端智能系列文章|端侧如何实现实时CEP引擎
背景
用户来闲鱼,主要是为了获得自己关心的内容。随着闲鱼的体量越来越大,内容也变得越来越丰富。闲鱼基于用户画像,可以将用户关心的内容推送给用户。具体在哪些场景下才需要触发推送?我们定义了很多触发规则,包括停留时长、点击路径等。
起初我们把触发规则的逻辑放在服务端(Blink)运行。但实践下来发现Blink存在诸多限制:
服务端要对客户端埋点进行数据清洗,考虑到闲鱼的DAU已经突破2000w,这个量是非常庞大的,非常消耗服务端资源;
Blink的策略是实时执行的,同样因为资源问题,现在只能同时上线十几个策略。
如何解决这些问题呢,我们开始考虑能否将Blink的策略跑在客户端!
CEP模型
Blink,作为是Flink的一个分支,最初是阿里巴巴内部创建的,针对Flink进行了改进,所以我们这里还是围绕Flink讨论。CEP(Complex Event Process)是Flink中的一个子库,用来快速检测无尽数据流中的复杂模式。
Flink CEP
Flink的CEP的核心是NFA(Non-determined Finite Automaton),全称叫不确定的有限状态机。提到NFA,就不得不提Jagrati Agrawal等撰写的关于NFA模型的论文《Efficient Pattern Matching over Event Streams》,本篇论文中描述了NFA的匹配原理。
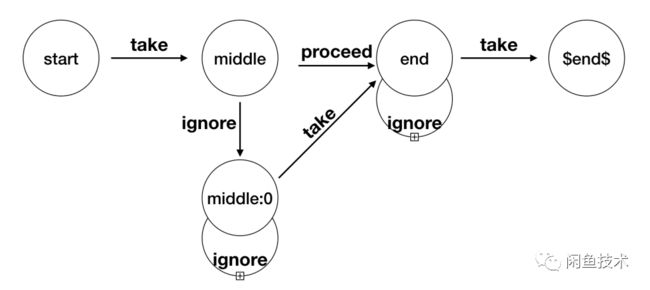
上面这张图,就是一个不确定的有限状态机,它由状态(State)还有之间的连线(StateTransition)组成的。
状态(State):状态是根据flink脚本里面的代码来决定的,最终会有一个
$end$的Final状态转换(StateTransition):State的转换条件,包括
take/proceed/ignore
不同的条件,代表的含义不同:
take: 满足条件,获取当前元素,进入下一状态proceed:不论是否满足条件,不获取当前元素,直接进入下状态(如optional)并进行判断是否满足条件。ignore:不满足条件,忽略,进入下一状态。
我们只要在端上实现这样一个状态机,就可以实现一个CEP引擎。
Python CEP
对于客户端来说,首先要解决的问题是如何构建一个CEP环境。经过调研,可以复用集团的端智能容器(Walle),作为Python容器可以执行cep的策略。
在构建NFA之前,首先要解决的一个问题是数据来源,手淘信息流团队有一套完整的解决方案BehaviX/BehaviR,可以对UT埋点进行结构化,能很好的结合Walle容器来触发策略。有了事件来源,还需要解决的是Python脚本如何执行。Walle平台可以将多个Python脚本打包下载并执行,因此,我们可以将CEP封装成一个Python的库,然后跟策略脚本一起下发。
最终的整体架构设计如下图所示:
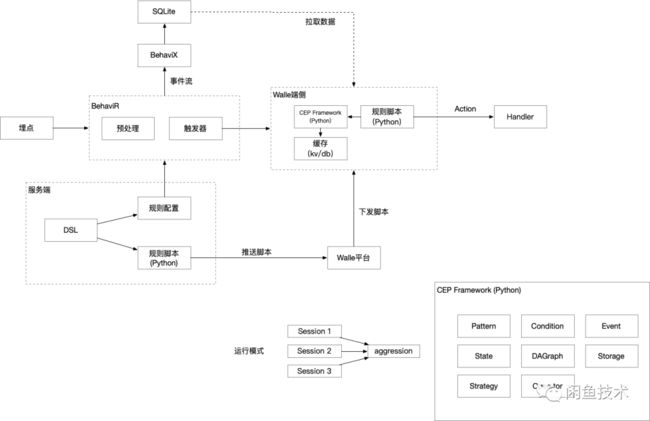
本文重点介绍下如何用Python来实现一个CEP的编译器,这个编译器主要用来将CEP的描述语言转换成为NFA。
编译器原理
在Flink中,java侧会有一套完善的API来编写一个策略脚本,《efficient Pattern Matching over Event Streams》论文中还定义了一套完备的DSL描述语言,也是会转化成java文件去调用这些API去完成匹配。那么接下来会重点讨论,flink是如何将上述API转化成NFA去匹配,以及Python CEP如何实现上述一套完整API接口。
Pattern
在Flink里面,是通过 Pattern来构建这个NFA,首先用它描述这个不确定性状态机。首先是构建一个 Pattern的一个链表,得到这个链表之后,会将每个Pattern映射成为 State的图,点与点之间会通过 StateTransition来连接。以下面的Python代码为例,看下如何API是如何工作的:
