David Silver 强化学习Lecture3:Dynamic Programming
David Silver 强化学习系列博客的内容整理自David Silver 强化学习的PPT和知乎叶强强化学习专栏。
1 Introduction
1.1 What is Dynamic Programming?
Dynamic:某个问题是由序列化状态组成,状态step-by-step的改变,从而可以step-by-step的来解这个问题。
Programming:是在已知环境动力学的基础上进行评估和控制,具体来说就是在了解包括状态和行为空间、转移概率矩阵、奖励等信息的基础上判断一个给定策略的价值函数,或判断一个策略的优劣并最终找到最优的策略和最优价值函数。
动态规划算法把求解复杂问题分解为求解子问题,通过求解子问题进而得到整个问题的解。在解决子问题的时候,其结果通常需要存储起来被用来解决后续复杂问题。
1.2 Requirements for Dynamic Programming
当问题具有下列特性时,通常可以考虑使用动态规划来求解:
第一个特性是:一个复杂问题的最优解由数个小问题的最优解构成,可以通过寻找子问题的最优解来得到复杂问题的最优解;
第二个特性是:子问题在复杂问题内重复出现,使得子问题的解可以被存储起来重复利用。
马尔科夫决策过程具有上述两个属性:贝尔曼方程把问题递归为求解子问题,价值函数相当于存储了一些子问题的解,可以复用。因此可以使用动态规划来求解马尔科夫决策过程。
1.3 Planning by Dynamic Programming
动态规划求解最优策略,指的是在了解整个MDP的基础上求解最优策略,也就是清楚模型结构的基础上:包括状态行为空间、转换矩阵、奖励等。
预测和控制是规划的两个重要内容。预测是对给定策略的评估过程,控制是寻找一个最优策略的过程。对预测和控制的数学描述是这样:
预测(prediction):已知一个马尔科夫决策过程MDP ⟨S,A,P,R,γ⟩ ⟨ S , A , P , R , γ ⟩ 和一个策略 π π ,或者是给定一个马尔科夫奖励过程MRP ⟨S,Pπ,Rπ,γ⟩ ⟨ S , P π , R π , γ ⟩ ,求解基于该策略 π π 的价值函数 vπ v π 。
控制 (control):已知一个马尔科夫决策过程MDP ⟨S,A,P,R,γ⟩ ⟨ S , A , P , R , γ ⟩ ,求解最优价值函数 v∗ v ∗ 和最优策略 π∗ π ∗ 。
2 Policy Evaluation
2.1 Iterative Policy Evaluation
策略评估 (policy evaluation) 指给定一个MDP和一个策略 π π ,我们来评价这个策略有多好。如何判断这个策略有多好呢?根据基于当前策略 π π 的价值函数 vπ v π 来决定。所以我们的关键就是给定一个MDP和一个策略 π π ,求出价值函数 vπ v π 。
如何求解呢?我们可以使用同步迭代联合动态规划的算法:从任意一个状态价值函数开始,依据给定的策略,结合贝尔曼期望方程、状态转移概率和奖励同步迭代更新状态价值函数,直至其收敛,得到该策略下最终的状态价值函数。理解该算法的关键在于在一个迭代周期内如何更新每一个状态的价值。该迭代法可以确保收敛形成一个稳定的价值函数。
用算法的角度来描述就是:每次迭代过程中,对于第 k+1 k + 1 次迭代,所有的状态 s s 的价值用贝尔曼方程计算 vk(s′) v k ( s ′ ) 并更新该状态第 k+1 k + 1 次迭代中使用的价值 vk(s) v k ( s ) ,其中 s′ s ′ 是 s s 的后继状态。此种方法通过反复迭代最终将收敛至 Vπ V π 。
vk+1(s)=∑a∈Aπ(a|s)[Ras+γ∑s′∈SPass′vk(s′)] v k + 1 ( s ) = ∑ a ∈ A π ( a | s ) [ R s a + γ ∑ s ′ ∈ S P s s ′ a v k ( s ′ ) ]
举例使用同步迭代法进行小型方格世界的策略评估:

