python django面试题(第八章)
第八章 django
1. 简述http协议和常用请求头
http协议是超文本传输协议
常用请求头:
| 协议头 | 说明 |
|---|---|
| Accept | 可接受的响应内容类型 |
| Accept-Charset | 可接受的字符集 |
| Accept-Encoding | 可接受的响应内容的编码方式。 |
| Accept-Language | 可接受的响应内容语言列表。 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 |
| Authorization | 用于表示HTTP协议中需要认证资源的认证信息 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie |
| Content-Length | 以8进制表示的请求体的长度 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的"HTTP日期"格式来发送) |
| Expect | 表示客户端要求服务器做出特定的行为 |
| From | 发起此请求的用户的邮件地址 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 |
| If-Modified-Since | 允许在对应的资源未被修改的情况下返回304未修改 |
| If-None-Match | 允许在对应的内容未被修改的情况下返回304未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 |
| Range | 表示请求某个实体的一部分,字节偏移以0开始。 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用"trailers"表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 |
| User-Agent | 浏览器的身份标识字符串 |
| Upgrade | 要求服务器升级到一个高版本协议。 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 |
2.常用请求方法
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 获得报文首部 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
3. 常见状态码
| 状态码 | 说明 |
|---|---|
| 200 | 请求成功 |
| 201 | 请求完成,结果是创建了新资源 |
| 202 | 请求被接受,但处理尚未完成 |
| 204 | 服务器端已经实现了请求,但是没有返回新的信息 |
| 301 | 永久重定向 |
| 302 | 重定向 |
| 304 | 资源未更新 |
| 400 | 非法请求 |
| 401 | 未授权 |
| 403 | 禁止 |
| 404 | 没找到 |
| 500 | 服务器内部错误 |
| 501 | 服务器无法识别 |
| 502 | 错误网关 |
| 503 | 服务出错 |
4.http和https区别
http:
- 超文本传输协议,明文传输
- 80端口
- 连接简单且是无状态的
https:
- 需要到ca申请证书,要费用
- 具有安全性的ssl加密传输协议
- 端口是443
- https协议是有ssl+http协议构建的可进行加密传输,身份认证的网络协议,安全
5.websocket协议以及原理
- WebSocket*是一种在单个TCP连接上进行全双工通信的协议
- 原理不知道,太复杂,不想记
6.django 如何实现websocket
两种方式:
- django-channel点击跳转 ---- django官方推荐
- dwebsocket ---- 简单方便
7.python web开发中跨域问题的解决思路
线上环境不存在跨域问题,nginx转发
解决思路:
1.什么是跨域
在浏览器窗口中,和某个服务端通过某个 “协议+域名+端口号” 建立了会话的前提下,去使用与这三个属性任意一个不同的源提交了请求,那么浏览器就认为你是跨域了违反了浏览器的同源策略
2.如何解决:3种方法
方法1:安装django-cors-headers
-
下载django-cors-header
pip install django-cors-header -
配置settings.py文件
INSTALLED_APPS = [ ... 'corsheaders', ... ] MIDDLEWARE_CLASSES = ( ... 'corsheaders.middleware.CorsMiddleware', 'django.middleware.common.CommonMiddleware', # 注意顺序 ... ) #跨域增加忽略 CORS_ALLOW_CREDENTIALS = True CORS_ORIGIN_ALLOW_ALL = True CORS_ORIGIN_WHITELIST = ( '*' ) CORS_ALLOW_METHODS = ( 'DELETE', 'GET', 'OPTIONS', 'PATCH', 'POST', 'PUT', 'VIEW', ) CORS_ALLOW_HEADERS = ( 'XMLHttpRequest', 'X_FILENAME', 'accept-encoding', 'authorization', 'content-type', 'dnt', 'origin', 'user-agent', 'x-csrftoken', 'x-requested-with', 'Pragma', )
