[MLReview] Decision Tree 决策树代码实现
决策树
决策树(Decision Tree),简而言之就是根据特征(features)对数据进行划分(patition),构造成树。然后根据树对新的数据进行预测的方法。本质上说是从数据集中归纳出一组分类规则。
我们知道决策树需要根据特征的情况进行划分,那么每一次划分的的时候,该先选取什么特征进行划分呢,这里引入熵的概念。
决策树的算法特点
优点:计算复杂度不高,输出结果易于理解,数据有缺失也能跑,可以处理不相关特征。
缺点:容易过拟合。
适用数据类型:数值型和标称型。
信息增益(information gain)
1、熵(entropy)
大约是初中在化学中学过熵,表示化学反应中的不稳定性或者称之为活跃程度。
在shannon的信息论中,熵(entropy)是随机变量的不确定性的度量,
![]()
X为数据集中的某个特征,x为该特征的某种取值,P(x)为该值在特征中出现的概率。
2、条件熵(conditional entropy)
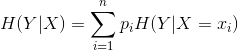
3、信息增益(information gain)
![]()
D是数据集,信息增益的步骤:
输入:数据集D,特征A
输出:特征A对训练数据集D的信息增益g(D,A)
(1)计算数据集D的经验熵H(D)
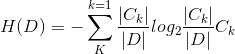
(2)计算特征A对数据集D的经验条件熵H(D,A)
(3)计算信息增益
![]()
4、信息增益比(imformation gain ratio)
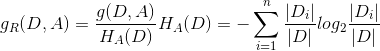
n为特征A取值的个数
决策树工作原理
def createBranch():
'''
此处运用了迭代的思想。 感兴趣可以搜索 迭代 recursion, 甚至是 dynamic programing。
'''
检测数据集中的所有数据的分类标签是否相同:
If so return 类标签
Else:
寻找划分数据集的最好特征(划分之后信息熵最小,也就是信息增益最大的特征)
划分数据集
创建分支节点
for 每个划分的子集
调用函数 createBranch (创建分支的函数)并增加返回结果到分支节点中
return 分支节点
决策树的生成
1、ID3
结合决策树上的结点应用信息增益准则选择特征,递归构建决策树。从根节点开始选取(root node),计算所有特征的信息 增益,选取信息增益最大的特征作为结点的特征,再继续递归构建子结点。相当于极大似然法进行概率模型选择。
![[MLReview] Decision Tree 决策树代码实现_第1张图片](http://img.e-com-net.com/image/info8/a019748a64b248bd966a8aa93ef0a45a.jpg)
2、C4.5
C4.5与ID3的区别在于C4.5使用信息增益比来对特征进行选择,总体而言非常简单。
算法的python实现
1.给定数据集计算shannon entropy
def calcShannonEnt(dataSet):
# 求list的长度,表示计算参与训练的数据量
numEntries = len(dataSet)
# 计算分类标签label出现的次数
labelCounts = {}
# the the number of unique elements and their occurrence
for featVec in dataSet:
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
currentLabel = featVec[-1]
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
# 对于 label 标签的占比,求出 label 标签的香农熵
shannonEnt = 0.0
for key in labelCounts:
# 使用所有类标签的发生频率计算类别出现的概率。
prob = float(labelCounts[key])/numEntries
# 计算香农熵,以 2 为底求对数
shannonEnt -= prob * log(prob, 2)
return shannonEnt
2.按照给定特征划分数据集
def splitDataSet(dataSet, index, value):
"""splitDataSet(通过遍历dataSet数据集,求出index对应的colnum列的值为value的行)
就是依据index列进行分类,如果index列的数据等于 value的时候,就要将 index 划分到我们创建的新的数据集中
Args:
dataSet 数据集 待划分的数据集
index 表示每一行的index列 划分数据集的特征
value 表示index列对应的value值 需要返回的特征的值。
Returns:
index列为value的数据集【该数据集需要排除index列】
"""
retDataSet = []
for featVec in dataSet:
# index列为value的数据集【该数据集需要排除index列】
# 判断index列的值是否为value
if featVec[index] == value:
# chop out index used for splitting
# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行
reducedFeatVec = featVec[:index]
'''
请百度查询一下: extend和append的区别
music_media.append(object) 向列表中添加一个对象object
music_media.extend(sequence) 把一个序列seq的内容添加到列表中 (跟 += 在list运用类似, music_media += sequence)
1、使用append的时候,是将object看作一个对象,整体打包添加到music_media对象中。
2、使用extend的时候,是将sequence看作一个序列,将这个序列和music_media序列合并,并放在其后面。
music_media = []
music_media.extend([1,2,3])
print music_media
#结果:
#[1, 2, 3]
music_media.append([4,5,6])
print music_media
#结果:
#[1, 2, 3, [4, 5, 6]]
music_media.extend([7,8,9])
print music_media
#结果:
#[1, 2, 3, [4, 5, 6], 7, 8, 9]
'''
reducedFeatVec.extend(featVec[index+1:])
# [index+1:]表示从跳过 index 的 index+1行,取接下来的数据
# 收集结果值 index列为value的行【该行需要排除index列】
retDataSet.append(reducedFeatVec)
return retDataSet
3.选择最好的数据集划分
def chooseBestFeatureToSplit(dataSet):
"""chooseBestFeatureToSplit(选择最好的特征)
Args:
dataSet 数据集
Returns:
bestFeature 最优的特征列
"""
# 求第一行有多少列的 Feature, 最后一列是label列嘛
numFeatures = len(dataSet[0]) - 1
# 数据集的原始信息熵
baseEntropy = calcShannonEnt(dataSet)
