python 爬虫 爬取网易严选全网商品价格评论数据
1.获取商品目录
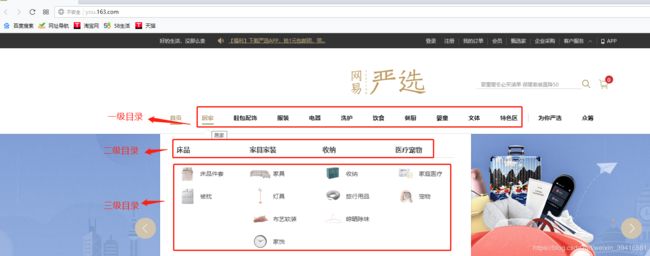
在Chrome浏览器开发者工具中,可以找到目录的JS地址:
http://you.163.com/xhr/globalinfo//queryTop.json
得到商品数据
def get_categoryList():
url='http://you.163.com/xhr/globalinfo//queryTop.json'
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'you.163.com',
'Referer':'http://you.163.com/?from=web_out_pz_baidu_1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
}
req=requests.get(url=url,headers=headers,verify=False).json()
df = pd.DataFrame(columns=('一级分类ID', '一级分类', '二级分类ID', '二级分类', '三级分类ID', '三级分类'))
x = 0
cateList=req['data']['cateList'] ##一级分类
for i in cateList:
id1 = i['id']
name1 = i['name']
subCateGroupList=i['subCateGroupList'] ##二级分类
for j in subCateGroupList:
id2 = j['id']
name2 = j['name']
categoryList=j['categoryList'] ##三级分类
for k in categoryList:
id3=k['id']
name3=k['name']
df.loc[x] = [id1,name1,id2,name2,id3,name3]
x=x+1
#df.to_csv('list.csv')
return df2.获取商品ID数据
在移动端的一级目录网址http://m.you.163.com/item/list?categoryId=1005000 的88行代码里可以找到整个目录下所有商品的数据;
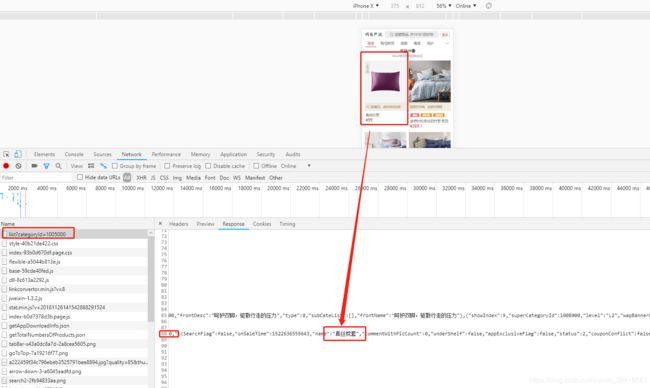
把88行的文本复制出来,去掉前面的var jsonData=,和后面的;符号,粘贴到json可视化工具里做分析(本人用的是hijson),可以找到'商品ID', '商品名称', '商品简介', '商品单位', '上架时间', '更新时间', '柜台价', '零售价', '商品URL', '商品图片'等数据

##获取商品ID数据
def get_items_ID(): ##移动端网站
s = requests.session()
df=get_categoryList()
cateList=df['一级分类ID'].values.tolist()
cateList = list(set(cateList))
df_item=pd.DataFrame(columns=('三级分类ID', '商品ID', '商品名称', '商品简介', '商品图片', '商品单位', '上架时间',
'更新时间', '柜台价', '零售价','商品URL'))
x=0
for i in cateList: ##一级分类目录商品
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'm.you.163.com',
'Referer': 'http://m.you.163.com/item/list?categoryId='+str(i),
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; MHA-AL00 Build/HUAWEIMHA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.1.4.994 Mobile Safari/537.36',
}
s.headers.update(headers)
time.sleep(1.024) ##延时
url='http://m.you.163.com/item/list?categoryId='+str(i)
req=s.get(url=url,verify=False).text
js=re.search('jsonData=(.*)',req).group(1).strip(';')
js=json.loads(js)
categoryItemList=js['categoryItemList'] ##商品清单列表
for i in categoryItemList:
category_id=i['category']['id'] ##商品三级分类ID
itemList=i['itemList'] ###三级分类下商品
for j in itemList:
id=j['id'] ##商品ID
name=j['name'] ## 商品名称
simpleDesc=j['simpleDesc'] ##商品简介
primaryPicUrl=j['primaryPicUrl'] ##商品图片
pieceUnitDesc=j['pieceUnitDesc'] ##商品单位
onSaleTime=timestamp_to_date(j['onSaleTime']) ##上架时间
updateTime=timestamp_to_date(j['updateTime']) ##更新时间
counterPrice=j['counterPrice'] ##柜台价
retailPrice=j['retailPrice'] ##零售价
itemUrl='http://you.163.com/item/detail?id='+str(id) ##商品URL
df_item.loc[x] = [category_id, id, name, simpleDesc, primaryPicUrl, pieceUnitDesc, onSaleTime,
updateTime, counterPrice, retailPrice,itemUrl]
x=x+1
#print(category_id, id, name, simpleDesc, primaryPicUrl, pieceUnitDesc, onSaleTime, updateTime, counterPrice, retailPrice)
df['三级分类ID'] = df['三级分类ID'].apply(str) ##设置列格式
#df_item.to_csv('df_item.csv', index=False, encoding="GB18030")
df_item['三级分类ID'] = df_item['三级分类ID'].apply(str) #设置列格式
items=pd.merge(df_item,df,how='left',on=['三级分类ID'])
##调整列顺序