这是一个强化学习的问题:如图4×4 的方格阵列,我们把它看成一个小世界。这个世界环境有16个状态,图中每一个小方格对应一个状态,依次用0−15标记它们。图中状态0和15分别位于左上角和右下角,是终止状态,用灰色表示。假设在这个小型方格世界中有一个可以进行上、下、左、右移动的agent,它需要通过移动自己来到达两个灰色格子中的任意一个来完成任务。这个小型格子世界作为环境有着自己的动力学特征:当agent采取的移动行为不会导致agent离开格子世界时,agent将以 100% 的几率到达它所要移动的方向的相邻的那个格子,之所以是相邻的格子而不能跳格是由于环境约束agent每次只能移动一格,同时规定agent也不能斜向移动;如果agent采取会跳出格子世界的行为,那么环境将让agent以 100% 的概率停留在原来的状态;如果agent到达终止状态,任务结束,否则agent可以持续采取行为。每当agent采取了一个行为后,只要这个行为是agent在非终止状态时执行的,不管agent随后到达哪一个状态,环境都将给予agent值为 −1 的奖励值;而当agent处于终止位置时,任何行为将获得值为 0 的奖励并仍旧停留在终止位置。环境设置如此的奖励机制是利用了agent希望获得累计最大奖励的天性,而为了让agent在格子世界中用尽可能少的步数来到达终止状态,因为agent在世界中每多走一步,都将得到一个负值的奖励。为了简化问题,我们设置衰减因子 γ=1 γ = 1 。
在这个小型格子世界的强化学习问题中,agent为了达到在完成任务时获得尽可能多的奖励(在此例中是为了尽可能减少负值奖励带来的惩罚)这个目标,它至少需要思考一个问题:“当处在格子世界中的某一个状态时,我应该采取如何的行为才能尽快到达表示终止状态的格子。”这个问题对于拥有人类智慧的我们来说不是什么难题,因为我们知道整个世界环境的运行规律(动力学特征)。但对于格子世界中的agent来说就不那么简单了,因为agent身处格子世界中一开始并不清楚各个状态之间的位置关系,它不知道当自己处在状态4时只需要选择“向上”移动的行为就可以直接到达终止状态。此时agent能做的就是在任何一个状态时,它选择朝四个方向移动的概率相等。agent想到的这个办法就是一个基于均一概率的随机策略(uniform random policy) 。agent遵循这个均一随机策略,不断产生行为,执行移动动作,从格子世界环境获得奖励(大多数是−1 代表的惩罚),并到达一个新的或者曾经到达过的状态。长久下去,agent会发现:遵循这个均一随机策略时,每一个状态跟自己最后能够获得的最终奖励有一定的关系:在有些状态时自己最终获得的奖励并不那么少;而在其他一些状态时,自己获得的最终奖励就少得多了。agent最终发现,在这个均一随机策略指导下,每一个状态的价值是不一样的。这是一条非常重要的信息。对于agent来说,它需要通过不停的与环境交互,经历过多次的终止状态后才能对各个状态的价值有一定的认识。agent形成这个认识的过程就是策略评估的过程。而作为人类,我们知晓描述整个格子世界的信息特征,不必要向格子世界中的agent那样通过与环境不停的交互来形成这种认识,我们可以直接通过迭代更新状态价值的办法来评估该策略下每一个状态的价值。
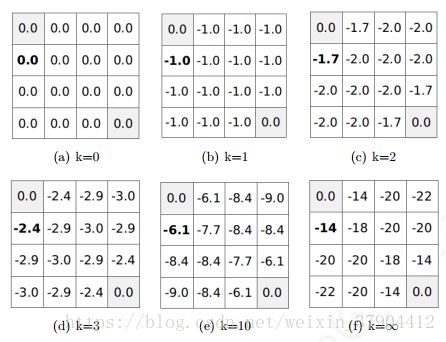
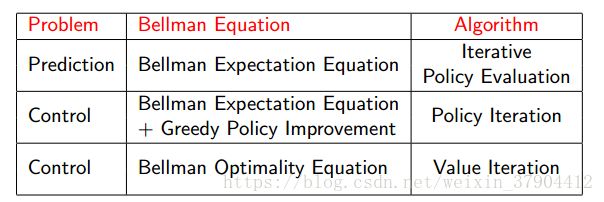
首先,我们假设所有除终止状态以外的14个状态的价值为0。同时,由于终止状态获得的奖励为0,我们可以认为两个终止状态的价值始终保持为0。这样产生了上图(a)中第k=0次迭代的状态价值函数。
在随后的每一次迭代内,agent处于在任意状态都以均等的概率(1/4)选择朝上、下、左、右等四个方向中的一个进行移动;只要agent不处于终止状态,随后产生任意一个方向的移动后都将得到−1的奖励,并依据环境动力学将100%进入行为指向的相邻的格子或碰壁后留在原位,在更新某一状态的价值时需要分别计算4个行为带来的价值分量。
