Python数据挖掘:利用聚类算法进行航空公司客户价值分析
无小意丶
个人博客地址:无小意
知乎主页:无小意丶
公众号: 数据路(shuju_lu)
刚刚开始写博客,希望能保持关注,会继续努力。
以数据相关为主,互联网为辅进行文章发布。
本文是《Python数据分析与挖掘实战》一书的实战部分,在整理分析后的复现。
本篇文章是本书第七章的实战:航空公司客户价值分析。
相关附件代码、数据和PDF,关注公众号“数据路”,回复:挖掘实战。
更好的观看体验,在线Jupyter notebook科赛平台,直接体验,点击这里
1.背景与挖掘目标
1.1背景
- 航空公司业务竞争激烈,从产品中心转化为客户中心。
- 针对不同类型客户,进行精准营销,实现利润最大化。
- 建立客户价值评估模型,进行客户分类,是解决问题的办法
1.2挖掘目标
- 借助航空公司客户数据,对客户进行分类。
- 对不同的客户类别进行特征分析,比较不同类客户的客户价值
- 对不同价值的客户类别提供个性化服务,制定相应的营销策略。
详情数据见数据集内容中的air_data.csv和客户信息属性说明
2.分析方法与过程
2.1分析方法
- 首先,明确目标是客户价值识别。
- 识别客户价值,应用最广泛的模型是三个指标(消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary))
- 以上指标简称RFM模型,作用是识别高价值的客户
- 消费金额,一般表示一段时间内,消费的总额。但是,因为航空票价收到距离和舱位等级的影响,同样金额对航空公司价值不同。
- 因此,需要修改指标。选定变量,舱位因素=舱位所对应的折扣系数的平均值=C,距离因素=一定时间内积累的飞行里程=M。
- 再考虑到,航空公司的会员系统,用户的入会时间长短能在一定程度上影响客户价值,所以增加指标L=入会时间长度=客户关系长度
- 总共确定了五个指标,消费时间间隔R,客户关系长度L,消费频率F,飞行里程M和折扣系数的平均值C
- 以上指标,作为航空公司识别客户价值指标,记为LRFMC模型
- 如果采用传统的RFM模型,如下图。它是依据,各个属性的平均值进行划分,但是,细分的客户群太多,精准营销的成本太高。

- 综上,这次案例,采用聚类的办法进行识别客户价值,以LRFMC模型为基础
- 本案例,总体流程如下图
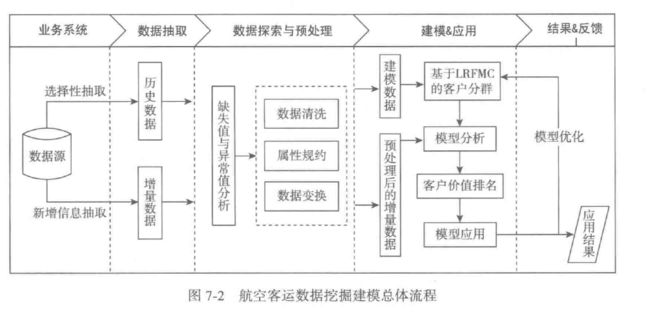
2.2挖掘步骤
- 从航空公司,选择性抽取与新增数据抽取,形成历史数据和增量数据
- 对步骤一的两个数据,进行数据探索性分析和预处理,主要有缺失值与异常值的分析处理,属性规约、清洗和变换
- 利用步骤2中的已处理数据作为建模数据,基于旅客价值的LRFMC模型进行客户分群,对各个客户群再进行特征分析,识别有价值客户。
- 针对模型结果得到不同价值的客户,采用不同的营销手段,指定定制化的营销服务,或者针对性的优惠与关怀。(重点维护老客户)
2.3数据抽取
- 选取,2014-03-31为结束时间,选取宽度为两年的时间段,作为观测窗口,抽取观测窗口内所有客户的详细数据,形成历史数据
- 对于后续新增的客户信息,采用目前的时间作为重点,形成新增数据
2.4探索性分析
- 本案例的探索分析,主要对数据进行缺失值和异常值分析。
- 发现,存在票价为控制,折扣率为0,飞行公里数为0。票价为空值,可能是不存在飞行记录,其他空值可能是,飞机票来自于积分兑换等渠道,
- 查找每列属性观测值中空值的个数、最大值、最小值的代码如下。
import pandas as pd
datafile= r'/home/kesci/input/date27730/air_data.csv' #航空原始数据,第一行为属性标签
resultfile = r'/home/kesci/work/test.xls' #数据探索结果表
data = pd.read_csv(datafile, encoding = 'utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅
print(explore)
explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数
explore = explore[['null', 'max', 'min']]
explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名
print('-----------------------------------------------------------------以下是处理后数据')
print(explore)
'''这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)'''
-----------------------------------------------------------------以下是处理前数据
