line) #解码
review = Review(category, review_json["reviewText"], review_json["overall"])
reviews.append(review)
再进行训练集测试集拆分,并分别拿到对应的特征和标签:
train, test = train_test_split(reviews, test_size=0.33, random_state=42)
train_container = ReviewContainer(train)
test_container = ReviewContainer(test)
train_container.evenly_distribute()
test_container.evenly_distribute()
corpus = train_container.get_text()
vectorizer = TfidfVectorizer()
vectorizer.fit(corpus) # 对于训练数据需要先fit
train_x = train_container.get_x(vectorizer)
train_y = train_container.get_category()
test_x = test_container.get_x(vectorizer)
test_y = test_container.get_category()
3.模型构建
3.1.支持向量机
from sklearn.svm import SVC
clf = SVC(C=16, kernel="linear", gamma="auto")
clf.fit(train_x, train_y)
print(clf.score(test_x, test_y))
print(f1_score(test_y, clf.predict(test_x),
average=None, labels=[Category.ELECTRONICS,
Category.BOOKS,Category.CLOTHING,Category.GROCERY,Category.PATIO]))
3.2.贝叶斯
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(train_x.todense(), train_y)
print(gnb.score(test_x.todense(), test_y))
print(f1_score(test_y, gnb.predict(test_x.todense()),average=None, labels=[Category.ELECTRONICS,
Category.BOOKS,Category.CLOTHING,Category.GROCERY,Category.PATIO]))
4.网格搜索寻找最优结果
from sklearn.model_selection import GridSearchCV
parameters = {'kernel':("linear","rbf"), "C":[0.1,1,8,16,32]}
svc = SVC()
clf = GridSearchCV(svc, parameters, cv=5)
clf.fit(train_x, train_y)

print(clf.score(test_x, test_y))

5.保存模型+提取模型
import pickle
with open("category.pkl", "wb") as f:
pickle.dump(clf, f)
with open("vectorizer.pkl", "wb") as f:
pickle.dump(vectorizer, f)
with open("category.pkl", "rb") as f:
clf_loaded = pickle.load(f)
with open("vectorizer.pkl", "rb") as f:
vectorizer = pickle.load(f)
test_set = ["very quick speeds", "loved the dress","bad phone"]
new_test = vectorizer.transform(test_set)
clf_loaded.predict(new_test)
![]()
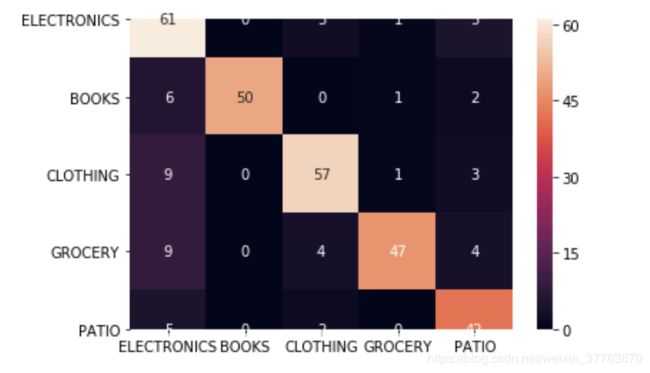
6.混淆矩阵查看分类效果
from sklearn.metrics import confusion_matrix
import seaborn as sn
import pandas as pd
y_pred = clf.predict(test_x)
labels = [Category.ELECTRONICS,Category.BOOKS,Category.CLOTHING,Category.GROCERY,Category.PATIO]
cm = confusion_matrix(test_y, y_pred, labels= labels)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sn.heatmap(df_cm, annot=True, fmt='d')