RS Meet DL(57)-[阿里]如何精确推荐一屏物品?
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第1张图片](http://img.e-com-net.com/image/info8/b8ceff80e55b4caeb573d0bc51469968.jpg)
今天介绍的论文题目是:《Exact-K Recommendation via Maximal Clique Optimization》
论文下载地址为:https://arxiv.org/pdf/1905.07089.pdf
之前介绍的推荐模型,大都是Top-K推荐的,也就是说,我们首先会对每个物品的CTR等进行预估,然后进行排序,将排序结果的前K个推荐给用户。这么做比较简单,但是忽略了推荐物品之间的内在联系。今天给大家分享的论文是阿里在KDD2019发表的论文,它能够综合考虑生成一个包含k个item的最优化集合,一起来了解一下吧。
1、背景
在许多推荐场景中,我们都需要一次性推荐一屏(论文中用到的词是card,这里我们暂且翻译为屏)的物品给用户,如下图:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第2张图片](http://img.e-com-net.com/image/info8/031a30eb827b4a1fb49282dc10971708.jpg)
文中将这种场景称之为exact-K recommendation问题,这种问题的首要目标是提升这一屏被点击或者满足目标用户需求的概率。同时,同一屏中的物品往往要满足一定的限制,比如推荐物品之间需要具有一定的多样性。
相比于传统的top-K推荐问题,exact-K推荐可以被视作一种多目标优化问题。在第二节中,我们一起来看看,阿里是如何做exact-K推荐的。
2、模型介绍
2.1 问题定义
对于给定的包含N个物品的候选集合S={si},我们的目标是从中选择K个物品集合A={ai},并将这K个物品作为一屏推荐给用户。
这里,我们把A满足会被用户u点击或者满足用户u需求的概率定义为P(A,r=1|S,u),同时,A中的物品两两之间有时需要满足一定的条件限制,定义为:
![]()
ck可以理解为两个物品之间的某种限制,如果满足限制,则ck=1,如果不满足限制,则ck=0。当然,物品之间有时也不需要条件限制,此时C=Ø。
这里的条件限制可能比较难理解,通过文中实验部分的数据集介绍给出一个例子。假设我们希望推荐的一屏结果中,两两物品之间的相关性没有那么高,也就是说多样性尽量多一些,此时我们的限制C定义为:
![]()
上图中的NED代表两个物品的名称之间的归一化编辑距离(normalized edit distance)。NED的计算方法就是编辑距离除以两个标题长度的较大值:
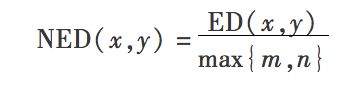
回到正题,我们刚才描述的问题可以形式化表示为下面的组合优化问题:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第3张图片](http://img.e-com-net.com/image/info8/17fa2299df2c44f4b399e2ddc8ef380d.jpg)
从图论的角度,可以重新理解一下我们刚才的问题。首先,把S中包含的N个物品作为图中的N个节点,节点ni代表物品si。如果物品之间的限制条件为空即C=Ø时,图中两两物品之间的都有边相连,如果C不为Ø时,只有满足了条件ck的物品之间才有边相连。既然要求推荐的K个物品两两之间都要满足条件ck,因此问题变为了图中一个非常经典的问题,即在图中找到一个K个节点的完全子图(完全子图即两两节点之间都有边的子图):
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第4张图片](http://img.e-com-net.com/image/info8/2720911d4e294ea0b62b8ee8e656190f.jpg)
2.2 朴素节点权重估计方法
这里首先介绍一种Base的方法,过程如下:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第5张图片](http://img.e-com-net.com/image/info8/8903fef9d892424e9e792001eec2ed00.jpg)
过程表述如下:
1)对于给定的用户u和候选集合S,首先构造一张无向图;
2)计算图中每个节点的点击率CTR;
3)基于贪心的思路,从当前的候选集合中选择点击率最高的一个节点,加入到推荐结果集A中,并把至少与A中一个物品不相连的物品从当前的候选集中去掉;
4)重复第3步直到得到包含K个物品的推荐结果集合A。
