利用Python+Gephi构建金庸人物知识图谱
上周末闲来无事,一时兴起,想着金庸老爷子的武侠世界那么宏大,加上最近无聊看了《Python自然语言处理》这本书,作为金庸迷,为何不做个人物关系知识图谱看看效果如何?
一、数学模型构建
利用Gephi构建知识图谱,无外乎两点:节点信息和边界信息。节点数据还是很好处理的,将金庸武侠世界的所有有名有姓的人物取为节点数据即可,关键在于边界数据的提取。参考众多大神的经验,大部分是以小说章节或者段落为基本分析单元,将出现在同一分析单元的人物视为发生一次关联。个人感觉这种处理方法有其合理性,但也存在一定不足。其一是考虑到金庸小说中每一章节基本讲述的是同一个武侠场景,众多人物对话也是一段一段接替发生,即上下段落之间人物大部分情况是存在直接关系的。其二是如若将出现在同一章节的人物视为发生一次关联,无疑将放大小人物的权重,反之若将出现在同一段落的人物视为发生一次关联,同样会人为缩小主角人物边界联系的权重。基于以上两点考虑,我将同一章节中任意连续两个段落作为基本的分析单元,出现在两个连续段落中的人物即视为发生一次关联。以此为数据样本进行人物关系知识图谱的构建。
二、文本数据提取
1、数据来源
考虑到是以连续两个段落为基本分析单元来分析数据,并且金庸小说经过多次修订,因此为方便数据分析(
与
完美的将文章段落进行了分割)和保证小说数据的权威性,决定利用Python爬虫爬取金庸先生15本小说的最终版。15本小说链接如下: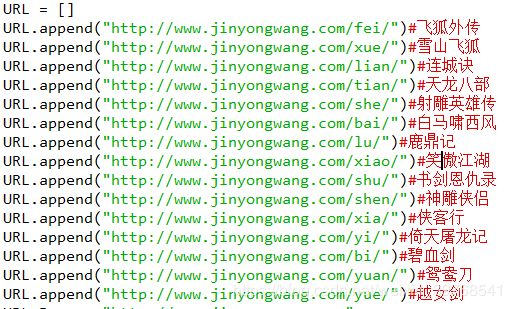
2、爬取文本数据
爬虫代码:
# -*- coding: UTF-8 -*-
import urllib2
from bs4 import BeautifulSoup
import lxml
import re
#import requests
import os
class PaChong:
def __init__(self,URL,URL_ID,URL_Base):#构造函数参数分别为小说网址链接、小说编号(1~15)、网站链接;
self.URL = URL
self.URL_ID = URL_ID
self.URL_Base = URL_Base
self.listpath = None
#打开小说章节
def OpenSeeion(self):#获取小说所有章节链接;
try:
respond = urllib2.urlopen(self.URL)
html = respond.read()
soup = BeautifulSoup(html,'lxml',from_encoding='utf-8')
OringialPath = soup.find_all(class_="mlist");
pattern = re.compile('(?<=href=").*?(?=")')
#print str(OringialPath)
self.listpath = re.findall(pattern,str(OringialPath) )
except:
print "Error"
def gettext(self,sessionURL):#获取该章节所有段落,返回数据类型为Lis
web = self.URL_Base + sessionURL
respond = urllib2.urlopen(web)
html = respond.read()
pattern = re.compile('(?<=).*?(?=
)')
#print str(html)
#temp = re.search(pattern,str(html))
#soup = BeautifulSoup(html,'lxml',from_encoding='utf-8')
#print str(soup.find_all('p'))
#text = temp.group()
text = re.findall(pattern,str(html) )
return text3、数据提取
目前自然语言处理主要针对的是诸如英语这种字母语言,针对中文的语言处理并不是很多。目前比较好的Python库可能算是jieba分词了,因此,本人利用jieba分词对小说的文本数据进行处理。
jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。jieba分词在安装路径中有一个名为dic.txt的文件,该文件为jieba分词的字典库,主要依据该库来扫描数据。
jieba分词支持三种分词模式:
(1) 精确模式, 试图将句子最精确地切开,适合文本分析:
(2) 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
(3) 搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词;
jieba主要函数有如下几种:
(1) jieba.cut:该方法三个输入参数:需要分词的字符串; cut_all 参数用来控制是否采用全模式;HMM参数用来控制是否适用HMM模型;
(2) jieba.cut_for_search:该方法两个参数:需要分词的字符串;是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细;
(3) jieba.cut 以及jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取分词后得到的每一个词语或者使用;
(4) jieb.lcut 以及 jieba.lcut_for_search 直接返回list;
(5) jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射;
jieba分词可以导入指定的自定义词典:
(1) jieba.load_userdict(filename) # filename为自定义词典的路径
(2) jieba.add_word(newword) # newword为自定义词
在本文中无需对所有词语进行分词统计,只需统计金庸所有武侠人物进行词频分析统计,为加快程序运行速度,因此直接通过修改jieba的字典库文件。根据网上资料,金庸武侠世界中共计有1316名人物,算上主要人物别名,共计1387个人物名称。以这些人物名称构建jieba字典库,并替换原有字典。