items=items[['一级分类ID', '一级分类', '二级分类ID', '二级分类', '三级分类ID', '三级分类'
, '商品ID', '商品名称', '商品简介', '商品单位', '上架时间', '更新时间', '柜台价', '零售价',
'商品URL','商品图片']]
print(items)
items.to_csv('items.csv',index=False, encoding="GB18030")
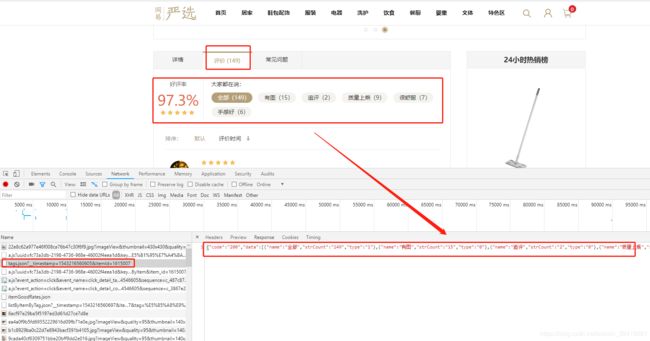
return items3.获取单个商品ID评论数及评论观点数据
在电脑端的商品页面上,打开评论,就可以在NETWORK上刷出新的JS页面http://you.163.com/xhr/comment/tags.json?__timestamp=1543216560605&itemId=1615007,
def get_comment(self,id): ##电脑端网站
#time.sleep(1.22)
now=str(int(time.time()*1000))
url='http://you.163.com/xhr/comment/tags.json?__timestamp={}&itemId={}'.format(now,id)
UserAgentlist = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 OPR/56.0.3051.104',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36 Maxthon/5.2.5.4000',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36',
]
ran = random.randint(0, len(UserAgentlist)-1)
UserAgen = UserAgentlist[ran]
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'you.163.com',
'Referer':'http://you.163.com/item/detail?id={}&_stat_referer=index&_stat_area=mod_popularItem_item_1'.format(id),
'User-Agent':UserAgen,
'X-Requested-With':'XMLHttpRequest'
}
req = requests.get(url=url, headers=headers, verify=False).text
js=json.loads(req)
data=js['data']
comment=''
goodCmtRate='0'
commentcount='0'
if data!=[]:
commentcount=data[0]['strCount'] ##评论数
url='http://you.163.com/xhr/comment/itemGoodRates.json'
postdata={'itemId': id}
itemGoodRates=requests.post(url=url, headers=headers, data=postdata,verify=False).json()
goodCmtRate=itemGoodRates['data']['goodCmtRate'] ##好评率
for i in data:
comment=str(comment)+str(i['name'])+'('+str(i['strCount'])+ ')' ##评论观点
commentdata=[commentcount,goodCmtRate,comment]
print(commentdata)
return commentdata4.获取单个商品ID的SKU数据
在移动端的商品主页面上http://m.you.163.com/item/detail?id=1516008 88行代码里可以找到SKU的数据

def get_items_data(id): ##移动端网站
url='http://m.you.163.com/item/detail?id='+str(id)
UserAgentlist = [
'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36',
'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; MHA-AL00 Build/HUAWEIMHA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.1.4.994 Mobile Safari/537.36',
'Mozilla/5.0 (Linux; Android 6.0.1; OPPO A57 Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/10.13 baiduboxapp/10.13.0.10 (Baidu; P1 6.0.1)',
'Mozilla/5.0 (iPhone 6s; CPU iPhone OS 11_4_1 like Mac OS X) AppleWebKit/604.3.5 (KHTML, like Gecko) Version/11.0 MQQBrowser/8.3.0 Mobile/15B87 Safari/604.1 MttCustomUA/2 QBWebViewType/1 WKType/1',
'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-CN; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/11.9.4.974 UWS/2.13.1.48 Mobile Safari/537.36 AliApp(DingTalk/4.5.11) com.alibaba.android.rimet/10487439 Channel/227200 language/zh-CN',
'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; BAC-AL00 Build/HUAWEIBAC-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/11.9.4.974 UWS/2.13.1.48 Mobile Safari/537.36 AliApp(DingTalk/4.5.11) com.alibaba.android.rimet/10487439 Channel/227200 language/zh-CN',
'Mozilla/5.0 (iPhone; CPU iPhone OS 10_2 like Mac OS X) AppleWebKit/602.3.12 (KHTML, like Gecko) Mobile/14C92 MicroMessenger/6.5.16 NetType/WIFI Language/zh_CN'
