反反爬虫之--爬取大众点评--店铺名称、详址、经纬度、评价人数、平均消费等信息
every blog every motto: Let’s be loyal to our ideals, let’s face reality-Chegwara
前言:
知难不难!
折腾了几天爬取大众点评的数据,在这顺便总结一下,重新整理一下思路。希望能帮助那个此时正在奋斗的你,你并不是一个人在战斗!
环境: python3.7 + ubuntu16.04(window也可以)
库: requests、正则表达式等
所需知识: python基础语法、requests、正则
状态: 本博文已基本完善,不出意外,后续不再更新 。2019.4.14.15:28
正文
一、文字阐述
现在大众点评采取了css反爬机制,爬取难度越来越大。目前只有店铺名是明文(如图一)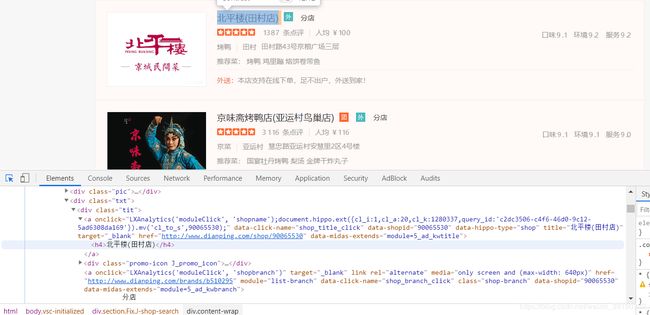 ·---------------------------------------------------------------图一
·---------------------------------------------------------------图一
像详细地址等信息都是加密(如图二),如果直接爬取,我们会发现爬取的信息都是缺胳膊断腿的。比如,“广”字,它是被span标签所替代了。当我们点击span的标签会发现一个url(如图二3)以及一个坐标(如图二4)这都是我们解密的关键!
---------------------------------------------------------图二
戏说解密 :我们知道一个网页是由无数个“块”组成,那大众点评又是如何隐藏信息的呢?目前大众点评是采取css反爬机制。比如一面“墙”(网页)挖了一个小洞(洞的大小刚好能显示一个字),在“墙”的后面有一张纸(上面有一些字),通过坐标(图二4)来移动纸张,使得想要的“字”出现在洞口,从而能在网页上能正常显示。(如图三)
------------------------------------------------------------图三
通过“戏说”,我们知道第一步应该获取“那张纸”(图二中的3,background-iamge),而background-image应该是css样式,保存在css中。我们打开网页源代码(谷歌浏览器,右击,倒数第二就是),如图四(注意是以.css结尾)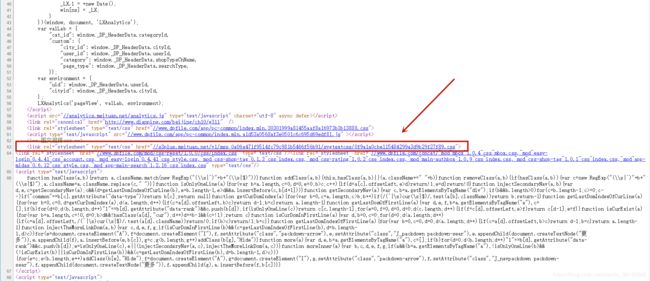
--------------------------------------------------------图四
点开css链接(如图五),我们发现有“4张纸”(4个svg_link,此处可按ctrl+F,输入background-image查看)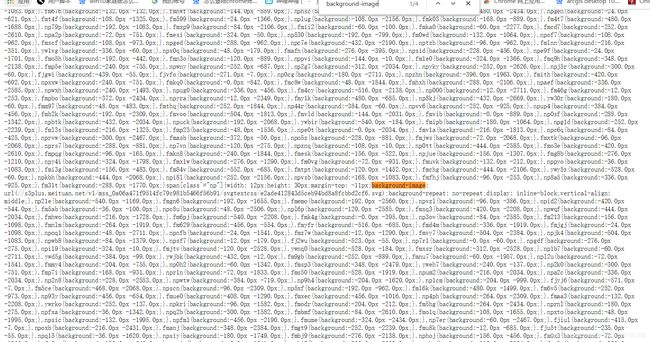
------------------------------------------------------------图五
二、代码
(为方便理解,实参和形参基本同名。此文仅展现详细地址提取,其余信息请查阅源码【结尾附】)
0.主程序
def main():
############################-------获取地址-----------#########################################
url = 'http://www.dianping.com/beijing/ch10/g311p{}'.format(num)
# 1.1 获取css样式文件
html_origin, html_css = get_css_link(url)
# 1.2 获取地址的前两个字母 地址的class=addr,传入addr
front_two_alp_addr = get_front_two_alp(html_origin, class_name='addr')
# 1.3 获取地址对应的svg链接
addr_svg_link = get_svg_link(html_css, front_two_alp_addr)
# 2. 获取html_css有关地址的(background,x,y)
font_css = get_font_css(html_css, front_two_alp_addr)
# 3.2 获取css样式对应的地址字典文件 //第二种加密方法-new-无M0
font_list = get_font_dict_by_offset_new(addr_svg_link, font_css)
# 4. 获取地址 /** 这里有一个地址字典后续要用
addr_font = get_result_font(html_origin, font_list, head_span_class_name='addr')
1.提取css_link(css链接)
# 1.1 获得css样式的链接
def get_css_link(url):
''' 获取css链接 '''
print('--->start-1.1-get_css_link--------------------------')
# 获取网页源码
html_origin = requests.get(url, headers=headers).text
# 正则表达式匹配css链接
css_link = re.search('', html_origin,
re.S)
# print(css_link.group(1))
css_link = 'http:' + css_link.group(1)
html_css = requests.get(css_link, headers=headers).text
print('==================================1.1>>>over!')
