笔试题:预处理/结构体字符对齐/typedef的使用
1. 什么是预编译,什么时候需要预编译?**
答:预编译又称为预处理,是做些代码文本替换工作,处理以#开头的指令,比如拷贝#include包含的文本代码,#define宏定义的替换,条件编译等 ,就是编译做的预备工作的阶段。主要处理#开头的预备工作阶段,主要处理#开头的预编译指令,预编译指令指示了在程序正式编译之前就由编译器进行的操作,可以放在程序的任何位置,C编译系统对程序进行通常的编译之前首先进行预处理,C提供的预处理的主要有以下三种:1)宏定义2)文件包含3)条件编译。 什么时候需要预编译:第一中情况:总是使用而不经常改动的大型代码。第二中情况:程序由多个模块组成,所有模块使用一组标注的包含文件和相同的编译选项。在这种情况下,可以将所有抱哈文件预编译为一个编译头。
2.char * const p char const *p const char *p这三者的关系**:
char * const p 常量指针,p值不可以修改。
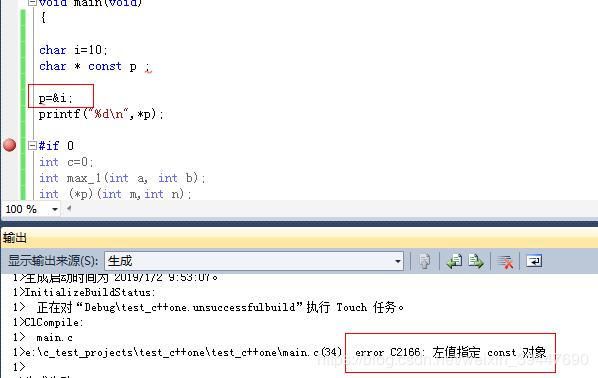
char const *p 和const char *p 一样 都是指向常量的指针。指针指向的值不变指向常量的指针,不能改变指针指向的值。

3.指向字符串的数组和指针的区别**
char str1[] = "abc"; char str2[] = "abc"; const char str3[] = "abc";
const char str4[] = "abc"; const char *str5 = "abc";
const char *str6 = "abc"; char *str7 = "abc"; char *str8 = "abc";
cout < < ( str1 == str2 ) < < endl; cout < < ( str3 == str4 ) < < endl;
cout < < ( str5 == str6 ) < < endl; out < < ( str7 == str8 ) < < endl;
cout<< <
4.对sizeof的使用
void UpperCase( char str[] ) // 将 str 中的小写字母转换成大写字母
{ for( size_t i=0; i 根据语法,sizeof如用于数组,只能测出静态数组的大小,无法检测动态分配的或外部数组的大小。函数外的str是一个静态定义的数组,因此其大小为6,函数内str实际上只是一个指向字符串的指针,没有任何额外的与数组相关的信息,因此sizeof作用域上只将其当指针看,一个指针为4个字节,因此返回4.
题目可以修改为如下就正确了:
void UpperCase( char str[] ,unsigned int n) // 将 str 中的小写字母转换成大写字母
{ for( size_t i=0; i 5.结构体字节对齐的问题
结构体的长度是一个比较特殊的问题:
struct S2
{
char c;
char t;
int i;
char t1;
char t2;
char t3;
char t4;
char t5;
};
struct S2 S_T;
printf("%d\n",&S_T.c);
printf("%d\n",&S_T.t);
printf("%d\n",&S_T.i);
printf("%d\n",&S_T.t1);
printf("%d\n",&S_T.t2);
printf("%d\n",&S_T.t3);
printf("%d\n",&S_T.t4);

c和t占了两个地址,当到i的时候因为是int型,直接空了两个地址,占领了4个地址。后面t1 t2 t3 t4又是连续的。
MSDN上的说明:
When applied to a structure type or variable, sizeof returns the actual siz
e, which may include padding bytes inserted for alignment.
对于结构体需要考虑字节对齐,首先
- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
- 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
6.(index+1)和index+1的区别
int index[6]={1,2,3,4,5,6};
int *ptr=(int*)(&index+1);
printf("%d,%d\n",*(index+1),*(ptr-1));
![]()
*(index+1)对应的数组的第二个元素 &index+1是数组最后一个数据对应地址的下一个地址。
答案:2 6
考察&a+1 与&(a+1)的区别,&a是对象(数组)的首地址,而a或者&a[0]指的是元素的首地址
*7.指针地址越界的问题
int main()
{ char a;
char *str=&a;
strcpy(str,"hello");
printf(str);
return 0;
}
 可以正常输出,但是把一个字符串复制进一个字符变量指针所指向的地址,虽然可以正确输出,但是已经出现内存越界,如果这段内存其他程序已经使用,会被覆盖,容易导致程序出现异常或者崩溃。
可以正常输出,但是把一个字符串复制进一个字符变量指针所指向的地址,虽然可以正确输出,但是已经出现内存越界,如果这段内存其他程序已经使用,会被覆盖,容易导致程序出现异常或者崩溃。
8.写一个标准宏,这个宏输入两个参数并返回较大的一个。
#define Max(X,Y) ((X)>(Y)?(X):(Y)) 切记结尾没有;
9.嵌入式系统任务一般需要写一个无线循环,你怎么用C编写死循环?
while(1){}或者for(;?
10.typedef 与 #define的区别
1)格式不同
#define pi 3.1415926 //后面没有分号
typedef unsigned int INT32U; 后面必须加分号
2)意义不同:
typedef是定义了一种类型的新别名,不同于宏,它不是简单的字符串替换。
举两个例子来看(来自网络):
第一个例子:
typedef char *pStr1;
#define pStr2 char *;
pStr1 s1, s2;
pStr2 s3, s4;
s1,s2,s3都是char指针变量 而s4是char变量,就是因为宏只是简单的字符替换而typedef定义了类型的新别名。
第二个例子
typedef char * pStr;
char string[4] = "abc";
const char *p1 = string;
const pStr p2 = string;
p1++;
p2++;
p2++会报错,因为p2是常量指针,地址为只读。
3)
一个应用就是为数据类型重新命名,这样更方便使用
typedef unsigned int INT32U;
typedef int INT32S;
typedef INT32S STATUS;
typedef unsigned short INT16U;
typedef short INT16S;
typedef unsigned char INT8U;
typedef char INT8S;
typedef unsigned long INT40U;
另一个应用就是给结构体重命名;
typedef struct Send_ACK_struct
{
INT8U frame_header[4];
INT8U Device_id[2];
INT8U Data_crc;
}Send_ACK_struct;
Send_ACK_struct Send_ack_1005 ; //后面就是直接用Send_ACK_struct 定义上面的数组。
11.大端和小端:
小端:低位字节数据存储在低地址。
大端:低位字节数据存储在高地址。
例如:int a=0x12345678;(a的首地址:0x2000)
大端:0x2000 0x12 ;0x2001 0x34 ;0x2002 0x56;0x2003 0x78
小段:0x2000 0x78 ;0x2001 0x56 ;0x2002 0x34;0x2003 0x12