# 最优的信息增益值, 和最优的Featurn编号
bestInfoGain, bestFeature = 0.0, -1
# iterate over all the features
for i in range(numFeatures):
# create a list of all the examples of this feature
# 获取对应的feature下的所有数据
featList = [example[i] for example in dataSet]
# get a set of unique values
# 获取剔重后的集合,使用set对list数据进行去重
uniqueVals = set(featList)
# 创建一个临时的信息熵
newEntropy = 0.0
# 遍历某一列的value集合,计算该列的信息熵
# 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
# 计算概率
prob = len(subDataSet)/float(len(dataSet))
# 计算信息熵
newEntropy += prob * calcShannonEnt(subDataSet)
# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值
# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
infoGain = baseEntropy - newEntropy
print 'infoGain=', infoGain, 'bestFeature=', i, baseEntropy, newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
4.创建树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
# count() 函数是统计括号中的值在list中出现的次数
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 选择最优的列,得到最优列对应的label含义
bestFeat = chooseBestFeatureToSplit(dataSet)
# 获取label的名称
bestFeatLabel = labels[bestFeat]
# 初始化myTree
myTree = {bestFeatLabel: {}}
# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list
del(labels[bestFeat])
# 取出最优列,然后它的branch做分类
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
# 求出剩余的标签label
subLabels = labels[:]
# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
# print 'myTree', value, myTree
return myTree
5.使用决策树进行分类
def classify(inputTree, featLabels, testVec):
"""classify(给输入的节点,进行分类)
Args:
inputTree 决策树模型
featLabels Feature标签对应的名称
testVec 测试输入的数据
Returns:
classLabel 分类的结果值,需要映射label才能知道名称
"""
# 获取tree的根节点对于的key值
firstStr = inputTree.keys()[0]
# 通过key得到根节点对应的value
secondDict = inputTree[firstStr]
# 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类
featIndex = featLabels.index(firstStr)
# 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类
key = testVec[featIndex]
valueOfFeat = secondDict[key]
print '+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat
# 判断分枝是否结束: 判断valueOfFeat是否是dict类型
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else:
classLabel = valueOfFeat
return classLabel
6.绘制树形图
import matplotlib.pyplot as plt
# 定义文本框 和 箭头格式 【 sawtooth 波浪方框, round4 矩形方框 , fc表示字体颜色的深浅 0.1~0.9 依次变浅,没错是变浅】
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
# 根节点开始遍历
for key in secondDict.keys():
# 判断子节点是否为dict, 不是+1
if type(secondDict[key]) is dict:
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
# 根节点开始遍历
for key in secondDict.keys():
# 判断子节点是不是dict, 求分枝的深度
# ----------写法1 start ---------------
if type(secondDict[key]) is dict:
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
# ----------写法1 end ---------------
# ----------写法2 start --------------
# thisDepth = 1 + getTreeDepth(secondDict[key]) if type(secondDict[key]) is dict else 1
# ----------写法2 end --------------
# 记录最大的分支深度
maxDepth = max(maxDepth, thisDepth)
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
# 获取叶子节点的数量
numLeafs = getNumLeafs(myTree)
# 获取树的深度
# depth = getTreeDepth(myTree)
# 找出第1个中心点的位置,然后与 parentPt定点进行划线
cntrPt = (plotTree.xOff + (1 + numLeafs) / 2 / plotTree.totalW, plotTree.yOff)
# print(cntrPt)
# 并打印输入对应的文字
plotMidText(cntrPt, parentPt, nodeTxt)
firstStr = list(myTree.keys())[0]
# 可视化Node分支点
plotNode(firstStr, cntrPt, parentPt, decisionNode)
# 根节点的值
secondDict = myTree[firstStr]
# y值 = 最高点-层数的高度[第二个节点位置]
plotTree.yOff = plotTree.yOff - 1 / plotTree.totalD
for key in secondDict.keys():
# 判断该节点是否是Node节点
if type(secondDict[key]) is dict:
# 如果是就递归调用[recursion]
plotTree(secondDict[key], cntrPt, str(key))
else:
# 如果不是,就在原来节点一半的地方找到节点的坐标
plotTree.xOff = plotTree.xOff + 1 / plotTree.totalW
# 可视化该节点位置
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
# 并打印输入对应的文字
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1 / plotTree.totalD
def createPlot(inTree):
# 创建一个figure的模版
fig = plt.figure(1, facecolor='green')
fig.clf()
axprops = dict(xticks=[], yticks=[])
# 表示创建一个1行,1列的图,createPlot.ax1 为第 1 个子图,
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
# 半个节点的长度
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
# # 测试画图
# def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# # ticks for demo puropses
# createPlot.ax1 = plt.subplot(111, frameon=False)
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show()
# 测试数据集
def retrieveTree(i):
listOfTrees = [
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
# myTree = retrieveTree(1)
# createPlot(myTree)
项目实例:预测隐形眼镜类型
数据:https://github.com/pbharrin/machinelearninginaction/blob/master/Ch03/lenses.txt
-
收集数据: 提供的文本文件。
-
解析数据: 解析 tab 键分隔的数据行。
-
分析数据: 快速检查数据,确保正确地解析数据内容,使用 createPlot() 函数绘制最终的树形图。
-
训练算法: 使用 createTree() 函数。
-
测试算法: 编写测试函数验证决策树可以正确分类给定的数据实例。
-
使用算法: 存储树的数据结构,以便下次使用时无需重新构造树。
文本数据
young myope no reduced no lenses
pre myope no reduced no lenses
presbyopic myope no reduced no lenses分析数据
>>> treePlotter.createPlot(lensesTree)训练算法
>>> lensesTree = trees.createTree(lenses, lensesLabels)
>>> lensesTree
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic':{'yes':
{'prescript':{'hyper':{'age':{'pre':'no lenses', 'presbyopic':
'no lenses', 'young':'hard'}}, 'myope':'hard'}}, 'no':{'age':{'pre':
'soft', 'presbyopic':{'prescript': {'hyper':'soft', 'myope':
'no lenses'}}, 'young':'soft'}}}}}使用 pickle 模块存储决策树
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)部分codes援引自apacheCN
SKlearn
sklearn源码
import numpy as np
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
def createDataSet():
''' 数据读入 '''
data = []
labels = []
with open("../../../input/3.DecisionTree/data.txt") as ifile:
for line in ifile:
# 特征: 身高 体重 label: 胖瘦
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
# 特征数据
x = np.array(data)
# label分类的标签数据
labels = np.array(labels)
# 预估结果的标签数据
y = np.zeros(labels.shape)
''' 标签转换为0/1 '''
y[labels == 'fat'] = 1
print(data, '-------', x, '-------', labels, '-------', y)
return x, y
def predict_train(x_train, y_train):
'''
使用信息熵作为划分标准,对决策树进行训练
参考链接: http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
'''
clf = tree.DecisionTreeClassifier(criterion='entropy')
# print(clf)
clf.fit(x_train, y_train)
''' 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
print('feature_importances_: %s' % clf.feature_importances_)
'''测试结果的打印'''
y_pre = clf.predict(x_train)
# print(x_train)
print(y_pre)
print(y_train)
print(np.mean(y_pre == y_train))
return y_pre, clf
def show_precision_recall(x, y, clf, y_train, y_pre):
'''
准确率与召回率
参考链接: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_recall_curve.html#sklearn.metrics.precision_recall_curve
'''
precision, recall, thresholds = precision_recall_curve(y_train, y_pre)
# 计算全量的预估结果
answer = clf.predict_proba(x)[:, 1]
'''
展现 准确率与召回率
precision 准确率
recall 召回率
f1-score 准确率和召回率的一个综合得分
support 参与比较的数量
参考链接:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html#sklearn.metrics.classification_report
'''
# target_names 以 y的label分类为准
target_names = ['thin', 'fat']
