python爬虫 爬取动态数据
python的requests库只能爬取静态页面,爬取不了动态加载的页面。但是通过对页面的ajax请求的分析,可以解决一部分动态内容的爬取。这篇文章以爬取百度图片中的动物图片为目标,讲解怎么爬取js动态渲染的内容。
1.首先我们要做的就是抓包。这里我用的是charles抓包工具。百度动物图片
url=“https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&oq=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&rsp=-1”
所以在抓包工具里,先看 https://image.baidu.com 这部分的包。可以看到,这部分包里面,search下面的那个 url和我们访问的地址完全是一样的,但是它的response却包含了js代码。这部分我们看不出来什么。就接着往下看。

2.当在动物图片首页往下滑动页面,想看到更多的时候,更多的包出现了。从图片可以看到,下滑页面后得到的是一连串json数据。在data里面,可以看到thumbURL等字样。它的值是一个url。然后我们可以猜想,这个url就可能是图片的链接。
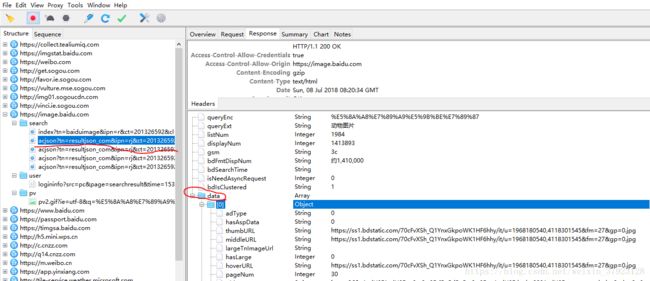
3.我们打开一个浏览器页面,访问thumbURL="https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1968180540,4118301545&fm=27&gp=0.jpg" 发现是下面这货(眼神也是呆萌)。
然后在主页面里我们找到了它:

4.根据前面的分析,就可以知道,请求
URL="https://image.baidu.com/search/acjsontn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf8&oe=utf8&adpicid=&st=-1&z=&ic=0&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1531038037275="会返回图片的链接。如果可以构造这个url,那就可以得到这些图片的下载地址。 但是在构造这个url之前,我们还要做一件事情,就是打开另一个浏览器,访问这个地址。这样做的目的是检测这个地址是可以直接访问,还是会和cookie或者其他一些东西有关。我之前用的搜狗浏览器打开的百度动物图片,现在用fire fox访问这个地址。 幸好,我们得到了全部数据(这里乱码了,但是数据是一样的)。由此可以推测,这个url是公开的。
5.现在要做的就是构造这个url,得到图片地址。通过分析,构造这个URL的各部分值组成了request,每次的request只有pn,rn,gsm和最后那个数字是变化的。通过控制变量法,改变这四个值,然后我发现。pn是每次ajax请求的图片数量。这个值默认是30.我也就不去改它;rn是所有出现过的图片数量;gsm是rn的16进制;最后的数字的值我将它设置为 int(time.time()*1000)。这样改它构造url,解析它返回的json数据,便可以得到图片链接了。
下面是全部的代码:
import requests
import re
import time
import json
import os
from contextlib import closing
from datetime import datetime
import time
session = requests.Session()
requests.packages.urllib3.disable_warnings()
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0"}
def get_img_url():
url_dict = []
per_page_img_num = 30
for i in range(1,2):
all_img_num = per_page_img_num * i
all_img_num_hex = re.match(r'0x(\w+)',hex(all_img_num)).group(1)
time_s = int(time.time())
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn={}&rn={}&gsm={}&{}=".format(per_page_img_num,all_img_num,all_img_num_hex,time_s)
response = session.get(url,headers=headers,verify=False)
json_data = json.loads(response.text)
for num in range(0,20):
url_dict.append(json_data["data"][num]["thumbURL"])
return url_dict
def get_img(url_dict):
file_path = "animal_images"
chunk_size = 1024
img_id = 0
for url in url_dict:
download_img_url = url
if file_path not in os.listdir():
os.makedirs(file_path)
with closing(session.get(download_img_url, headers=headers, verify=False, stream=True)) as response:
img_id += 1
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}已存在,跳过本次下载".format(file))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(file, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(file))
if __name__ == '__main__':
url_dict = get_img_url()
get_img(url_dict)
参考博文:
https://blog.csdn.net/qq_24076135/article/details/78077659
http://brucedone.com/archives/58