例如,需要创建这样一个规则,描述如下:
以start事件开始,后续跟随一个middle的事件,后面紧跟着一个end事件作为结尾
用Pattern编写如下所示:
Pattern.begin("start").where(SimpleCondition())\
.followed_by('middle').where(SimpleCondition())\
.next_('end').where(SimpleCondition())
这个代码里面声明了3个Pattern,依次命名为 start、 middle、 end。Pattern里面保存了指向前面节点的引用 previous,整个Pattern链表构建完如下图所示:
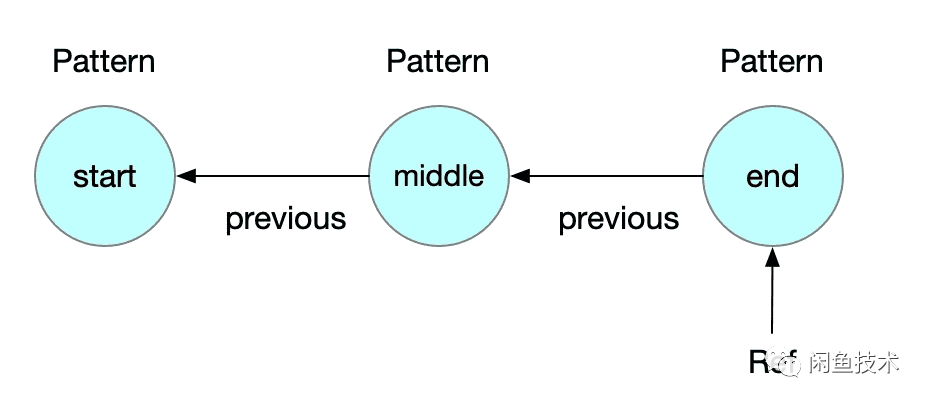
最终拿到的是 end节点的一个引用 Ref,Pattern中会有一个变量指向前一个节点,这样就可以得到一个Pattern的反向链表。
Pattern的对外接口定义如下:
classPattern:
# 静态方法,用来生成起始的pattern
@staticmethod
def begin(self, name):
pass
# 标记紧接着的事件
def followed_by(self, name):
pass
# 标记不需要紧跟的事件
def not_followed_by(self, name):
pass
# 标记紧跟的事件
def next_(self, name):
pass
# 标记事件循环次数
def times(self, times):
pass
# 标记当前事件触发的条件
def where(self, condition):
pass
# 标记当前事件的and条件
def and_(self, condition):
pass
# 标记当前事件的or条件
def or_(self, condition):
pass
# 用于聚合
def group_by(self, fields):
pass
# 用于聚合,渠道特定字段的值
def fields(self, key_by_state_name, field):
pass
# 用于聚合,统计事件具体的数量
def count(self, field, condition):
pass
不同接口会生成不同的消费策略的节点,具体细节可以参考 StateTransition。有了Pattern链表,接下来就需要编译器(Compiler)了,它主要是将Pattern链表转化成NFA图,首先来看下NFA的2个核心组件:State和 StateTransition。
State
结构定义如下:
classState(object):
def __init__(self, name, state_type):
self.__name = name # 节点的名称,同Pattern的名称
self.__state_type = state_type # 节点的类型:Start/Normal/Stop/Final
self.__state_transitions = [] # 到其他节点的边
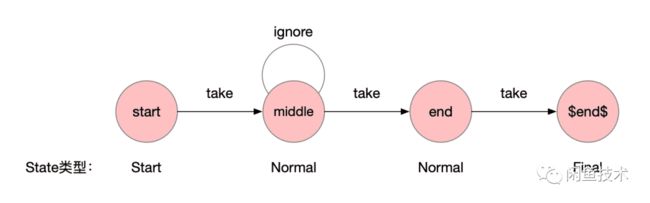
State一共有4种类型:Start/Final/Normal/Stop。
生成NFA的过程就是将反向解析Pattern链表的过程,大概的过程如下:
创建一个
$end$的结束节点(Final)再从后往前创建每个state节点,作为中间节点(
Normal/Stop)最后创建一个开始节点(
Start)
State的名称就是Pattern的节点名称,创建完成之后如下图所示。