print(classification_report(y, answer, target_names=target_names))
print(answer)
print(y)
def show_pdf(clf):
'''
可视化输出
把决策树结构写入文件: http://sklearn.lzjqsdd.com/modules/tree.html
Mac报错:pydotplus.graphviz.InvocationException: GraphViz's executables not found
解决方案:sudo brew install graphviz
参考写入: http://www.jianshu.com/p/59b510bafb4d
'''
# with open("testResult/tree.dot", 'w') as f:
# from sklearn.externals.six import StringIO
# tree.export_graphviz(clf, out_file=f)
import pydotplus
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("../../../output/3.DecisionTree/tree.pdf")
# from IPython.display import Image
# Image(graph.create_png())
if __name__ == '__main__':
x, y = createDataSet()
''' 拆分训练数据与测试数据, 80%做训练 20%做测试 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
print('拆分数据:', x_train, x_test, y_train, y_test)
# 得到训练的预测结果集
y_pre, clf = predict_train(x_train, y_train)
# 展现 准确率与召回率
show_precision_recall(x, y, clf, y_train, y_pre)
# 可视化输出
show_pdf(clf)1.决策树分类器
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='gini',
max_depth=4,
random_state=1)
tree.fit(X_train, y_train)
X_combined = np.vstack((X_train, X_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined, y_combined,
classifier=tree, test_idx=range(105, 150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
#plt.savefig('images/03_20.png', dpi=300)
plt.show()
2.决策树回归器
# 引入必要的模型和库
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
# 创建一个随机的数据集
# 参考 https://docs.scipy.org/doc/numpy-1.6.0/reference/generated/numpy.random.mtrand.RandomState.html
rng = np.random.RandomState(1)
# print('lalalalala===', rng)
# rand() 是给定形状的随机值,rng.rand(80, 1)即矩阵的形状是 80行,1列
# sort()
X = np.sort(5 * rng.rand(80, 1), axis=0)
# print('X=', X)
y = np.sin(X).ravel()
# print('y=', y)
y[::5] += 3 * (0.5 - rng.rand(16))
# print('yyy=', y)
# 拟合回归模型
# regr_1 = DecisionTreeRegressor(max_depth=2)
# 保持 max_depth=5 不变,增加 min_samples_leaf=6 的参数,效果进一步提升了
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_2 = DecisionTreeRegressor(min_samples_leaf=6)
# regr_3 = DecisionTreeRegressor(max_depth=4)
# regr_1.fit(X, y)
regr_2.fit(X, y)
# regr_3.fit(X, y)
# 预测
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
# y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
# y_3 = regr_3.predict(X_test)
# 绘制结果
plt.figure()
plt.scatter(X, y, c="darkorange", label="data")
# plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
# plt.plot(X_test, y_3, color="red", label="max_depth=3", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
3. CART生成
CART,即分类与回归树(classification and regression tree),也是一种应用很广泛的决策树学习方法。但是CART算法比较强大,既可用作分类树,也可以用作回归树。作为分类树时,其本质与ID3、C4.5并有多大区别,只是选择特征的依据不同而已。
![[MLReview] Decision Tree 决策树代码实现_第2张图片](http://img.e-com-net.com/image/info8/27d0473c448341579f1f1c487c493a01.jpg)
基尼指数(Gini)
分类树使用gini指数作为最优特征,也决定改特征最优二分点。
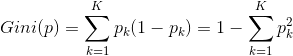
对于给定的样本集合D,gini指数为
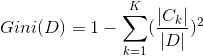
这里![]() 是D中属于第k类的样本子集,K是类的个数
是D中属于第k类的样本子集,K是类的个数
def calcGini(dataSet):
'''
计算基尼指数
:param dataSet:数据集
:return: 计算结果
'''
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: # 遍历每个实例,统计标签的频数
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
Gini = 1.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
Gini -= prob * prob # 以2为底的对数
return Gini给定特征A时,集合D的基尼指数是
![]()
Gini(D)表示集合D的不确定性,与熵类似。
def calcGiniWithFeat(dataSet, feature, value):
'''
计算给定特征下的基尼指数
:param dataSet:数据集
:param feature:特征维度
:param value:该特征变量所取的值