# 返回网页源码和css_link
return html_origin, html_css
2.提取svg_link
(即background_image后面的链接)
注:因为不只详细地址采用了这种方式,所以才会如前所述有4个svg_link.所以我们要先提取详细地址的部分class_name(图二5)(有时候是前三个字母一样,有时候是前两个字母一样),通过这前几个字母不仅能提取对应的svg_link,还能筛选想要的css(图五,此处接下第三步)
2.1提取前面字母
# 1.2 获取前两个字母
def get_front_two_alp(html_origin, class_name):
'''获取地址的隐藏字体的class_name 前三个字母'''
print('--->start-1.2-get_front_two_alp----------------')
# 通过一级span的class_name,取出其子标签的class_name前三个字母
front_three_alp = re.search('.*?', html_origin,
re.S)
# print('打印地址的前两个字母')
# print(front_alp_addr.group(1))
print('==================================1.2>>>over!')
# 返回地址的class_name的前三个字母
return front_three_alp.group(1)
2.2提取svg_link
# 1.3 获取svg_link
def get_svg_link(html_css, front_two_alp_addr):
# 获取的svg链接
print('--->start-1.3-get_svg_link--------------------------')
alp = front_two_alp_addr
# print(alp)
background_image_link = re.search(alp + '"]{.*?background-image: url\((//.*?svg)\)', html_css)
# print(background_image_link.group(1))
background_image_link = 'http:' + background_image_link.group(1)
print('==================================1.3>>>over!')
return background_image_link # 地址对应此链接
3.筛选有关地址的css,(background,x,y)
# 2. 筛选有关地址的css,(background,x,y)
def get_font_css(html_css, front_alp_addr):
'''获取html_css里面有关地址的(class_name,x,y)'''
print('--->start-2-get_font_css--------------------------')
font_css = re.findall('\.({0}\w\w\w)'.format(front_alp_addr) + '{background:-(\d+).0px -(\d+).0px;}', html_css,
re.S)
# print('addr_css')
# print(font_css)
print('==================================2>>>over!')
return font_css
4.获得class_name 对应的文字
注:
- 文字有两种加密方式,数字又是另一种加密方式。(大众点评会在每天下午四点到晚上九点之间更换加密方式,并且每个加密的字,的class_name(图二5)也会变,有时候是前三个字母一样,有时候是前两个字母一样[如图二5])
- 简单说一下,每一个隐藏的字由一个span标签对应(注意这里是一一对应,类似函数的映射)而span标签又是由class_name唯一确定,这里寻找class_name:font的对应关系(为保证文章的完整性,解密详细步骤放在后面)
# 3.2获得class_name 对应的文字 //第二种加密方法-new-无M0
def get_font_dict_by_offset_new(svg_link_num, food_kind_css):
'''获取坐标偏移的文字字典'''
print('--->start-3.2-get_addr_addr_dict_by_offset_new--------------')
# print(addr_css)
svg_html = requests.get(svg_link_num, headers=headers).text
# print(svg_html)
font_finded = {}
y_list = re.findall('(.*?)<', svg_html)
# print(font_finded)
offset_x = []
offset_y = []
font_list = []
for food_css_name_x_y in food_kind_css:
for y in y_list:
if int(food_css_name_x_y[2]) < int(y):
offset_x = int((int(food_css_name_x_y[1]) / 12))
# print('offset_x')
# print(offset_x)
for one_y in y_list_new:
if int(one_y[1]) == int(y):
offset_y = one_y[0]
font_list.append((food_css_name_x_y[0], font_finded[offset_y][offset_x]))
break
# print(font_list)
print('==================================3.2>>>over!')
return font_list
5.提取地址
注:
- 替换span标签为文字
- 提取文字
# 4. 提取地址
def get_result_font(html_origin, font_list, head_span_class_name):
print('--->start-4-get_addr--------------------------')
# print(font_list)
for font in font_list:
html_origin = html_origin.replace('', font[1])
# 替换成功提取地址
result_font = re.findall('(.*?)', html_origin, re.S)
# print(result_font)
print('==================================4>>>over!')
