说话人概述
技术专题】说话人识别(Speaker Verification)综述
Posted on 2018-07-10 | In Speaker Verification | | Visitors: 404
Words count in article: 4.3k | Reading time ≈ 16
技术介绍
技术应用
声纹识别(speaker verification),也称做说话人识别,是一种通过采集语音片段识别说话人身份(speaker ID)的技术。我们以前给朋友打家庭电话,朋友的家人一声“喂”,我们很容易就知道是不是朋友本人接听了。细心留意的同学还可以发现,微信有个语音解锁功能,账户主人读57386941即可解锁。虽然屏幕上显示是57386941,但是很多网友表示随意念12345678,甚至念两句诗也可以通过验证。这也说明了这技术背后用的不是ASR(自动语音识别),而是声纹识别技术。

在正常发音的情况下,每个人的声道、口腔和鼻腔都是有明显差异的,表现在声音上的差异还是很容易被人耳捕捉。不过,声纹信息在个体上的差异并没有指纹和人脸那样具有显著差异,还可以被模仿,安全性相对指纹和人脸来说略低一点。尽管如此,声纹一种生物信息,广泛应用于身份鉴定系统中。近来,声纹识别和语音合成相结合,还可以应用中跨语种的语音合成中,这项技术会在其他文章中详细介绍。
算法流程
本节将介绍典型的说话人身份识别系统的流程图,如下图所示。为了让计算机认识一个用户,我们需要先录制目标用户的声音,经过人工提取特征或者神经网络的学习,训练得到一个或多个向量存储在我们的模型库中。这属于说话人身份识别系统的前期工作。在使用的时候,当我们遇到一个未知个体,先采用同样的方法提取特征,然后和模板库中的所有candidates比较相似程度。相似程度最高的candidate信息为该个体最有可能的身份信息。识别系统性能好坏,关键就在于算法能否有效挑出个体差异信息,以及从模板库中搜索的复杂度。

技术原理
近两年来,基于深度学习的声纹识别取得了良好的进展,有很多state-of-art的模型颠覆了传统的算法。尽管如此,本文还是有必要先介绍一些传统的算法,从中学习一些可借鉴的地方。本文介绍的算法包括GMM-UBM框架及其改进,以及一些深度学习算法。
| 类型 | 主要算法 |
|---|---|
| 文本无关 | GMM-UBM(2000) GMM-SVM(2006) JFA(2007) i-vector/PLDA(2011) DNN i-vector(2014) Deep Embedding(2017) |
| 文本相关 | GMM-UBM HMM-UBM TMM-UBM i-vector DNN-ivector |
GMM-UBM框架
基于高斯模型的方法包括单高斯模型(SGM, Single Gaussian Gaussian Model)和高斯混合模型(GMM, Gaussian Mix Model),GMM-UBM是对GMM的一种改进,解决了训练数据场景下GMM的缺陷。
SGM
(1)当一个一维向量X
服从高斯分布时,它的概率密度函数PDF定义为:
N(x;μ,σ2)=1(2πσ2)1/2exp[−12σ2(x−μ)2](1.1)
这里,μ
表示均值,σ2
表示方差。
(2)当一个多维向量X
服从高斯分布时,它的概率密度函数PDF定义为:
N(x;μ,Σ)=1(2π)D/21(|Σ|)1/2exp[−12(x−μ)TΣ−1(x−μ)]
这里,μ
表示均值,Σ表示D∗D的协方差矩阵,|Σ|
为该协方差的行列式的值。
GMM
单高斯分布模型在二维空间上近似于椭圆形,在三维空间上近似于椭球形。GMM(高斯混合模型),顾名思义,它是将多个单高斯的pdf函数加权求和来拟合更加复杂的空间分布的pdf函数。
假设GMM模型由K个SGM组成,每个SGM称为一个component,这些component的线性加权在一起就组成了GMM的概率密度函数。
p(x)=∑k=1Kp(k)p(x|k)=∑k=1KπkN(x|μx,Σk)
这里,
- πk
- 表示第k个component的概率,或权重;
- μk
- 表示第k个component的均值;
- σk
- 第k个component的方差;
- 每个SGM component 表示为Nk∼(μk,θk),k=1,2,3,4,…K
- ,分布对应一个聚类中心,每个聚类中心的坐标可以看成是(μk,θk),对于一个样本xi,它属于第k个聚类中心的可能性为πk,πk∼(0,1)
- 。
GMM模型的参数训练,通常使用最大似然估计MLE或者最大后验概率MAP即可完成。这在其他文章中已经有了详细介绍,本文此处不再展开讨论。
通常情况下,在数据充足的情况下,多个高斯概率分布的线性组合可以平滑地逼近任意形状的pdf函数,并且是一个易于处理的参数模型,具备对实际数据极强的表征力。GMM模型的明显缺缺陷在于:参数规模会随着模型复杂度等比例的膨胀,需要更多的数据来驱动GMM的参数训练才能得到一个更加general(或称泛化)的GMM模型。