以上图(b)(c)(d)中加粗的状态价值-1.0,-1.7和-2.4为例,详细的计算过程如下:
计算公式:
当前迭代时状态s的价值=
当前状态s向上移动行为的概率 × × [当前状态s向上移动行为的奖励+ γ γ (当前状态s向上移动行为进行下一状态s’的状态转化概率) × × 上一轮迭代时状态s’的价值 ] +
当前状态s向下移动行为的概率 × × [当前状态s向下移动行为的奖励+ γ γ (当前状态s向下移动行为进行下一状态s’的状态转化概率) × × 上一轮迭代时状态s’的价值 ] +
当前状态s向左移动行为的概率 × × [当前状态s向左移动行为的奖励+ γ γ (当前状态s向左移动行为进行下一状态s’的状态转化概率) × × 上一轮迭代时状态s’的价值 ] +
当前状态s向右移动行为的概率 × × [当前状态s向右移动行为的奖励+ γ γ (当前状态s向右移动行为进行下一状态s’的状态转化概率) × × 上一轮迭代时状态s’的价值 ]
代入计算:
−1.0=0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0) − 1.0 = 0.25 ∗ ( − 1 + 1 ∗ 0 ) + 0.25 ∗ ( − 1 + 1 ∗ 0 ) + 0.25 ∗ ( − 1 + 1 ∗ 0 ) + 0.25 ∗ ( − 1 + 1 ∗ 0 )
−1.7=0.25∗(−1+1∗0)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1) − 1.7 = 0.25 ∗ ( − 1 + 1 ∗ 0 ) + 0.25 ∗ ( − 1 + 1 ∗ − 1 ) + 0.25 ∗ ( − 1 + 1 ∗ − 1 ) + 0.25 ∗ ( − 1 + 1 ∗ − 1 )
−2.4=0.25∗(−1+1∗0)+0.25∗(−1+1∗−2)+0.25∗(−1+1∗−1.7)+0.25∗(−1+1∗−2) − 2.4 = 0.25 ∗ ( − 1 + 1 ∗ 0 ) + 0.25 ∗ ( − 1 + 1 ∗ − 2 ) + 0.25 ∗ ( − 1 + 1 ∗ − 1.7 ) + 0.25 ∗ ( − 1 + 1 ∗ − 2 )
3 Policy Iteration
完成对一个策略的评估,将得到基于该策略下每一个状态的价值。很明显,不同状态对应的价值一般也不同,那么agent是否可以根据得到的价值状态来调整自己的行动策略呢,例如考虑一种如下的贪婪策略:agent在某个状态下选择的行为是其能够到达后续所有可能的状态中价值最大的那个状态。我们以均一随机策略下第2次迭代后产生的价值函数为例说明这个贪婪策略。
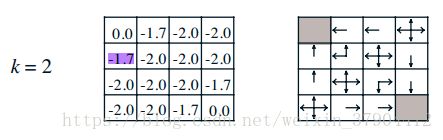
上图所示,右侧是根据左侧各状态的价值绘制的贪婪策略方案。agent处在任何一个状态时,将比较所有后续可能的状态的价值,从中选择一个最大价值的状态,再选择能到达这一状态的行为;如果有多个状态价值相同且均比其他可能的后续状态价值大,那么个体则从这多个最大价值的状态中随机选择一个对应的行为。
在这个小型方格世界中,新的贪婪策略比之前的均一随机策略要优秀不少,至少在靠近终止状态的几个状态中,agent将有一个明确的行为,而不再是随机行为了。我们从均一随机策略下的价值函数中产生了新的更优秀的策略,这是一个策略改善的过程。
更一般的情况是,当给定一个策略 π π 时,可以得到基于该策略的价值函数 vπ v π ,基于产生的价值函数可以得到一个贪婪策略 π'=greedy(vπ) π ′ = g r e e d y ( v π ) 。
依据新的策略 π′ π ′ 会得到一个新的价值函数,并产生新的贪婪策略,如此重复循环迭代将最终得到最优价值函数 v∗ v ∗ 和最优策略 π∗ π ∗ 。策略在循环迭代中得到更新改善的过程称为策略迭代(policy iteration) 。
回过头看看小型方格世界,使用均一随机策略初始化,然后用贪婪策略不断改善的策略迭代过程:
首先零初始化价值函数(如下左图),并采用均一随机策略(如下右图)。