]
ran = random.randint(0, len(UserAgentlist)-1)
UserAgen = UserAgentlist[ran]
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'m.you.163.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':UserAgen,
}
req=requests.get(url=url,headers=headers,verify=False).text
js=re.search('var jsonData=(.*)',req).group(1).strip(',')
js=json.loads(js)
skuList=js['skuList'] ###颜色分类列表
df = pd.DataFrame(
columns=('商品ID', '颜色分类', 'SKU柜台价', 'SKU零售价', 'SKU图片'))
x = 0
for i in skuList:
itemSkuSpecValueList=i['itemSkuSpecValueList']
try:
pic=i['pic']
except:
pic=''
try:
counterPrice = i['counterPrice']
except:
counterPrice=''
try:
retailPrice=i['retailPrice']
except:
retailPrice=''
skuvalue=''
for j in itemSkuSpecValueList:
try:
skuvalue=skuvalue+j['skuSpecValue']['value']+' '
except:
skuvalue=''
skuvalue=skuvalue.strip(' ')
df.loc[x] = [id,skuvalue,counterPrice,retailPrice,pic]
x=x+1
print(id,skuvalue,counterPrice,retailPrice,pic)
#print(df)
#df.to_csv('get_items_data.csv',index=False, encoding="GB18030")
return df综合上述,将所有数据结合在一起,代码如下:
#!coding=utf-8
import requests
import re
import random
import time
import json
from requests.packages.urllib3.exceptions import InsecureRequestWarning
import pandas as pd
requests.packages.urllib3.disable_warnings(InsecureRequestWarning) ###禁止提醒SSL警告
###格式化时间戳
def timestamp_to_date(time_stamp, format_string="%Y-%m-%d %H:%M:%S"):
time_array = time.localtime(int(time_stamp)/1000)
str_date = time.strftime(format_string, time_array)
return str_date
class wyyx(object):
### 获取分类
def get_categoryList(self):
url='http://you.163.com/xhr/globalinfo//queryTop.json'
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'you.163.com',
'Referer':'http://you.163.com/?from=web_out_pz_baidu_1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
}
req=requests.get(url=url,headers=headers,verify=False).json()
df = pd.DataFrame(columns=('一级分类ID', '一级分类', '二级分类ID', '二级分类', '三级分类ID', '三级分类'))
x = 0
cateList=req['data']['cateList'] ##一级分类
for i in cateList:
id1 = i['id']
name1 = i['name']
subCateGroupList=i['subCateGroupList'] ##二级分类
for j in subCateGroupList:
id2 = j['id']
name2 = j['name']
categoryList=j['categoryList'] ##三级分类
for k in categoryList:
id3=k['id']
name3=k['name']
df.loc[x] = [id1,name1,id2,name2,id3,name3]
x=x+1
#df.to_csv('list.csv')
return df
##获取商品ID数据
def get_items_ID(self): ##移动端网站
s = requests.session()
df=self.get_categoryList()
cateList=df['一级分类ID'].values.tolist()
cateList = list(set(cateList))
df_item=pd.DataFrame(columns=('三级分类ID', '商品ID', '商品名称', '商品简介', '商品图片', '商品单位', '上架时间',
'更新时间', '柜台价', '零售价','商品URL','评论数','好评率','评论观点'))
x=0
for i in cateList: ##一级分类目录商品
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'm.you.163.com',
'Referer': 'http://m.you.163.com/item/list?categoryId='+str(i),
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; MHA-AL00 Build/HUAWEIMHA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.1.4.994 Mobile Safari/537.36',
}
s.headers.update(headers)
time.sleep(1.024) ##延时
url='http://m.you.163.com/item/list?categoryId='+str(i)
req=s.get(url=url,verify=False).text