这样做的缺点时我们无法得到一个最优解,仅能得到次优解。同时,点击率预估是单独针对一个物品来计算的,而且K个物品之间的组合关系也没有很好的考虑。因此,我们在下一节中将介绍本文提出的基于神经网络的方法。
2.3 Graph Attention Networks
本文提出的方法称为Graph Attention Networks,简称为GAttN,整体的框架如下图所示:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第6张图片](http://img.e-com-net.com/image/info8/697f48b382a045f1a2d6ea940c98d831.jpg)
整体的框架是一个Encoder-Decoder,但是Encoder和Decoder的设计包含一些业务思考。
2.3.1 Input
对于给定的图,图中每个节点ni对应的物品si的特征记作xsi,用户u的特征记作xu。因此Encoder的每个阶段的输入xi计算如下:
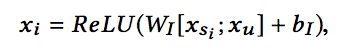
2.3.2 Encoder
传统的Encoder往往选择循环神经网络,但这里顺序是没有意义的,因为输入的各个物品之间是无序的。尽管各个物品之间无序,但它们之间的相互影响还是需要考虑的。所以,这里的Encoder选择的是Transformer。
Transformer我们之前已经介绍过很多次了,这里不再赘述,如果感兴趣的同学可以参考文章:https://www.jianshu.com/p/2b0a5541a17c
Encoder使用多层的block,最后一层L层的输出为:
![]()
2.3.3 Decoder
对于Decoder来说,要输出K个物品集合A,代表图中的一个包含K个节点的完全子图。这里使用的是循环神经网络,输出的集合是A的概率计算方式如下:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第7张图片](http://img.e-com-net.com/image/info8/85b7c7d706794e8784a7f21e0505dba3.jpg)
这里f(S,u;θe)代表的是encoder,θd代表的是decoder的参数。得到输出是集合A的概率可以表示为得到A中每个物品的概率的乘积。
进一步,由于是循环神经网络,在得到ai时,输入包含两部分,一个是上一个阶段的隐藏层状态di-1,另一个是上一阶段的输出ai-1,因此可以得到下面的式子:
![]()
其中:
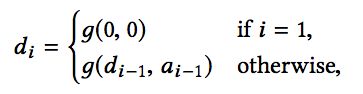
接下来,需要介绍的是,在得到Decoder的隐藏层状态dt之后,如何得到当前选择的物品at。其过程在图中表示的比较清楚:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第8张图片](http://img.e-com-net.com/image/info8/bfbc096004ee4c7e9a1edf9e1758dbb1.jpg)
首先,这里借鉴pointer-network的的做法,使用一个attention机制,先让decoder回顾一遍所有的encoder输出,并得到每个输出的权重,作为当前选择的一个依据:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第9张图片](http://img.e-com-net.com/image/info8/5badc7354b3349a3bf036ae2558c1f6d.jpg)
接下来,我们要计算选择每个物品的概率,首先这里需要注意的一点是,Encoder每个阶段的输出组合起来,应该是图中的一个完全子图,因此,要确保当前选择的物品能够与之前选择的物品在同一个完全子图中,如果不能满足这个条件,需要通过添加mask的方式,确保其不会被选择到:


介绍完模型结构,接下来咱们介绍模型如何训练。
3、模型训练
3.1 整体思路
先说说整体的思路,首先我们的优化目标是整个一屏的推荐结果集合A的点击概率最高,但按照监督学习的思路的话,由于Decoder阶段使用的是RNN的结构,我们只能计算每个阶段的交叉熵损失或者平方损失,因此网络的优化目标和实际想要的目标是存在一定的gap的。因此,考虑通过强化学习中policy-gradient的思路。但是直接使用policy-gradient的方法,其训练周期是十分长的,前面的探索效率可能无法得到有效的保证。
综上所述,本文中采取的思路是,首先通过监督学习的方式对网络参数进行一定的预训练,然后再通过策略梯度的方式进一步修正网络参数。使用监督学习文中称作Learning from Demonstrations,使用强化学习称作Learning from Rewards.