count unique top freq mean std
MEMBER_NO 62988 NaN NaN NaN 31494.5 18183.2
FFP_DATE 62988 3068 2011/01/13 184 NaN NaN
FIRST_FLIGHT_DATE 62988 3406 2013/02/16 96 NaN NaN
GENDER 62985 2 男 48134 NaN NaN
FFP_TIER 62988 NaN NaN NaN 4.10216 0.373856
WORK_CITY 60719 3310 广州 9385 NaN NaN
WORK_PROVINCE 59740 1185 广东 17507 NaN NaN
WORK_COUNTRY 62962 118 CN 57748 NaN NaN
...
-----------------------------------------------------------------以下是处理后数据
空值数 最大值 最小值
MEMBER_NO 0 62988 1
FFP_DATE 0 NaN NaN
FIRST_FLIGHT_DATE 0 NaN NaN
GENDER 3 NaN NaN
FFP_TIER 0 6 4
WORK_CITY 2269 NaN NaN
WORK_PROVINCE 3248 NaN NaN
WORK_COUNTRY 26 NaN NaN
AGE 420 110 6
LOAD_TIME 0 NaN NaN
FLIGHT_COUNT 0 213 2
BP_SUM 0 505308 0
...
2.3数据预处理
- 数据清洗
- 丢弃票价为空记录
- 丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的记录
import pandas as pd
datafile= '/home/kesci/input/date27730/air_data.csv' #航空原始数据,第一行为属性标签
cleanedfile = '' #数据清洗后保存的文件
data = pd.read_csv(datafile,encoding='utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()] #票价非空值才保留
#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与”,书上给的代码无法正常运行,修改'*'为'&'
data = data[index1 | index2 | index3] #该规则是“或”
print(data)
# data.to_excel(cleanedfile) #导出结果
————————————————————以下是处理后数据————————
MEMBER_NO FFP_DATE FIRST_FLIGHT_DATE GENDER FFP_TIER \
0 54993 2006/11/02 2008/12/24 男 6
1 28065 2007/02/19 2007/08/03 男 6
2 55106 2007/02/01 2007/08/30 男 6
3 21189 2008/08/22 2008/08/23 男 5
4 39546 2009/04/10 2009/04/15 男 6
5 56972 2008/02/10 2009/09/29 男 6
6 44924 2006/03/22 2006/03/29 男 6
7 22631 2010/04/09 2010/04/09 女 6
8 32197 2011/06/07 2011/07/01 男 5
9 31645 2010/07/05 2010/07/05 女 6
属性规约
- 原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与模型相关的六个属性。
- 删除其他无用属性,如会员卡号等等
def reduction_data(data):
data = data[['LOAD_TIME', 'FFP_DATE', 'LAST_TO_END', 'FLIGHT_COUNT', 'SEG_KM_SUM', 'avg_discount']]
# data['L']=pd.datetime(data['LOAD_TIME'])-pd.datetime(data['FFP_DATE'])
# data['L']=int(((parse(data['LOAD_TIME'])-parse(data['FFP_ADTE'])).days)/30)
d_ffp = pd.to_datetime(data['FFP_DATE'])
d_load = pd.to_datetime(data['LOAD_TIME'])
res = d_load - d_ffp
data2=data.copy()
data2['L'] = res.map(lambda x: x / np.timedelta64(30 * 24 * 60, 'm'))