方法2:使用JSONP
使用Ajax获取json数据时,存在跨域的限制。不过,在Web页面上调用js的script脚本文件时却不受跨域的影响,JSONP就是利用这个来实现跨域的传输。因此,我们需要将Ajax调用中的dataType从JSON改为JSONP(相应的API也需要支持JSONP)格式。jsonp只能用于get请求
方案3.直接修改Django中的views.py文件,原理是修改请求头
#修改views.py中对应API的实现函数,允许其他域通过Ajax请求数据:
def myview(_request):
response = HttpResponse(json.dumps({“key”: “value”, “key2”: “value”}))
response[“Access-Control-Allow-Origin”] = “*”
response[“Access-Control-Allow-Methods”] = “POST, GET, OPTIONS”
response[“Access-Control-Max-Age”] = “1000”
response[“Access-Control-Allow-Headers”] = “*”
return response
8.简述http缓存机制
- 强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
- 比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
9.例举python web框架
django flask tornado sanic web2py
10.http和https的区别
见第四题
11.django,flask,tornado框架的比较
| django | flask | tornado | |
|---|---|---|---|
| socket | 无 | 无 | |
| 中间件 | 无 | ||
| 路由系统 | |||
| 视图 | |||
| 模板引擎 | 有,uimethod,uimodule | ||
| 模板语言 | |||
| cookie | |||
| session | 有,但使用的是加密cookie,保存在客户端 | 无 | |
| csrf | |||
| xss | |||
| 缓存 | 无 | ||
| 信号 | 无,有扩展插件WTForms | 无 | |
| Form | 无 | 无 | |
| Admin | 无 | 无 | |
| ORM | 无 | 无 |
12.什么是Wsgi
WSGI是Web Server Gateway Interface的缩写,Python web服务器网关接口,实际上就是一种协议
工作流程:HTTP 客户端 — web 服务器 — Wsgi — Flask
作用:
- 让 web 服务器知道如何调用 web 应用,传递用户的请求给应用
- 让应用知道用户的请求内容,以及如何返回消息给 web 服务器
13.Django内置组件
- 分页器
- forms组件
- model form
- 缓存机制
- 信号
- 序列化组件
- 中间件
- ContentTypes
- 用户认证组件—auth模块
14.django内建的缓存机制
正常情况下访问流程:
接收请求 -> url路由 -> 视图处理 -> 数据库读写 -> 视图处理 -> 模版渲染 -> 返回请求
django内建缓存机制:
缓存的思路是,既然已经处理过一次,得到了结果,就把当前结果缓存下来。下次再请求时,把缓存的处理结果直接返回。这样,可以极大地减少重复工作,降低数据库负载
下面是缓存思路的伪代码:
给定一个URL, 试图在缓存中查询对应的页面
如果缓存中有该页面:
返回这个缓存的页面
否则:
生成页面
将生成的页面保存到缓存中(用作以后)
返回这个生成的页面
设置缓存
15. django中model的SlugField类型字段有什么用途
SlugField字段是将输入的内容中的空格都替换成‘-’之后保存
用处
17.Django常见的线上部署方式
Nginx+uwsgi
- nginx作为服务器最前端,负责接收client的所有请求,统一管理。静态请求由Nginx自己处理。
- 非静态请求通过uwsgi传递给Django,由Django来进行处理,从而完成一次WEB请求
18.django对数据查询结果排序怎么做,降序怎么做
user = Users.objects.order_by(‘id’)
user = Users.objects.order_by(‘id’)[0:1]
# 如果需要逆序 在字段前加负号 例 (‘-id’)
20.django中使用memcached作为缓存的具体方法,优缺点说明
**优点:**Memcached是Django原生支持的缓存系统,速度快,效率高
**缺点:**基于内存的缓存系统有个明显的缺点就是断电数据丢失
设置缓存
21.django中orm如何查询id不等于5 的元素
User.objects.filter().exclude(id=5) # 查询id不为5的用户
22.把sql语句转化成python代码
select * from company where title like "%abc%" or mecount>999 order by createtime desc;
python orm操作代码
objects.filter(Q(title__contains='abc')|Q(mecount__gh=000)).order_by(-createtime)
23.从输入http://www.baidu.com到页面返回,中间都是发生了什么?