return result_font
6.成果
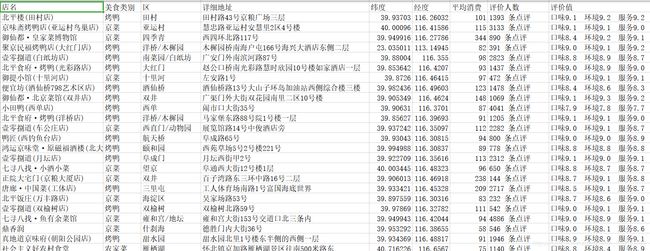
-----------------------------------------------------------------------图六
三、解密
1.第一种加密方式,解密
(为便于书写,此处图片在上,文字在下)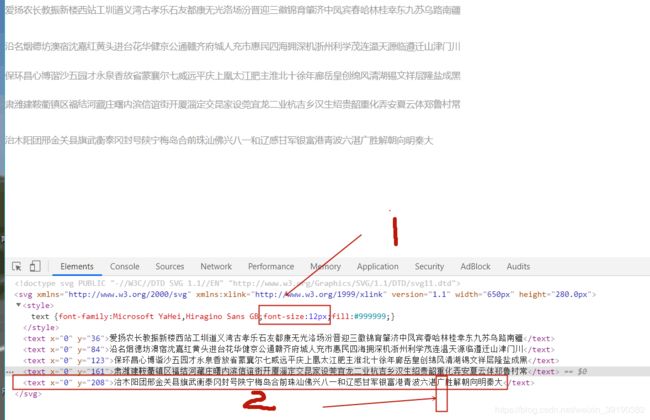
-----------------------------------------------------------图七
我们以上文提到的“广”为例(,如(图二4)background:-468px,-184px,简写如(ywbsy,468,184)【即(class_name,x__,y__),加密规则如此,不要像素前面的负号】
1.通过y__和图七的y比较,当第一个y>y__时,所要确定的文字就在那一行(此处有点难理解)例:208>184 所以对应文字在最后一行(图七2)
2.x__/12(12是文字大小,即上文提到的“洞的大小”[图七1])例 :468/12=39,数最后一行,可定位到“广”(如图七)注意:从0开始数。
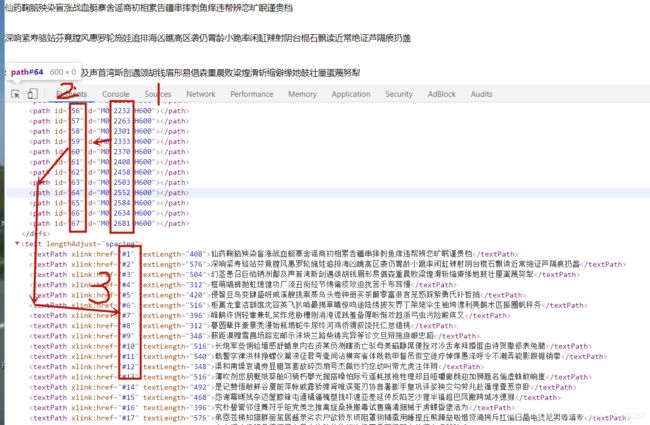
2,第二种加密方式,解密
-------------------------------------------------------图八
解密开始:
1.通过y__和M0后面的数字比较,规则和上面的相同,从而确定id的值(图八2)再通过,id==href(id和href是一一对应的,比如你确定id = 20,那么就去href=20的那一行去找),从而确定文字所在行。
2.x__ / 12 的值确定偏移量。
注:目前的两种解密方式,分两个函数来写。加密规则一变调用另一个函数即可。
四、结束语
- 目前加密规则大同小异,有的时候是偏移量加一减一的区别(是否从0开始数)
- 数字加密规则:x__/12不是整数,可以通过向下取整(也可以通过向上取整),再寻找。
- 店铺的经纬度,尚不知如何直接提取,如若有大神知道,烦请告知一二,不甚感激。
- 加密规则有两种,class_name前面字母相同个数有两种。此代码有效期不超过24小时,可调用不同函数解决。
- 源码已做部分更新,和此博文有些许出入,详情请查阅源码。
- contact by email: [email protected]
- 源码: https://github.com/onceone/dazhongspider/tree/master
参考文章:
[1] 崔庆才.Python3网络爬虫开发实战[M].北京:人民邮电出版社,2018.
[2] https://blog.csdn.net/weixin_42512684/article/details/86775357
[3] https://blog.csdn.net/sinat_32651363/article/details/85123876
[4] https://blog.csdn.net/Tilyp/article/details/88754591
[5] https://blog.csdn.net/Herishwater/article/details/89036554
[6] https://www.google.com/
[7] https://www.baidu.com/