js=re.search('jsonData=(.*)',req).group(1).strip(';')
js=json.loads(js)
categoryItemList=js['categoryItemList'] ##商品清单列表
for i in categoryItemList:
category_id=i['category']['id'] ##商品三级分类ID
itemList=i['itemList'] ###三级分类下商品
for j in itemList:
id=j['id'] ##商品ID
name=j['name'] ## 商品名称
simpleDesc=j['simpleDesc'] ##商品简介
primaryPicUrl=j['primaryPicUrl'] ##商品图片
pieceUnitDesc=j['pieceUnitDesc'] ##商品单位
onSaleTime=timestamp_to_date(j['onSaleTime']) ##上架时间
updateTime=timestamp_to_date(j['updateTime']) ##更新时间
counterPrice=j['counterPrice'] ##柜台价
retailPrice=j['retailPrice'] ##零售价
itemUrl='http://you.163.com/item/detail?id='+str(id) ##商品URL
commentdata=self.get_comment(str(id))
commentcount=commentdata[0] ##评论数
goodCmtRate=commentdata[1] ##好评率
comment=commentdata[2] ##评论观点
df_item.loc[x] = [category_id, id, name, simpleDesc, primaryPicUrl, pieceUnitDesc, onSaleTime,
updateTime, counterPrice, retailPrice,itemUrl,commentcount,goodCmtRate,comment]
x=x+1
#print(category_id, id, name, simpleDesc, primaryPicUrl, pieceUnitDesc, onSaleTime, updateTime, counterPrice, retailPrice)
df['三级分类ID'] = df['三级分类ID'].apply(str) ##设置列格式
#df_item.to_csv('df_item.csv', index=False, encoding="GB18030")
df_item['三级分类ID'] = df_item['三级分类ID'].apply(str) #设置列格式
items=pd.merge(df_item,df,how='left',on=['三级分类ID'])
##调整列顺序
items=items[['一级分类ID', '一级分类', '二级分类ID', '二级分类', '三级分类ID', '三级分类'
, '商品ID', '商品名称', '商品简介', '商品单位', '上架时间', '更新时间', '柜台价', '零售价',
'商品URL','商品图片','评论数','好评率','评论观点']]
print(items)
items.to_csv('items.csv',index=False, encoding="GB18030")
return items
###获取所有数据(商品ID+SKU数据)
def all_data(self,path=''): ##path默认空值,直接调用self.get_items_ID()获取数据,否则读取path文件的数据
if path=='':
iddata=self.get_items_ID()
else:
iddata=pd.read_csv(path, encoding="GB18030")
idlist=iddata['商品ID'].values.tolist()
skudata = pd.DataFrame( columns=('商品ID', '颜色分类', 'SKU柜台价', 'SKU零售价', 'SKU图片'))
for id in idlist:
df=self.get_items_data(id)
skudata=skudata.append(df)
print(skudata)
skudata['商品ID'] = skudata['商品ID'].apply(str) ##设置列格式
iddata['商品ID'] = iddata['商品ID'].apply(str) # 设置列格式
alldata = pd.merge(skudata, iddata, how='left', on=['商品ID'])
##调整列顺序
alldata = alldata[['一级分类ID', '一级分类', '二级分类ID', '二级分类', '三级分类ID', '三级分类'
, '商品ID', '商品名称', '商品简介', '商品单位', '上架时间', '更新时间', '柜台价', '零售价',
'商品URL', '商品图片', '评论数', '好评率', '评论观点', '颜色分类', 'SKU柜台价', 'SKU零售价', 'SKU图片']]
print(alldata)
alldata.to_csv('alldata.csv', index=False, encoding="GB18030")
##获取单个商品ID的SKU数据
def get_items_data(self,id): ##移动端网站
url='http://m.you.163.com/item/detail?id='+str(id)
UserAgentlist = [
'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36',
'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; MHA-AL00 Build/HUAWEIMHA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.1.4.994 Mobile Safari/537.36',
'Mozilla/5.0 (Linux; Android 6.0.1; OPPO A57 Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/10.13 baiduboxapp/10.13.0.10 (Baidu; P1 6.0.1)',
'Mozilla/5.0 (iPhone 6s; CPU iPhone OS 11_4_1 like Mac OS X) AppleWebKit/604.3.5 (KHTML, like Gecko) Version/11.0 MQQBrowser/8.3.0 Mobile/15B87 Safari/604.1 MttCustomUA/2 QBWebViewType/1 WKType/1',