假设对维度为50的声学特征进行建模,GMM包含1024个component,并简化多维高斯的协方差为对角矩阵,则一个GMM待估参数总量为1024(权重$\pi$参数个数)+1024×50(均值$\mu$参数个数)+1024×50(协方差$\sigma$参数个数)=103424,超过10万个参数要估计,均值和协方差的参数了都接近50%。
GMM-UBM
现实中,每一个说话人的语音数据比较有限,难以训练出高效的GMM模型。另外,由于多通道的问题,训练GMM模型的语音与测试语音存在不匹配的情况,这些因素都会降低GMM声纹识别系统的性能。DA Reynolds团队提出了通用背景模型(UBM,Universal Background Model),先采集大量与说话人无关的语音特征训练一个UBM,然后使用少量的说话人数据,通过自适应算法(如最大后验概率MAP、最大似然线性回归MLLR等)突出了说话人的个性特征,得到目标说话人模型。
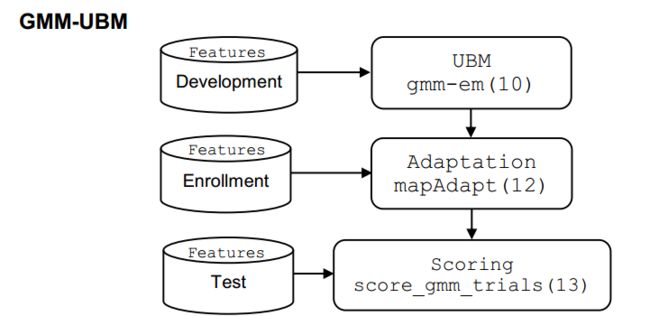
GMM-UBM本质上是一种自适应的思想,也是深度学习领域的fine turning思想。既然我们无法获取目标人大量的数据,那么我们可以先用大量的数据构建一个大型的通用GMM模型空间(均值模型),再用目标人的语音特征去自适应的时候,也突出了目标人模型和通用模型的差异,建模效果显著提升。和特征人语音合成类似,先训练一个多人的均值模型,然后再用目标人的数据去fine turning,可以更好地学习到韵律信息。GMM-UBM模型最重要的优势就是通过MAP算法对模型参数进行估计,避免了过拟合的发生,同时我们不必调整目标用户GMM的所有参数(权重,均值,方差)只需要对各个component的均值参数进行估计,就能实现最好的识别性能。显然,这种做法可以使得参数减少大约一半,越少的参数也意味着更快的收敛,不需要那么多的目标用户数据即可模型的良好训练。训练流程图如下所示:
Step 1: Feature Extraction 使用HTK工具提取HMM特征。 Step 2: 训练 Development: Training the UBM 使用EM算法训练UBM模型,其实就是对一个使用包含大量说话人语音数据的训练集训练GMM。 Step 3: 注册 Adaptation mpaAdapt 使用目标人的语音数据,使用MLE或MAP来重新估计均值,得到新的目标人GMM模型。 Step 4: 评估 Scoring score_gmm_trials 特征和模型都建立好了,用一个对数似然比的评价指标。 用测试数据分别与模型和UBM进行似然度比评价测试数据到底和模型更接近还是和UBM最接近。 最后设定一个阀值,用来进行最后的分类判断。
GMM-SVM
在GMM-UBM模型中,在自适应环节只是对UBM模型在目标人数据上做了均值的自适应。GMM-UBM算法可以解决目标人数据不足导致的建模效果太差的问题,但是不能消除由信道干扰导致的说话人信息的扰动。换句话说,你用iPhone手机在云端注册模型,换个小米手机拿来做识别就不通过了。这是因为声音是通过录音设备进行采集的,不同的型号的录音设备对语音都会造成一定程度上的畸变,同时由于背景环境和传输信道等的差异,对语音信息也会造成不同程度的损伤。
WM Campbell将支持向量机(SVM, Support Vector Machine)引入了GMM-UBM的建模中,通过将GMM每个component的均值提取出来构建一个高斯超向量(GSV, Gaussian Super Vector)作为SVM的样本,利用SVM核函数的强大非线性分类能力,在原始GMM-UBM的基础上大幅提升了识别的性能,同时基于GSV的一些规整算法,例如扰动属性投影(NAP, Nuisance Attribute Projection),类内方差规整(WCCN, Within Class Covariance Normalization,WCCN)等,都在一定程度上补偿了由于信道易变形对声纹建模带来的影响,这里不做多过展开。
JFA
在GMM-UBM的实际应用过程中,假如用户录制了5min的语音,去掉停顿和静音,只剩下有效长度三分钟左右了。从音频长度来说是很少,但是还是难以用在产品的,可以想象让用户录制五分钟的音频才能完成识别是一种多么糟糕的体验。另外,即使用了五分钟的音频,也往往只能调整部分component的均值,一些没有调整到的component只能保持原状,降低了模型的表达能力。
为了解决GMM-UBM待估参数过多的问题,学者提出了一种只用少量的参数就能控制GMM中所有component变化的思路,称为因子分析(Factor Analysis,FA)。在FA算法框架中,只用数百个基向量的线性组合就足够能表征所有GSV的变化了,这种思想和主成分分析(PCA, Principal components analysis)类似,也是一种降维的思想。这种降维的思想已经被广泛应用于图像,语音和数据的压缩技术中。因为真实数据总是带着相当多的冗余信息,我们可以做到只损失一小部分精度,甚至不损失精度,就能实现数据的压缩与降维。
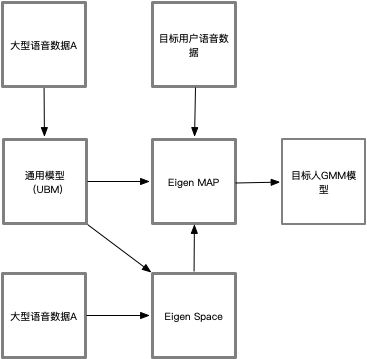