然后,根据上图右边的均一随机策略,第一次迭代产生新的价值函数(如下左图),根据这一新的价值函数,用贪婪策略改善前一个旧的策略,产生新的策略(如下右图)。

根据上图右边的经贪婪策略改善的策略,第二次迭代产生新的价值函数(如下左图),根据这一新的价值函数,用贪婪策略改善前一个旧的策略,产生新的策略(如下右图)。

重复迭代,迭代到第三轮,收敛到最优策略。左图:当前迭代的价值函数;右图:贪婪策略改善前一个旧的策略,得到新的策略。

总结:下图表达了策略迭代的过程。策略迭代分为两个步骤:策略评估和策略改善。策略评估是基于当前的policy计算出每个状态的价值函数;策略评估是基于当前的状态价值函数,用贪婪算法找到当前最优的policy。

图解:从一个初始策略 π π 和初始价值函数 V V 开始,基于该策略进行完整的价值评估过程得到一个新的价值函数,随后依据新的价值函数得到新的贪婪策略,随后计算新的贪婪策略下的价值函数,整个过程反复进行,在这个循环过程中策略和价值函数均得到迭代更新,并最终收敛值最有价值函数和最优策略。除初始策略外,迭代中的策略均是依据价值函数的贪婪策略。
Modified Policy Iteration
有时候不需要持续迭代至最优价值函数,可以设置一些条件提前终止迭代,比如设定一个 ϵ ϵ ,比较两次迭代的价值函数平方差;直接设置迭代次数;以及每迭代一次更新一次策略等。
4 Value Iteration
我们观察一个现象:
如下图,当只采用基于均一随机策略的迭代法进行策略迭代时,需要经过数十次迭代才会收敛,收敛到最优策略。

如下图,当采用均一随机策略初始化,贪婪策略改善进行策略迭代时,在第三次迭代时,得到的策略就是最优策略了。

可见,采用不同的策略,达到最优策略时,所需要的迭代次数不同。我们先从另一个角度剖析一下最优策略的意义。
任何一个最优策略可以分为两个阶段,首先该策略要能产生当前状态下的最优行为,其次对于该最优行为到达的后续状态时该策略仍然是一个最优策略。可以反过来理解这句话:如果一个策略不能在当前状态下产生一个最优行为,或者这个策略在针对当前状态的后续状态时不能产生一个最优行为,那么这个策略就不是最优策略。与价值函数对应起来,可以这样描述状态价值的最优化原则:一个策略能够获得某状态 s s 的最优价值,当且仅当:该策略也同时获得状态 s s 所有可能的后续状态 s' s ′ 的最优价值。
一个状态的最优价值可以由其后续状态的最优价值通过贝尔曼最优方程来计算:
v∗(s)=maxa∈A[Ras+γ∑s′∈SPass′v∗(s′)] v ∗ ( s ) = max a ∈ A [ R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) ]
这个公式告诉我们,如果能知道最终状态的价值和相关奖励,可以直接计算得到最终状态的前一个所有可能状态的最优价值。更乐观的是,即使不知道最终状态是哪一个状态,也可以利用上述公式进行纯粹的价值迭代,不停的更新状态价值,最终得到最优价值。而且这种单纯价值迭代的方法甚至可以允许存在循环的状态转换乃至一些随机的状态转换过程。下面以一个更简单的方格世界来解释什么是单纯的价值迭代。