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
24.django请求的生命周期
wsgi—中间件—路由----视图—中间件—wsgi
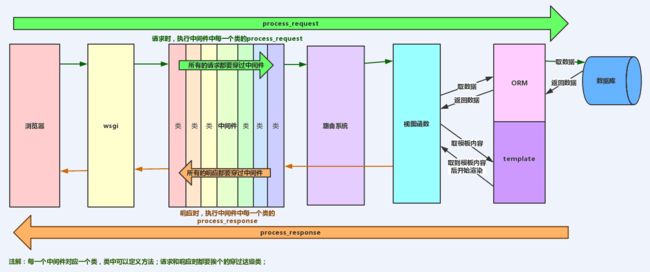
25.django中如何在 model保存前做一定的固定操作,比如写一句日志?
用django信号实现
from django.shortcuts import HttpResponse
import time
import django.dispatch
from django.dispatch import receiver
# 定义一个信号
work_done = django.dispatch.Signal(providing_args=['path', 'time'])
def create_signal(request):
url_path = request.path
print("我已经做完了工作。现在我发送一个信号出去,给那些指定的接收器。")
# 发送信号,将请求的url地址和时间一并传递过去
work_done.send(create_signal, path=url_path, time=time.strftime("%Y-%m-%d %H:%M:%S"))
return HttpResponse("200,ok")
#接收信号
@receiver(work_done, sender=create_signal)
def my_callback(sender, **kwargs):
print("我在%s时间收到来自%s的信号,请求url为%s" % (kwargs['time'], sender, kwargs["path"]))

26.简述 django中间件及其应用场景?
- Django项目中默认启用了csrf保护,每次请求时通过CSRF中间件检查请求中是否有正确token值
- 当用户在页面上发送请求时,通过自定义的认证中间件,判断用户是否已经登陆,未登陆就去登陆。
- 当有用户请求过来时,判断用户是否在白名单或者在黑名单里
27.简述 django FBV和CBV?
- FBV—function base view 函数处理请求
- CBV—class base view 类处理请求
28.如何给 django CBV的函数设置添加装饰器?
django中的类装饰器
29.django如何连接多个数据库并实现读写分离?
-
手动
model.object.using(‘指定数据库’).all()
-
自动
创建一个py文件,创建一个类,实现以下两个方法,函数名固定写法
class Router: def db_for_read(): # 读操作 return 'slave' def db_for_write(): #写操作 return 'default'
读写分离操作详情
30.列举 django orm中你了解的所有方法?
知识点小飞机
- 返回QuerySet对象
- all
- filter
- exclude
- order_by
- reverse
- distinct—去重
- values
- values_list
- 返回对象
- get
- first
- last
- 返回数字
- count
- 返回布尔值
- exists
ORM连表查询 – 正向查询和反向查询
神奇的双下划线
多对多的关系的三种方式
聚合和分组
F查询和Q查询
事务
from django.db import transaction
with transaction.atomic():
# 事务操作
ORM行级锁
select_for_update()
执行原声SQL语句的方式
.extra()
.raw()
性能优化
bulk_create
select_related/prefetch_related
如何在单独的脚本里面执行ORM操作
only和defer
31.django中的F的作用?
操作数据表中的某列值
例(单个更新):
# 普通方式
reporter = Reporters.objects.get(name='Tintin')
reporter.stories_filed += 1 # 放到内存中,使用python计算,然后通过save方法保存
reporter.save()
# 使用F表达式 (简单使用)
from django.db.models import F
reporter = Reporters.objects.get(name='Tintin')
reporter.stories_filed = F('stories_filed') + 1
reporter.save()
虽然看上去和上面的内存Python操作相似,但事实上这是一个描述数据库操作的sql概念
当django遇到F()实例,它覆盖了标准的Python运算符创建一个封装的SQL表达式。在这个例子中,reporter.stories_filed就代表了一个指示数据库对该字段进行增量的命令。
无论reporter.stories_filed的值是或曾是什么,Python一无所知--这完全是由数据库去处理的。所有的Python,通过Django的F() 类,只是去创建SQL语法参考字段和描述操作
例(多个更新):
Reporter.objects.all().update(stories_filed=F('stories_filed') + 1)
32.django中的Q的作用?