Transition
State代表了当前状态机的状态,不同状态之前的切换定义成 StateTransition。
结构定义如下:
classStateTransition:
def __init__(self, source_state, action, target_state, condition):
self.__source_state = source_state # 开始的State节点
self.__action = action # 具体action类型:take/ignore/proceed
self.__target_state = target_state # 结束的State节点
self.__condition = condition # 节点之间的判断条件
边的生成逻辑跟Pattern的事件消费策略相关,以下是事件消费策略:
classConsumingStrategy:
STRICT = 0# 严格匹配下个
SKIP_TILL_NEXT = 1# 跳过下一个
SKIP_TILL_ANY = 2# 跳过任意一个
NOT_FOLLOW = 3# 非跟随模式
NOT_NEXT = 4# 非紧邻模式
不同的消费策略,得到的状态机如下图所示:
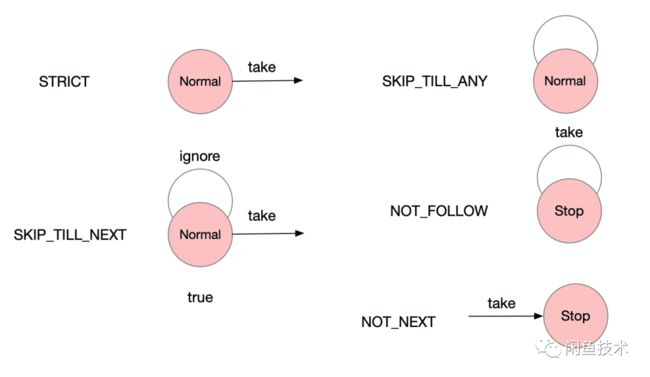
STRICT: 如果命中了事件了,会进到下个状态SKIP_TILL_NEXT: 如果命中了会进入下一个状态,否则会再当前节点循环,进入ignore的边SKIP_TILL_ANY: 不管是否命中条件,都会一直在当前状态循环NOT_FOLLOW: 如果遇到了一个匹配的,就会进入Stop状态NOT_NEXT: 如果命中一条,则进入Stop状态
在Pattern中,不同的接口会创建出不同的消费策略节点,例如 followed_by接口会创建 SKIP_TILL_NEXT的节点。
Times
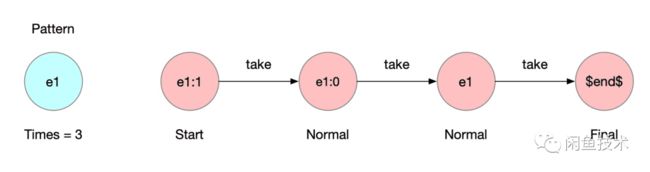
如果有的规则,要求特定的事件,循环出现几次,那现在就要用到times接口。比如浏览3次宝贝这个规则,规则就可以写成:
Pattern.begin('e1').where(SimpleCondition()).times(3);
最终就会得到一个 Times=3的Pattern,编译器在拿到这个Pattern之后,一样先创建一个$end$的Final节点,在处理times的时候,会创建重复的节点,只不过名称不同,不同的点之间用take链接起来,如下图所示:
Python CEP聚合
Flink是通过InputStream将匹配的事件转移给CEPOperator,执行聚合操作;但是在客户端的聚合,一次执行就一个事件流,所以可以将聚合简化到一次匹配过程中,因此我们对于Flink的聚合操作做了改造,使其更适合端上的场景。
那么聚合的脚本写法如下:
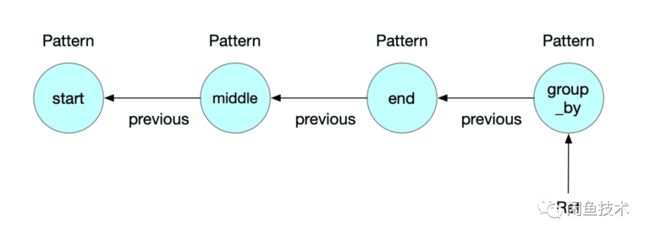
_pattern = Pattern.begin("start").where(self.start_filter)\
.followed_by('middle').where(SimpleCondition())\
.next_('end').where(self.end_filter)\
.group_by('group_by').fields('start', 'userId')
这里声明了,以 start节点中的 userId作为聚合的节点,我们就会得到如下的 Pattern链表:
在解析 group_by节点的时候,我们需要做个特殊处理,判断如果有聚合节点,我们就需要再 $end$节点和前面节点之间插入一个聚合的节点和哨兵位节点,哨兵位节点命名为 $aggregationStartState$,最终效果如下图所示:
