JDK源码阅读计划(Day12) BitSet
JDK11
BitMap原理&使用场景
用一个bit来存放一个状态的容器。由于对内存占用少,适合用于处理大规模数据和数据状态不多的情况。毕竟一个bit只对应两个状态。
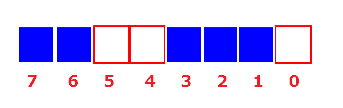
图来自ref
假设原来有个int数组[1,2,3,6,7]需要用5*32bit=160bit来保存存储空间。
但如果把元素的值作为下标每个下标用一个bit来表示,如0表示不存在该元素,1表示存在。那么只需要在内存空间开辟一个bit大小为8的数组。
- 场景一:
O(1)的海量数据的查重。
- 场景二:
判断两个数组重复元素。原先方案需要做一个两层for循环,现在只需要两个bitMap做与操作。
- 场景三:
如果数据分布不均匀,如数组是1,100,100000000,那么为了存储100000000需要开100000001个bit,造成较大空间浪费。可以使用roaring map
- 场景四:
Bloom Filter的实现
类继承关系
public class BitSet implements Cloneable, Serializable
BitSet虽然叫做Set,在java.util包中,但事实上和Set,List这些接口一点关系都没有
重要成员
可以看到最重要BitSet本质上就是用一个long数组来存储bit的信息,默认每一个long可以存储64bit
/*
* BitSets are packed into arrays of "words." Currently a word is
* a long, which consists of 64 bits, requiring 6 address bits.
* The choice of word size is determined purely by performance concerns.
*/
private static final int ADDRESS_BITS_PER_WORD = 6;
// 每个word所占的位数:64bit,(这里所谓的word就是long类型)
private static final int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
private static final int BIT_INDEX_MASK = BITS_PER_WORD - 1;
/* Used to shift left or right for a partial word mask */
private static final long WORD_MASK = 0xffffffffffffffffL;
/**
* The internal field corresponding to the serialField "bits".
*/
/*
* 存储word,其实就是存储位集中的bit
* 在计算位的时候,需要从左到右取出word,并从右到左排列。
*/
private long[] words;
/**
* The number of words in the logical size of this BitSet.
*/
// 位集正在被使用的字的长度
private transient int wordsInUse = 0;
/**
* Whether the size of "words" is user-specified. If so, we assume
* the user knows what he's doing and try harder to preserve it.
*/
// 字的大小是否为用户指定
private transient boolean sizeIsSticky = false;
构造函数
- 默认构造函数
默认初始会为words数组分配一个元素
/**
* Creates a new bit set. All bits are initially {@code false}.
*/
// 构造可以存储64个bit的位集(即1个word)
public BitSet() {
// 由给定的bit数量,构造一个匹配大小的long数组存储bit
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
我们来看initWords,作用是根据bitSet的bit的大小来判断需要分配多少个word
/*
* 由给定的bit数量,构造一个匹配大小的long数组存储bit。
* 这里会向上取整,比如输入60,则虽然不足64位,却也构造包含一个long的word数组。
*/
private void initWords(int nbits) {
// 计算指定索引处的bit所在的word的索引
//64-1 = 1 1111
int size = wordIndex(nbits - 1);
words = new long[size + 1];
}
/**
* Given a bit index, return word index containing it.
*/
// 计算指定索引处的bit所在的word的索引
private static int wordIndex(int bitIndex) {
//1 1111 >> 6 = 0 说明 0-63bit对应的word索引为0
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
其他构造函数
// 构造至少可以存储nbits个bit的位集
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if(nbits<0) {
throw new NegativeArraySizeException("nbits < 0: " + nbits);
}
// 由给定的bit数量,构造一个匹配大小的long数组存储bit
initWords(nbits);
sizeIsSticky = true;
}
/**
* Creates a bit set using words as the internal representation.
* The last word (if there is one) must be non-zero.
*/
// 构造可以存储words.length个word的位集,且该位集正在被使用
private BitSet(long[] words) {
this.words = words;
this.wordsInUse = words.length;
checkInvariants();
}
get
判断指定为是否为1
// 判断bitIndex处的bit是否为1(bitIndex需要从右往左计数)
public boolean get(int bitIndex) {
if(bitIndex<0) {
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
checkInvariants();
int wordIndex = wordIndex(bitIndex);
return (wordIndex<wordsInUse) && ((words[wordIndex] & (1L << bitIndex)) != 0);
}
取出bitIndex对应的wordIndex,然后bitIndex与1做与操作,如果原来bitIndex位也为1则与操作的结果肯定不为0。注意java中的移位操作会模除位数
例如左移65位,实际上会移除"65%64 = 1"位
set
把某个指定位上的bit设置为true,为了防止bitIndex大于现在bitset的available bit, 还会进行动态扩容
/*
* 将位集中指定索引处的bit设置为1。
* 注:索引是从右往左计数的。
*/
public void set(int bitIndex) {
if(bitIndex<0) {
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
// 计算指定索引处的bit所在的word的索引
int wordIndex = wordIndex(bitIndex);
// 尝试扩容位集,使其足够存放wordIndex + 1个bit
expandTo(wordIndex);
// 设置bit
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
expandTo
/**
* Ensures that the BitSet can accommodate a given wordIndex,
* temporarily violating the invariants. The caller must
* restore the invariants before returning to the user,
* possibly using recalculateWordsInUse().