:return: 计算结果
'''
D0 = []; D1 = []
# 根据特征划分数据
for featVec in dataSet:
if featVec[feature] == value:
D0.append(featVec)
else:
D1.append(featVec)
Gini = len(D0) / len(dataSet) * calcGini(D0) + len(D1) / len(dataSet) * calcGini(D1)
return Gini
分类树python实现如下
def chooseBestSplit(dataSet):
numFeatures = len(dataSet[0])-1
bestGini = inf; bestFeat = 0; bestValue = 0; newGini = 0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
for splitVal in uniqueVals:
newGini = calcGiniWithFeat(dataSet, i, splitVal)
if newGini < bestGini:
bestFeat = i
bestGini = newGini
return bestFeat
# for featVec in dataSet:
# for splitVal in set(dataSet[:,featIndex].tolist()):
# newGini = calcGiniWithFeat(dataSet, featIndex, splitVal)
# if newGini < bestGini:
# bestFeat = featIndex
# bestValue = splitVal
# bestGini = newGini
def majorityCnt(classList):
'''
采用多数表决的方法决定叶结点的分类
:param: 所有的类标签列表
:return: 出现次数最多的类
'''
classCount={}
for vote in classList: # 统计所有类标签的频数
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 排序
return sortedClassCount[0][0]
def createTree(dataSet,labels):
'''
创建决策树
:param: dataSet:训练数据集
:return: labels:所有的类标签
'''
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0] # 第一个递归结束条件:所有的类标签完全相同
if len(dataSet[0]) == 1:
return majorityCnt(classList) # 第二个递归结束条件:用完了所有特征
bestFeat = chooseBestSplit(dataSet) # 最优划分特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}} # 使用字典类型储存树的信息
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] # 复制所有类标签,保证每次递归调用时不改变原始列表的内容
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree 1. 导入数据
# 导入数据
def createDataSet():
dataSet = [['youth', 'no', 'no', 1, 'refuse'],
['youth', 'no', 'no', '2', 'refuse'],
['youth', 'yes', 'no', '2', 'agree'],
['youth', 'yes', 'yes', 1, 'agree'],
['youth', 'no', 'no', 1, 'refuse'],
['mid', 'no', 'no', 1, 'refuse'],
['mid', 'no', 'no', '2', 'refuse'],
['mid', 'yes', 'yes', '2', 'agree'],
['mid', 'no', 'yes', '3', 'agree'],
['mid', 'no', 'yes', '3', 'agree'],
['elder', 'no', 'yes', '3', 'agree'],
['elder', 'no', 'yes', '2', 'agree'],
['elder', 'yes', 'no', '2', 'agree'],
['elder', 'yes', 'no', '3', 'agree'],
['elder', 'no', 'no', 1, 'refuse'],
]
labels = ['age', 'working?', 'house?', 'credit_situation']
return dataSet, labels
# 测试代码
if __name__ == "__main__":
myDat, labels = tree.createDataSet()
myTree = tree.createTree(myDat, labels)
print(myTree)
createPlot(myTree)
2. 测试分类树
if __name__ == "__main__":
dataSet,labels = createDataSet()
subLabels = labels[:]
myTree = createTree(dataSet, labels)
print(myTree)
treePlotter.createPlot(myTree)3. 计算预测误差
# 计算预测误差
def calcTestErr(myTree,testData,labels):
errorCount = 0.0
for i in range(len(testData)):
if classify(myTree,labels,testData[i]) != testData[i][-1]:
errorCount += 1
return float(errorCount)
testData,testLabels = loadTestData()
testErr = calcTestErr(myTree, testData, subLabels)
剪枝(pruning)
在决策树学习中将已生成的树进行简化的过程称为剪枝。决策树的剪枝往往通过极小化决策树的损失函数或代价函数来实现。实际上剪枝的过程就是一个动态规划的过程:从叶结点开始,自底向上地对内部结点计算预测误差以及剪枝后的预测误差,如果两者的预测误差是相等或者剪枝后预测误差更小,当然是剪掉的好。但是如果剪枝后的预测误差更大,那就不要剪了。剪枝后,原内部结点会变成新的叶结点,其决策类别由多数表决法决定。不断重复这个过程往上剪枝,直到预测误差最小为止。剪枝的实现代码如下:
# 计算预测误差
def calcTestErr(myTree,testData,labels):
errorCount = 0.0
for i in range(len(testData)):
if classify(myTree,labels,testData[i]) != testData[i][-1]:
errorCount += 1
return float(errorCount)
# 计算剪枝后的预测误差
def testMajor(major,testData):
errorCount = 0.0
for i in range(len(testData)):
if major != testData[i][-1]:
errorCount += 1
return float(errorCount)