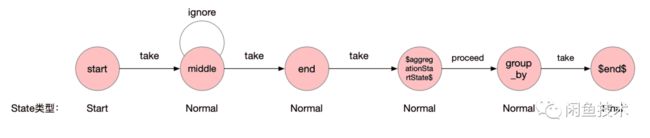
在NFA匹配的过程中,当匹配结束,就可以将匹配到的事件流,传到聚合节点,再进一步聚合。$aggregationStartState$节点和 group_by节点之间,是通过proceed结合,不需要满足特定条件就可以执行。
具体的实现过程如下,可见与Flink不同的是,我们创建了一个特殊的 State节点 AggregationState:
# 创建聚合节点
def __create_aggregation_state(self, sink_state):
# 渠道聚合节点的condition
_aggregation_condition = self.__current_pattern.get_aggregation_condition()
# 创建AggregationState
not_next = AggregationState(
self.__current_pattern.get_name(),
StateType.Normal,
_aggregation_condition.get_key_by_state_name(),
_aggregation_condition.get_field())
self.__states.append(not_next)
# 获取take的条件
take_condition = self.__get_take_condition(self.__current_pattern)
not_next.add_take(sink_state, take_condition)
# 将游标指向上一个节点
self.__following_pattern = self.__current_pattern
self.__current_pattern = self.__current_pattern.get_previous()
return not_nex
Show me the code
讲了太多原理的东西,接下来看下代码里面如何工作的,先来看下如何来编写一个CEP策略。
策略脚本
现在看下如何写一个完整的python版本的cep规则,以宝贝详情页为例,规则描述如下:
需要匹配用户查看3次宝贝详情页
那规则的写法如下:
# 1. 创建用来匹配的Pattern
_pattern = Pattern.begin('e1').where(KVCondition('scene', 'Page_xyItemDetail')).times(3)
# 2. 将需要匹配的事件流_batch_data和待匹配的Pattern
# CEP内部会先将pattern转化成NFA,然后再用NFA去匹配事件流
_cep = CEP.pattern(_batch_data['eventSeq'], _pattern)
# 用来选择的逻辑
def select_function(data):
pass
# 3. 匹配完成,通过cep的select接口查询匹配到的结果
self.result = _cep.select(select_function)
在 CEP.pattern()函数里面,会先创建 NFA,然后去进行匹配,可见整个匹配策略脚本非常的短小精悍。
生成NFA
如下代码用来将 Pattern链表转化成 NFA图:
# 最后一个Pattern节点不允许是NotFollowedBy
if self.__current_pattern.get_quantifier().get_consuming_strategy() == ConsumingStrategy.NOT_FOLLOW:
raiseException('NotFollowedBy is not supported as a last part of a Pattern!')