如图所示是一个在 4×4 方格世界中寻找最短路径的问题。与前述的方格世界问题唯一的不同之处在于,该世界只在左上角有一个最终状态,agent在世界中需尽可能用最少步数到达左上角这个最终状态。
首先考虑到agent知道环境的动力学特征的情形。在这种情况下,agent可以直接计算得到与终止状态直接相邻(斜向不算)的左上角两个状态的最优价值均为−1。随后agent又可以往右下角延伸计算得到与之前最优价值为−1的两个状态香相邻的3个状态的最优价值为−2。以此类推,每一次迭代agent将从左上角朝着右下角方向依次直接计算得到一排斜向方格的最优价值,直至完成最右下角的一个方格最优价值的计算。
现在考虑更广泛适用的,agent不知道环境动力学特征的情形。在这种情况下,agent并不知道终止状态的位置,但是它依然能够直接进行价值迭代。与之前情形不同的是,此时的agent要针对所有的状态进行价值更新。为此,agent先随机地初始化所有状态价值 (V1),示例中为了演示简便全部初始化为 0。在随后的一次迭代过程中,对于任何非终止状态,因为执行任何一个行为都将得到一个−1的奖励,而所有状态的价值都为0,那么所有的非终止状态的价值经过计算后都为−1 (V2)。在下一次迭代中,除了与终止状态相邻的两个状态外的其余状态的价值都将因采取一个行为获得−1的奖励以及在前次迭代中得到的后续状态价值均为 −1,而将自身的价值更新为−2;而与终止状态相邻的两个状态在更新价值时需将终止状态的价值0作为最高价值代入计算,因而这两个状态更新的价值仍然为−1(V3)。依次类推直到最右下角的状态更新为−6后 (V7),再次迭代各状态的价值将不会发生变化,于是完成整个价值迭代的过程。
两种情形的相同点都是根据后续状态的价值,利用贝尔曼最优方程来更新得到前接状态的价值。两者的差别体现在:前者每次迭代仅计算相关的状态的价值,而且一次计算即得到最优状态价值,后者在每次迭代时要更新所有状态的价值。
可以看出价值迭代的目标仍然是寻找到一个最优策略,它通过贝尔曼最优方程从前次迭代的价值函数中计算得到当次迭代的价值函数,在这个反复迭代的过程中,并没有一个明确的策略参与,由于使用贝尔曼最优方程进行价值迭代时类似于贪婪地选择了最有行为对应的后续状态的价值,因而价值迭代其实等效于策略迭代中每迭代一次价值函数就更新一次策略的过程。需要注意的是,在纯粹的价值迭代寻找最优策略的过程中,迭代过程中产生的状态价值函数不对应任何策略。迭代过程中价值函数更新的公式为:
vk+1(s)=maxa∈A[Ras+γ∑s′∈SPass′vk(s′)] v k + 1 ( s ) = max a ∈ A [ R s a + γ ∑ s ′ ∈ S P s s ′ a v k ( s ′ ) ]
其中,k表示迭代次数。公式中可以看出,价值迭代虽然不需要策略参与,但仍然需要知道状态之间的转移概率,也就是需要知道模型。
Summary of DP Algorithms
迭代法策略评估属于预测问题,它使用贝尔曼期望方程来进行求解。策略迭代和价值迭代则属于控制问题,其中前者使用贝尔曼期望方程进行一定次数的价值迭代更新,随后在产生的价值函数基础上采取贪婪选择的策略改善方法形成新的策略,如此交替迭代不断的优化策略;价值迭代则不依赖任何策略,它使用贝尔曼最优方程直接对价值函数进行迭代更新。