'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-CN; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/11.9.4.974 UWS/2.13.1.48 Mobile Safari/537.36 AliApp(DingTalk/4.5.11) com.alibaba.android.rimet/10487439 Channel/227200 language/zh-CN',
'Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; BAC-AL00 Build/HUAWEIBAC-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/11.9.4.974 UWS/2.13.1.48 Mobile Safari/537.36 AliApp(DingTalk/4.5.11) com.alibaba.android.rimet/10487439 Channel/227200 language/zh-CN',
'Mozilla/5.0 (iPhone; CPU iPhone OS 10_2 like Mac OS X) AppleWebKit/602.3.12 (KHTML, like Gecko) Mobile/14C92 MicroMessenger/6.5.16 NetType/WIFI Language/zh_CN'
]
ran = random.randint(0, len(UserAgentlist)-1)
UserAgen = UserAgentlist[ran]
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'m.you.163.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':UserAgen,
}
req=requests.get(url=url,headers=headers,verify=False).text
js=re.search('var jsonData=(.*)',req).group(1).strip(',')
js=json.loads(js)
skuList=js['skuList'] ###颜色分类列表
df = pd.DataFrame(
columns=('商品ID', '颜色分类', 'SKU柜台价', 'SKU零售价', 'SKU图片'))
x = 0
for i in skuList:
itemSkuSpecValueList=i['itemSkuSpecValueList']
try:
pic=i['pic']
except:
pic=''
try:
counterPrice = i['counterPrice']
except:
counterPrice=''
try:
retailPrice=i['retailPrice']
except:
retailPrice=''
skuvalue=''
for j in itemSkuSpecValueList:
try:
skuvalue=skuvalue+j['skuSpecValue']['value']+' '
except:
skuvalue=''
skuvalue=skuvalue.strip(' ')
df.loc[x] = [id,skuvalue,counterPrice,retailPrice,pic]
x=x+1
print(id,skuvalue,counterPrice,retailPrice,pic)
#print(df)
#df.to_csv('get_items_data.csv',index=False, encoding="GB18030")
return df
##获取单个商品ID评论数及评论观点数据
def get_comment(self,id): ##电脑端网站
#time.sleep(1.22)
now=str(int(time.time()*1000))
url='http://you.163.com/xhr/comment/tags.json?__timestamp={}&itemId={}'.format(now,id)
UserAgentlist = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 OPR/56.0.3051.104',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36 Maxthon/5.2.5.4000',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36',
]
ran = random.randint(0, len(UserAgentlist)-1)
UserAgen = UserAgentlist[ran]
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'you.163.com',
'Referer':'http://you.163.com/item/detail?id={}&_stat_referer=index&_stat_area=mod_popularItem_item_1'.format(id),
'User-Agent':UserAgen,
'X-Requested-With':'XMLHttpRequest'
}
req = requests.get(url=url, headers=headers, verify=False).text
js=json.loads(req)
data=js['data']
comment=''
goodCmtRate='0'
commentcount='0'
if data!=[]:
commentcount=data[0]['strCount'] ##评论数
url='http://you.163.com/xhr/comment/itemGoodRates.json'
postdata={'itemId': id}
itemGoodRates=requests.post(url=url, headers=headers, data=postdata,verify=False).json()
goodCmtRate=itemGoodRates['data']['goodCmtRate'] ##好评率
for i in data:
comment=str(comment)+str(i['name'])+'('+str(i['strCount'])+ ')' ##评论观点
commentdata=[commentcount,goodCmtRate,comment]
print(commentdata)
return commentdata
if __name__ == '__main__':
wy=wyyx()
wy.all_data() ##
得到数据的样本如下:

(PS:由于电脑端和手机端的爬取数据难度及数据清洗不一样,所以使用了两种方式结合。)