为了解决GMM-UBM模型不抗信道干扰的问题,数学顶级大师Kenny提出了一种联合因子分析方法(JFA, Joint Factor Analysis)。在JFA中,GMM-UBM系统中的高斯模型均值supervector由两部分的叠加,一部分是跟说话人本身有关的向量特征,另一部分是跟信道和其他变化有关的向量特征。也就是说,将说话人GMM均值GSV所在的空间划分为本征空间、信道空间和残差空间。联合因子分析的思路是抽取跟说话人相关的特征而去掉和信道相关的特征,很好地克服了信道的影响,系统的性能得到了明显提高。JFA在05之后的NIST声纹比赛中以绝对的优势成为了性能最优的识别系统。
i-vector
JFA比较理想化地做了特征音空间与特征信道空间的独立假设,但是在现实世界中,数据之间都是具有相关性的,绝对的独立同分布是一个过于强的假设。这种独立同分布的假设虽然为数学推导提供了便利,但也限制了模型的泛化能力。
回忆一下JFA的核心思想:同一个说话人,不管怎么采集语音,采集了多少段语音,在特征音子空间上的参数映射都应该是相同的;而最终的GMM模型参数之所以有差别,都是特征信道子空间不同导致的,特征音子空间和特征信道子空间互相独立。但是这样的假设在现实中是不成立的。
2009年,Kenny的学生N.Dehak提出了一个更加宽松的假设:既然声纹信息与信道信息不能做到完全独立,那就用一个超向量子空间同时描述说话人信息和信道信息。这时候,同一个说话人,不管怎么采集语音,采集了多少段语音,在这个子空间上的映射坐标都会有差异,这也更符合实际的情况。这个即模拟说话人差异性又模拟信道差异性的空间称为全因子空间(Total Factor Matrix),每段语音在这个空间上的映射坐标称作身份向量(Identity Vector, i-vector),i-vector向量通常维度也不会太高,一般在400-600左右。
回忆一下整个基于GMM的说话人识别算法的发展,从最初95年采用的32个component的GMM,到1024、2048、甚至4096,发展的到ivector,只需要400×1的向量就够了。i-vector是如此的简洁优雅,它的出现使得说话人识别的研究一下子简化抽象为了一个数值分析与数据分析的问题:任意的一段音频,不管长度怎样,内容如何,最后都会被映射为一段低维度的定长i-vector。我们只需要找到一些优化手段与测量方法,在海量数据中能够将同一个说话人的几段i-vector尽可能分类得近一些,将不同说话人的i-vector尽可能分得远一些。同时N.Dehak在实验中还发现i-vector具有良好的空间方向区分性,即便上SVM做区分,也只需要选择一个简单的余弦核就能实现非常好的区分性。截至今日,i-vector在大多数情况下仍然是文本无关声纹识别中表现性能最好的建模框架,学者们后续的改进都是基于对i-vector进行优化,包括线性区分分析(Linear Discriminant Analysis, LDA),基于概率的线性预测区分分析(probabilistic linear discriminant analysis,PLDA)甚至是度量学习(Metric Learning)等。
然而,i-vector在文本无关声纹识别上表现优秀,但是在指定文本的识别上表现确不如传统的GMM-UBM框架更好。因为i-vector简洁的背后是它舍弃了太多的东西,其中就包括了文本差异性,在文本无关识别中,因为注册和训练的语音在内容上的差异性比较大,因此我们需要抑制这种差异性;但在文本相关识别中,我们又需要放大训练和识别语音在内容上的相似性,说话人的特征相似性被冲淡了很多,显得区分能力下降。
本节主要参考 http://www.sohu.com/a/115298334_114877 来自腾讯优图
深度学习方法
updating…
Reference
- https://www.zhihu.com/question/67471632
- https://blog.csdn.net/weixin_38206214/article/details/81084456
- Lei, Yun, et al. “A novel scheme for speaker recognition using a phonetically-aware deep neural network.” Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014.
- Variani, Ehsan, et al. “Deep neural networks for small footprint text-dependent speaker verification.” Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014.
- Liu, Yuan, et al. “Deep feature for text-dependent speaker verification.” Speech Communication 73 (2015): 1-13.