data2['R'] = data['LAST_TO_END']
data2['F'] = data['FLIGHT_COUNT']
data2['M'] = data['SEG_KM_SUM']
data2['C'] = data['avg_discount']
data3 = data2[['L', 'R', 'F', 'M', 'C']]
return data3
data3=reduction_data(data)
print(data3)
————————————以下是以上代码处理后数据————————————
L R F M C
0 90.200000 1 210 580717 0.961639
1 86.566667 7 140 293678 1.252314
2 87.166667 11 135 283712 1.254676
3 68.233333 97 23 281336 1.090870
4 60.533333 5 152 309928 0.970658
5 74.700000 79 92 294585 0.967692
6 97.700000 1 101 287042 0.965347
7 48.400000 3 73 287230 0.962070
8 34.266667 6 56 321489 0.828478
数据变换
- 意思是,将原始数据转换成“适当”的格式,用来适应算法和分析等等的需要。
- 本案例,主要采用数据变换的方式为属性构造和数据标准化 3.需要构造LRFMC的五个指标
- L=LOAD_TIME-FFP_DATE(会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间(单位:月))
- R=LAST_TO_END(客户最近一次乘坐公司距观测窗口结束的月数=最后一次。。。)
- F=FLIGHT_COUNT(观测窗口内的飞行次数)
- M=SEG_KM_SUM(观测窗口的总飞行里程)
- C=AVG_DISCOUNT(平均折扣率)
def zscore_data(data):
data = (data - data.mean(axis=0)) / data.std(axis=0)
data.columns = ['Z' + i for i in data.columns]
return data
data4 = zscore_data(data3)
data4
————————————以下是以上代码处理后数据————————————
ZL ZR ZF ZM ZC
0 1.435707 -0.944948 14.034016 26.761154 1.295540
1 1.307152 -0.911894 9.073213 13.126864 2.868176
2 1.328381 -0.889859 8.718869 12.653481 2.880950
3 0.658476 -0.416098 0.781585 12.540622 1.994714
4 0.386032 -0.922912 9.923636 13.898736 1.344335
5 0.887281 -0.515257 5.671519 13.169947 1.328291
模型构建
1.客户聚类
利用K-Means聚类算法对客户数据进行客户分群,聚成五类(根据业务理解和需要,分析与讨论后,确定客户类别数量)
代码如下
inputfile = r'/home/kesci/input/date27730/zscoreddata.xls' #待聚类的数据文件
k = 5 #需要进行的聚类类别数
#读取数据并进行聚类分析
data = pd.read_excel(inputfile) #读取数据
#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data) #训练模型
r1 = pd.Series(kmodel.labels_).value_counts()
r2 = pd.DataFrame(kmodel.cluster_centers_)
r = pd.concat([r2, r1], axis=1)
r.columns = list(data.columns) + ['类别数目']
# print(r)
# r.to_excel(classoutfile,index=False)
r = pd.concat([data, pd.Series(kmodel.labels_, index=data.index)], axis=1)
r.columns = list(data.columns) + ['聚类类别']
print(kmodel.cluster_centers_)
print(kmodel.labels_)
r
[[-0.70078704 -0.41513666 -0.1607619 -0.16049688 -0.25665898]
[-0.31411607 1.68662534 -0.57386257 -0.53661609 -0.17243195]