对对象进行复杂查询,并支持&(and),|(or),~(not)操作符
例:
from django.db.models import Q
from login.models import New #models对象
news=New.objects.filter(Q(question__startswith='What')) #例1
news=New.objects.filter(Q(question__startswith='Who') | Q(question__startswith='What')) #例2
news=New.objects.filter(Q(question__startswith='Who') | ~Q(pub_date__year=2005)) #例3 ~表示取反
news=Poll.objects.get(Q(question__startswith='Who'),Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))) #例4
33.django中如何执行原生SQL?
在Django中使用原生Sql主要有以下几种方式:
- extra:结果集修改器,一种提供额外查询参数的机制(依赖model)
- raw:执行原始sql并返回模型实例(依赖model)
- 直接执行自定义sql(不依赖model)
1.使用extra
Book.objects.filter(publisher__name='广东人员出版社').extra(where=['price>50'])
Book.objects.filter(publisher__name='广东人员出版社',price__gt=50)
Book.objects.extra(select={'count':'select count(*) from hello_Book'})
2.使用raw:
Book.objects.raw('select * from hello_Book')
Book.objects.raw("insert into hello_author(name) values('测试')")
rawQuerySet为惰性查询,只有在使用时生会真正执行
3.自定义sql
执行自定义sql:
from django.db import connection
cursor=connection.cursor()
#插入操作
cursor.execute("insert into hello_author(name) values('郭敬明')")
#更新操作
cursor.execute('update hello_author set name='abc' where name='bcd'')
#删除操作
cursor.execute('delete from hello_author where name='abc'')
#查询操作
cursor.execute('select * from hello_author')
raw=cursor.fetchone() #返回结果行游标直读向前,读取一条
cursor.fetchall() #读取所有
34.only和 defer的区别?
1.只取id/name/age字段
models.User.objects.all().only("id", "name", "age")
2.除了name字段
models.User.objects.all().defer("name")
35.select_related和 prefetch_related的区别?
36.django中fiter和 exclude的区别
filter 过滤内容
exclude 反向搜索
37.django中 values和 values list的区别?
- values 字典列表,ValuesQuerySet查询集
- values_list 返回元祖列表,字段值
38.如何使用django orm批量创建数据?
objs_list = []
for i in range(100):
obj = People('name%s'%i,18) #models里面的People表
objs_list.append(obj) #添加对象到列表
People.objects.bulk_create(objs_list,100) #更新操作
39.django的Form和 Mode Form的作用?
- Form 自动生成表单,校验表单(表单跟model关联不大)
- Model Form 利用 Django 的 ORM 模型model创建Form(表单跟model关系密切)
40.django的Fom组件中,如果字段中包含 choices参数,请使用两种方式 实现数据源实时更新。
- 重写构造函数
def__init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.fields["city"].widget.choices = models.City.objects.all().values_list("id", "name")
- 利用ModelChoiceField字段,参数为queryset对象
authors = form_model.ModelMultipleChoiceField(queryset=models.NNewType.objects.all())
41.django的 Model I中的 ForeignKey字段中的 on_delete参数有什么作用?
#models.py
class Author(models.Model):
author = models.CharField(max_length=250)
class Books(models.Model):
book = models.ForeignKey(Author,on_delete=models.CASCADE)
- CASCADE:删除作者信息一并删除作者名下的所有书的信息;
- PROTECT:删除作者的信息时,采取保护机制,抛出错误:即不删除Books的内容;
- SET_NULL:只有当null=True才将关联的内容置空;
- SET_DEFAULT:设置为默认值;
- SET( ):括号里可以是函数,设置为自己定义的东西;
- DO_NOTHING:字面的意思,啥也不干,你删除你的干我毛线
42.django中csrf的实现机制?