*
* @param wordIndex the index to be accommodated.
*/
// 尝试扩容位集,使其足够存放wordIndex + 1个bit
private void expandTo(int wordIndex) {
//因为bit从0开始算
int wordsRequired = wordIndex + 1;
if(wordsInUse<wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
关键是ensureCapacity这个方法,可以看到会把words数组容量扩大为原来的2倍
private void ensureCapacity(int wordsRequired) {
// 容量充足则直接返回
if(words.length >= wordsRequired) {
return;
}
// Allocate larger of doubled size or required size
int request = Math.max(2 * words.length, wordsRequired);
words = Arrays.copyOf(words, request);
sizeIsSticky = false;
}
flip
套路一样,异或操作就完事儿了
// 翻转指定索引处的bit,即从0到1,或从1到0(索引从右往左计数)
public void flip(int bitIndex) {
if(bitIndex<0) {
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] ^= (1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
尝试自己写一个简单的BitMap demo
package BitMap;
import java.util.Arrays;
public class BitMap {
//每个word所占的bit 默认为64
private static final int BITS_PER_WORD = 64;
//long 64bit = 1 << 6
private static final int ADDRESS_BITS_PER_WORD = 6;
//用long类型的word来存储bit,可以尽可能减少word个数
private long[] words;
//默认每个word存储64bit
//默认构造一个bit
public BitMap() {
initWords(BITS_PER_WORD);
}
public BitMap(int bitsPerWord){
initWords(bitsPerWord);
}
private void initWords(int bitsPerWord) {
int size = wordIndex(bitsPerWord -1);
this.words = new long[size + 1];
}
private int wordIndex(int bits) {
return bits >> 6;
}
//get方法
//判断位图中bitIndex对应的bit是否为1 bitIndex从右往左计数
public boolean get(int bitIndex) {
if (bitIndex < 0){
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
//寻找存储该bit的对应的word
int wordIndex = wordIndex(bitIndex);
// 判断对应的bit的wordIndex是否越界&与操作判断该位是否为1
return (wordIndex < words.length) && ((this.words[wordIndex] & (1L << bitIndex)) != 0);
}
//set方法 指定bitIndex设为1
public void set(int bitIndex) {
if (bitIndex < 0){
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
//寻找存储该bit的对应的word
int wordIndex = wordIndex(bitIndex);
//尝试扩容 确保words能够存放wordIndex + 1 个bit
tryExpand(wordIndex);
this.words[wordIndex] |= (1L << bitIndex);
}
public void flip(int bitIndex) {
if (bitIndex < 0){
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
}
//寻找存储该bit的对应的word
int wordIndex = wordIndex(bitIndex);
this.words[wordIndex] ^= (1L << bitIndex);
}
public boolean empty() {
return words.length == 0;
}
// 判断两个bitmap是否有交集
public boolean intersects(BitMap b){
if(b.empty())return false;
for(int idx = Math.min(b.words.length, this.words.length) - 1; idx >=0; idx--) {
if((b.words[idx] & this.words[idx]) != 0){
return true;
}
}
return false;
}
public int OneBitCount() {
int sum = 0;
for(int i = 0; i<words.length;i++){
sum += Long.bitCount(words[i]);
}
return sum;
}
private void tryExpand(int wordIndex) {
int wordRequired = wordIndex + 1;
if(wordRequired<=words.length)return;
int newLength = Math.max(2*words.length, wordRequired);
words = Arrays.copyOf(words, newLength);
}
private int wordCount() {
return this.words.length;
}
public static void main(String[] args) {
//By default word size is 1.
BitMap bitMap = new BitMap();
//Test1 set & get
for(int i = 0; i < 10; i++){
bitMap.set(i);
}
for(int i = 0; i < 15; i++){
System.out.println("i= " + i + " " + bitMap.get(i));
}
//Test2
System.out.println(bitMap.OneBitCount());
//Test3 interset
BitMap bitMap1 = new BitMap();
BitMap bitMap2 = new BitMap();
for(int i = 0; i < 12; i++){
bitMap1.set(i);
}
for(int i = 11; i < 20; i++) {
bitMap2.set(i);
}
//true
System.out.println(bitMap.intersects(bitMap1));
//false
System.out.println(bitMap.intersects(bitMap2));
//Test4 flip
bitMap.flip(5);
System.out.println(bitMap.get(5)); //false
//Test 5 tryExpand
bitMap.set(100);
System.out.println(bitMap.wordCount()); //2
}
}
然后主要是BitSet的操作场景,写一些demo看看就是了
- 有 1 千万个随机数,随机数的范围在 1 到 1 亿之间。现在要求写出一种算法,将 1 到 1 亿之间没有在随机数中的数求出来
List<Integer> randomList = new ArrayList<>();
Random random = new Random();
for(int i = 0; i < 10000000; i++){
randomList.add(random.nextInt(100000000)+1);
}
BitSet bitSet = new BitSet(100000001);
List<Integer> notInRandomList = new ArrayList<>();
for(int i = 0; i <= 10000000;i++){
if(!bitSet.get(i)){
notInRandomList.add(i);
}
}
ref
https://juejin.im/post/5c90d5fbe51d454e773a64ea