[ 0.48347647 -0.79941777 2.48236495 2.42356419 0.30943042]
[ 1.16033496 -0.37744106 -0.0870043 -0.09499704 -0.15836889]
[ 0.05165705 -0.00258448 -0.23089344 -0.23513858 2.17775056]]
[3 3 3 ... 3 3 3]
ZL ZR ZF ZM ZC 聚类类别
0 1.689882 0.140299 -0.635788 0.068794 -0.337186 3
1 1.689882 -0.322442 0.852453 0.843848 -0.553613 3
2 1.681743 -0.487707 -0.210576 0.158569 -1.094680 3
3 1.534185 -0.785184 0.002030 0.273091 -1.148787 3
4 0.890167 -0.426559 -0.635788 -0.685170 1.231909 4
5 -0.232618 -0.690983 -0.635788 -0.603898 -0.391293 0
6 -0.496949 1.996225 -0.706656 -0.661752 -1.311107 1
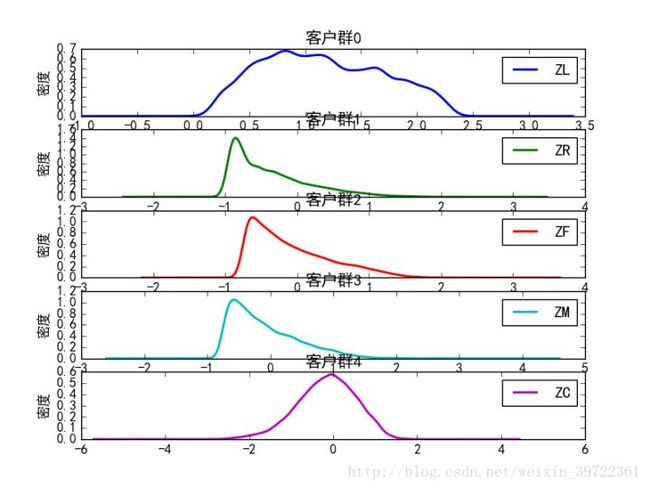
就剩下最后一步,画图:
def density_plot(data):
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
p=data.plot(kind='kde',linewidth=2,subplots=True,sharex=False)
[p[i].set_ylabel('密度') for i in range(5)]
[p[i].set_title('客户群%d' %i) for i in range(5)]
plt.legend()
plt.show()
return plt
density_plot(data4)
clu = kmodel.cluster_centers_
x = [1,2,3,4,5]
colors = ['red','green','yellow','blue','black']
for i in range(5):
plt.plot(x,clu[i],label='clustre '+str(i),linewidth=6-i,color=colors[i],marker='o')
plt.xlabel('L R F M C')
plt.ylabel('values')
plt.show()
客户群1:red,客户群2:green,客户群3:yellow,客户群4:blue,客户群5:black
客户关系长度L,消费时间间隔R,消费频率F,飞行里程M,折扣系数的平均值C。
横坐标上,总共有五个节点,按顺序对应LRFMC。
对应节点上的客户群的属性值,代表该客户群的该属性的程度。
2.客户价值分析
我们重点关注的是L,F,M,从图中可以看到:
1、客户群4[blue] 的F,M很高,L也不低,可以看做是重要保持的客户;
2、客户群3[yellow] 重要发展客户
3、客户群1[red] 重要挽留客户,原因:入会时间长,但是F,M较低
4、客户群2[green] 一般客户
5、客户群5[black] 低价值客户
- 重要保持客户:R(最近乘坐航班)低,F(乘坐次数)、C(平均折扣率高,舱位较高)、M(里程数)高。最优先的目标,进行差异化管理,提高满意度。
- 重要发展客户:R低,C高,F或M较低,潜在价值客户。虽然说,当前价值不高,但是却有很大的发展潜力,促使这类客户在本公司消费和合作伙伴处消费。
- 重要挽留客户:C、F、M较高,但是较长时间没有乘坐(R)小。增加与这类客户的互动,了解情况,采取一定手段,延长客户生命周期。
- 一般与低价值客户:C、F、M、L低,R高。他们可能是在公司打折促销时才会乘坐本公司航班。

3.模型应用
- 会员的升级与保级(积分兑换原理相同)
会员可以分为,钻石,白金,金卡,银卡…
部分客户会因为不了解自身积分情况,错失升级机会,客户和航空公司都会有损失
在会员接近升级前,对高价值客户进行促销活动,刺激他们消费达到标准,双方获利 - 交叉销售
通过发行联名卡与非航空公司各做,使得企业在其他企业消费过程中获得本公司的积分,增强与本公司联系,提高忠诚度。 - 管理模式
企业要获得长期的丰厚利润,必须需要大量稳定的、高质量的客户。
维持老客户的成本远远低于新客户,保持优质客户是十分重要的。
精准营销中,也有成本因素,所以按照客户价值排名,进行优先的,特别的营销策略,是维持客户的关键。
4.小结
本文,结合航空公司客户价值案例的分析,重点介绍了数据挖掘算法中K-Means聚类算法的应用。 针对,传统RFM模型的不足,结合案例进行改造,设定了五个指标的LRFMC模型。最后通过聚类的结果,选出客户价值排行,并且制定相应策略