- 第一步:django第一次响应来自某个客户端的请求时,后端随机产生一个token值,把这个token保存在SESSION状态中;同时,后端把这个token放到cookie中交给前端页面;
- 第二步:下次前端需要发起请求(比如发帖)的时候把这个token值加入到请求数据或者头信息中,一起传给后端;Cookies:{csrftoken:xxxxx}
- 第三步:后端校验前端请求带过来的token和SESSION里的token是否一致。
43.django如何实现 websocket?
channel 或者 dewebsocket
44.基于 django使用ajax发送post请求时,有哪种方法携带 csrf token?
- 1.后端将csrftoken传到前端,发送post请求时携带这个值发送
data: {
csrfmiddlewaretoken: '{{ csrf_token }}'
},
- 2.获取form中隐藏标签的csrftoken值,加入到请求数据中传给后端
data: {
csrfmiddlewaretoken:$('[name="csrfmiddlewaretoken"]').val()
},
- 3.cookie中存在csrftoken,将csrftoken值放到请求头中
headers:{ "X-CSRFtoken":$.cookie("csrftoken")}
45.django缓存如何设置?
见另外一篇文章
46.django的缓存能使用redis吗?如果可以的话,如何配置?
- 准备软件:redis数据库、django-redis模块
- 开始使用:
- 安装:pip install django-redis
- 配置:settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
47.django路由系统中name的作用?
反向解析用
例:
urls.py 文件中
url(r'^home', views.home, name='home'), # 给我的url匹配模式起名为 home
url(r'^index/(\d*)', views.index, name='index'), # 给我的url匹配模式起名为index
在模板里面可以这样引用:
{% url 'home' %}
在views函数中可以这样引用:
from django.urls import reverse
reverse("index", args=("2018", ))
48.django的模板中 filter、 simpletag, inclusiontag的区别?
来个小飞机
- filter:自定义过滤器只是带有一个或两个参数的Python函数
- simpletag:和自定义filter类似,只不过接收更灵活的参数。
- inclusiontag:多用于返回html代码片段
49.django- debug-toolbar的作用?
配置详情
调试用
50.django中如何实现单元测试?
test.py文件中
from django.test import TestCase
from app01.models import People #导入people Model类
# Create your tests here.
#创建测试类
class PeopleTestCase(TestCase):
def setUp(self): #setUp 固定写法
People.objects.create(name='name1',age=12) #创建一条数据
def test_people_models(self): #函数名非固定写法
res = People.objects.get(name='name1') #查询数据库
self.assertEqual(res.age,12) #断言查询结果是否是12
执行测试
python manage.py test
51.解释orm中 db first和 code first的含义?
db first: 先创建数据库,再更新表模型
code first:先写表模型,再更新数据库
52.django中如何根据数据库表生成 model类?
1、修改seting文件,在setting里面设置要连接的数据库类型和名称、地址
2、运行下面代码可以自动生成models模型文件
- python manage.py inspectdb
3、创建一个app执行下下面代码:
- python manage.py inspectdb > app/models.py
53.使用orm和原生sql的优缺点?
SQL:
# 优点:
执行速度快
# 缺点:
编写复杂,开发效率不高
----------------------------------------------------------------
ORM:
# 优点:
让用户不再写SQL语句,提高开发效率
可以很方便地引入数据缓存之类的附加功能
# 缺点:
在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂。
没有原生SQL速度快
54.简述MVC和MTV
MVC:model、view(模块)、controller(视图)
MTV:model、tempalte、view
55.django的 contenttype组件的作用?
contenttype是django的一个组件(app),它可以将django下所有app下的表记录下来
可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。
- 字段:表名称
- 字段:数据行ID
应用:路飞表结构优惠券和专题课和学位课关联