def pruningTree(inputTree,dataSet,testData,labels):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr] # 获取子树
classList = [example[-1] for example in dataSet]
featKey = copy.deepcopy(firstStr)
labelIndex = labels.index(featKey)
subLabels = copy.deepcopy(labels)
del(labels[labelIndex])
for key in list(secondDict.keys()):
if isTree(secondDict[key]):
# 深度优先搜索,递归剪枝
subDataSet = splitDataSet(dataSet,labelIndex,key)
subTestSet = splitDataSet(testData,labelIndex,key)
if len(subDataSet) > 0 and len(subTestSet) > 0:
inputTree[firstStr][key] = pruningTree(secondDict[key],subDataSet,subTestSet,copy.deepcopy(labels))
if calcTestErr(inputTree,testData,subLabels) < testMajor(majorityCnt(classList),testData):
# 剪枝后的误差反而变大,不作处理,直接返回
return inputTree
else:
# 剪枝,原父结点变成子结点,其类别由多数表决法决定
return majorityCnt(classList)剪枝后的预测误差为0,说明模型的泛化能力很强。
回归树
最小二乘回归树生成算法
![[MLReview] Decision Tree 决策树代码实现_第3张图片](http://img.e-com-net.com/image/info8/fbceef87da2842f4bdd5a3bac53924d6.jpg)
python实现:
# 生成叶结点
def regLeaf(dataSet):
return mean(dataSet[:,-1])
# 计算平方误差
def regErr(dataSet):
return var(dataSet[:,-1]) * shape(dataSet)[0]
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
tolS = ops[0]; tolN = ops[1]
if len(set(dataSet[:,-1].T.tolist())) == 1: # 停止条件:样本属于同一个类
return None, leafType(dataSet)
m,n = shape(dataSet)
S = errType(dataSet)
bestS = inf; bestIndex = 0; bestValue = 0
for featIndex in range(n-1):
for splitVal in set(dataSet[:,featIndex].tolist()):# 固定特征,并为每个特征选择最优二分特征值
R0, R1 = binSplitDataSet(dataSet, featIndex, splitVal)
if (shape(R0)[0] < tolN) or (shape(R1)[0] < tolN): continue
newS = errType(R0) + errType(R1)
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
# 如果误差下降值小于一个阈值,则不要划分
if (S - bestS) < tolS:
return None, leafType(dataSet) #exit cond 2
R0, R1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (shape(R0)[0] < tolN) or (shape(R1)[0] < tolN): # 停止条件:样本数小于一个阈值
return None, leafType(dataSet)
return bestIndex,bestValue
构建回归树:
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)# 选择最优二分方式
if feat == None: return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
leftSet, rightSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(leftSet, leafType, errType, ops)
retTree['right'] = createTree(rightSet, leafType, errType, ops)
return retTree
剪枝
def isTree(obj):
return (type(obj).__name__=='dict')
def getMean(tree):
if isTree(tree['right']): tree['right'] = getMean(tree['right'])
if isTree(tree['left']): tree['left'] = getMean(tree['left'])
return (tree['left']+tree['right'])/2.0
def prune(tree, testData):
if shape(testData)[0] == 0: return getMean(tree) # 如果没有测试数据则对树进行塌陷处理
if (isTree(tree['right']) or isTree(tree['left'])):
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
# 深度优先搜索
if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet)
if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet)
# 到达叶结点
if not isTree(tree['left']) and not isTree(tree['right']):
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
# 未剪枝的误差
errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) +\
sum(power(rSet[:,-1] - tree['right'],2))
treeMean = (tree['left']+tree['right'])/2.0
# 剪枝后的误差
errorMerge = sum(power(testData[:,-1] - treeMean,2))
if errorMerge < errorNoMerge:
print("merging")
return treeMean
else: return tree
else: return tree部分援引自【机器学习】决策树(上)——从原理到算法实现
总结
决策树模型算比较简单的模型,文中主要叙述了基本的决策树C4.5生成算法、CART回归分类树、剪枝等算法的原理及代码实现。后面还有随机森林即是结合决策树及bagging思想的结合。以及GDBT等算法,之后会一一叙述。