- Chen, Nanxin, Yanmin Qian, and Kai Yu. “Multi-task learning for text-dependent speaker verification.” Sixteenth annual conference of the international speech communication association (INTERSPEECH). 2015.
- Heigold, Georg, et al. “End-to-end text-dependent speaker verification.” Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016.
- Zhang, Chunlei, and Kazuhito Koishida. “End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances.” Proc. Interspeech 2017 (2017): 1487-1491.
- Li, Chao, et al. “Deep Speaker: an End-to-End Neural Speaker Embedding System.” arXiv preprint arXiv:1705.02304 (2017).
- Snyder, David, et al. “Deep neural network-based speaker embeddings for end-to-end speaker verification.” Spoken Language Technology Workshop (SLT), 2016 IEEE. IEEE, 2016.
- Snyder, David, et al. “Deep Neural Network Embeddings for Text-Independent Speaker Verification.” Proc. Interspeech 2017(2017): 999-1003.
- Li, Lantian, et al. “Deep Speaker Feature Learning for Text-independent Speaker Verification.” arXiv preprint arXiv:1705.03670 (2017).
- Villalba, Jesús, Niko Brümmer, and Najim Dehak. “Tied Variational Autoencoder Backends for i-Vector Speaker Recognition.” Proc. Interspeech 2017 (2017): 1004-1008.
- https://blog.csdn.net/jinping_shi/article/details/59613054
- https://wsstriving.github.io/2016/04/28/Code-Based-GMM-UBM-Tutorial/
- http://www.sohu.com/a/115298334_114877
- [1] http://www.itl.nist.gov/iad/mig/tests/spk/
- Larcher, Anthony, et al. “RSR2015: Database for Text-Dependent Speaker Verification using Multiple Pass-Phrases.” INTERSPEECH. 2012.
- Fu Tianfan, et al. “Tandem deep features for text-dependent speaker verification.” INTERSPEECH. 2014.
- Vasilakakis, Vasileios, Sandro Cumani, and Pietro Laface. “Speaker recognition by means of deep belief networks.” (2013).
- Kenny, Patrick. “Joint factor analysis of speaker and session variability: Theory and algorithms.” CRIM, Montreal,(Report) CRIM-06/08-13 (2005).
- Dehak, Najim, et al. “Front-end factor analysis for speaker verification.” IEEE Transactions on Audio, Speech, and Language Processing 19.4 (2011): 788-798.
- 转载地址https://auzxb.tech/2018/07/Speaker-Verification-Overview