# 校验Pattern的名称,必须唯一
self.__check_pattern_name_uniqueness()
# 校验Pattern的策略
self.__check_pattern_skip_strategy()
# 首先创建Final节点
sink_state = self.__create_ending_state()
# 判定是否有聚合节点
if self.__current_pattern.get_aggregation_condition() isnotNone:
# 首先创建聚合节点
sink_state = self.__create_aggregation_state(sink_state)
# 然后创建聚合几点的起始节点
sink_state = self.__create_aggregation_start_state(sink_state)
# 创建状态机中的中间节点,此函数会循环知道Start节点的Pattern
sink_state = self.__create_middle_states(sink_state)
# 最后创建Start节点
self.__create_start_state(sink_state)
# 根据state列表和window来创建NFA
return NFA(self.__states, self.__window_time, False)
效果
闲鱼已经上了几个策略,整体看来比较稳定,不过还有很多优化的空间。从实测效果来看,端侧从触发策略到执行Action用时不会超过1s,其中还包含了一次网络请求的时间。
性能数据
执行时间
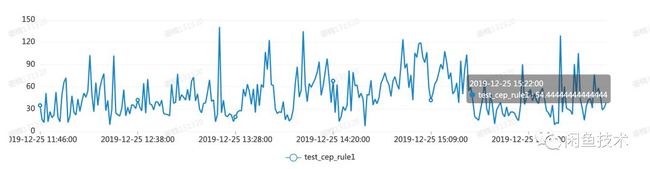
单个脚本,执行时间大概在100ms左右。
内存使用
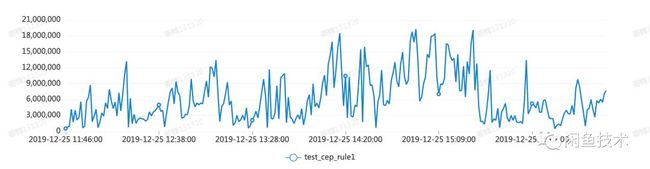
现在内存使用峰值还是比较高,大概在15M左右。关于内存过大的问题,目前正在讨论一个方案:Python CEP可以持久化当前NFA的状态,然后再触发策略的时候,只带从未触发过的事件流,避免很多重复计算。之前运行一次脚本要处理500个事件,现在可能就缩减到100之内,可以极大的减小内存消耗。同时带来另外一个问题,就是执行脚本的都会有一个IO操作,耗时会增加。
Flink与客户端对比
现在对于Flink和客户端Python CEP做一个简单的对比:
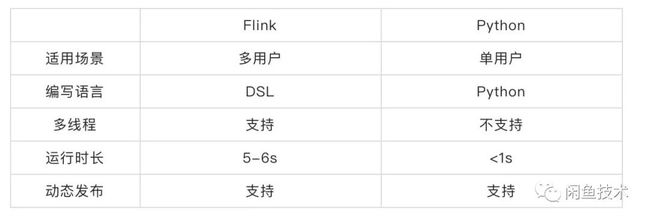
相比Flink,端侧CEP还是有它的优势,在端侧可以直接利用客户端的埋点信息进行计算,运行时长缩减了80%,而且也支持动态发布。Python脚本支持2端通投,在保证2端埋点一致的前提下,也极大的减少了维护成本。
未来
现在端计算还存在很多待优化的地方:
端计算是用Python实现,无法做到像Flink的状态机常驻内存,每次都要重新创建匹配,带来了额外的消耗
在事件流的清洗上面,现在是通过回朔拿到之前的事件流,存在大量的重复计算,后续可以借鉴Flink的Window机制来进行优化。
目前编译器暂时还不支持Group Pattern,后续还要对其进行扩展。
Python脚本现在还是需要手动编写,后续还可以考虑通过DSL来自动生成。
整体看来,Python脚本执行策略还是有一定的性能损耗,不管是在创建NFA或者是匹配过程,后续可以考虑将匹配引擎用C++实现,然后真正做到常驻内存,从而做到高效的执行效率。后期做到NFA持久化之后,C++也可以复用整套持久化协议,从而优化整个引擎的执行效率。除此之外,策略在执行的过程中,还可以考虑用TensorFlowLite优化参数策略参数,从而真正做到千人前面的策略。
参考文档
对于Flink的理解
CEP in Flink(1) - CEP规则解析
https://flink.apache.org/
《Efficient Pattern Matching over Event Streams》
https://github.com/apache/flink 1
闲鱼团队是Flutter+Dart FaaS前后端一体化新技术的行业领军者,就是现在!客户端/服务端java/架构/前端/质量工程师面向社会招聘,base杭州阿里巴巴西溪园区,一起做有创想空间的社区产品、做深度顶级的开源项目,一起拓展技术边界成就极致!
*投喂简历给小闲鱼→[email protected]


开源项目、峰会直击、关键洞察、深度解读
请认准闲鱼技术