3.2 Learning from Demonstrations
我们可以从历史日志中收集一批真实的训练数据:

通过交叉熵损失训练模型:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第10张图片](http://img.e-com-net.com/image/info8/283668949d9448ec95bed4d0bbfa5f9e.jpg)
使用上面的式子存在的一个问题就是,训练阶段时,Decoder输入的是真实的物品,而在预测时,Decoder输入的是上一阶段输出的物品,这就容易导致一步错步步错的问题,因此文中说在训练阶段时,Decoder输入也直接使用上一阶段输出的物品。因此损失变为:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第11张图片](http://img.e-com-net.com/image/info8/421799dcc47942b39387a69efb552628.jpg)
两种方式还是都训练看看吧,个人经验来看也许第一种会好一些。
3.3 Learning from Rewards
这里,把f(S,u;θe)作为状态state的话,decoder阶段输出的组合A可以看作动作action,我们需要一个仿真环境来计算state和action对应的reward,直接使用历史数据的话显然是不够的,因为大量的(state,action)组合没有出现过。因此借鉴反向强化学习(Inverse Reinforcement Learning)的思路,来训练一个奖励估计器(Reward Estimator)。该估计器也好训练,即基于历史数据来训练一个二分类模型(这里使用的是PNN模型),损失是logloss:
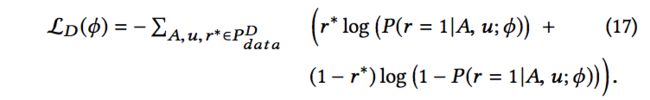
有了奖励估计器,就可以通过策略梯度方法训练网络:
![RS Meet DL(57)-[阿里]如何精确推荐一屏物品?_第12张图片](http://img.e-com-net.com/image/info8/55f6235105324902aa8e75f47bcdc058.jpg)
而奖励需要归一化到-1到1之间:

这里文中还提到了一点是,由于训练二分类模型时正负样本十分不均衡,正样本偏少,这样也会导致我们很难收到正向的reward,因此论文中借鉴了爬山法的思想,每次保存5个结果,并从这五个结果中选择能获得最大奖励的一个结果进行模型训练。
3.4 Combination
结合两种训练方式,模型的最终loss为:
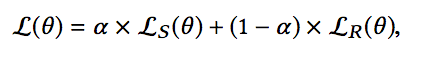
这里的参数a在[0,1]之间,并且是随着训练的进程进行调整的。训练初期,将a设置为一个较大的数,使得监督学习占据比较大的权重,便于模型的快速收敛,随后a慢慢变小,逐渐向强化学习方式偏移,对参数进行调整,这样往往可以得到一个比较不错的结果。
4、总结
这里,实验结果部分就不介绍了,整个论文的思路还是比较完整的。可以借鉴的有以下几点吧(个人理解):
1)为整屏推荐提供了一种解决思路。
2)训练过程整合了监督学习和强化学习的思路,相当于使用监督学习进行预训练,再使用强化学习进行参数调整。使用监督学习加速训练过程,使用强化学习使得训练和测试目标保持一致。
3)模型选择结合业务思考,比如encoder的选择,选择Transformer是因为输入之间没有顺序关系,但相互之间还存在一定的影响。
4)为了提升推荐结果的多样性(或者其他目标),将其转换为一个求完全子图的问题,并通过在decoder阶段加入mask的方式对输出进行限制。
感觉这篇文章还是有一定难度的,自己可能有些地方也总结的不太到位,对论文感兴趣的小伙伴可以看下原文,与小编一起讨论!