为方便后期数据处理,利用MySQL构建人物数据库,其中ID:主键、Names:人物名称,alias_1、alias_2、alias_3为对应别名。

构建小说名库,其中 idNovel:小说ID、NovelName:小说名。
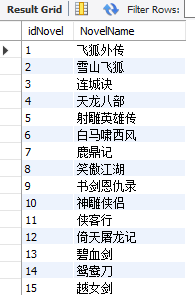
构建人物出现频次数据库,主要统计人物在文章中出现次数,其中idJieDian:主键、UserID:人物ID、Num:频次、Novel:出现文章ID。

构建元数据数据库,该数据用于存储文本数据分析结果,作为一级数据库。其中Novel:数据来源小说,Dtat存储人物关联关系,以Json格式存储数据,针对每一分析单元,产生一个Json数组,ID表示该分析单元的人物ID、Nm表示该人物在该分析单元出现的频次。
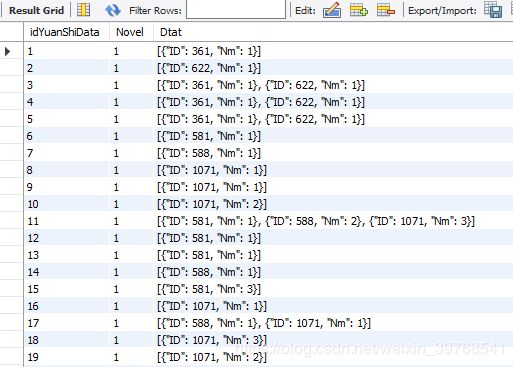
创建完数据库,下面就开始针对文本数据进行分析处理入库。首先利用MySQLdb创建数据库操作类,主要包括数据库的连接、释放、查询、以及SQL语句的执行。
# -*- coding: utf-8 -*-
import MySQLdb
import os
import sys
class OperateMySQL:
def __init__(self,IP,username,pwd,dbname):
self.cursor = None
self.db = None
self.IP = IP #数据库IP
self.username = username #用户名
self.pwd = pwd #密码
self.dbname = dbname #数据库名称
#连接数据库
def connection(self):
self.db = MySQLdb.connect(self.IP, self.username, self.pwd, self.dbname, charset='utf8')
self.cursor = self.db.cursor()
#释放连接
def __del__(self):
if(self.db!=None):
self.db.close()
# 执行sql语句
def excute(self,sql):
try:
self.cursor.execute(sql)
# 提交到数据库执行
self.db.commit()
return 1
except:
# Rollback in case there is any error
self.db.rollback()
return 0
#查询
def select(self,sql):
try:
# 执行SQL语句
self.cursor.execute(sql)
# 获取所有记录列表
results = self.cursor.fetchall()
return results
except:
print "Error: unable to fecth data"
下面就是利用jieba库对文本数据进行分析了,分析代码如下(不得不吐槽Python对中文字符的支持真是不友好)。输入分别为:人物名称、人物的三个别名、文本数据,输出为对应人物出现的频次。
# -*- coding: utf-8 -*-
import sys
stdi,stdo,stde=sys.stdin,sys.stdout,sys.stderr
reload(sys) # Python2.5 初始化后删除了 sys.setdefaultencoding 方法,我们需要重新载入
sys.stdin,sys.stdout,sys.stderr=stdi,stdo,stde
sys.setdefaultencoding('utf-8')
import os, codecs
import jieba
from collections import Counter
class cipin:
@staticmethod
def tongji(namelist,namelist_1,namelist_2,namelist_3,text):
#print len(namelist)
#print len(namelist_1)
#print len(namelist_2)
#print len(namelist_3)
#m = raw_input()
#for newword in namelist:
# #print newword
# jieba.add_word(newword)
#for newword1 in namelist_1:
#print newword1
# jieba.add_word(newword1)
#for newword2 in namelist_2:
# #print newword
# jieba.add_word(newword2)
#for newword3 in namelist_3:
#print newword
# jieba.add_word(newword3)
result = [0] * (len(namelist))
for t in range(len(result)):
result[t] = 0
seg_list = jieba.cut(text)
c = Counter()
for x in seg_list:
if len(x)>1 and x != '\r\n':
c[x] += 1
#print x
for (key,value) in c.items():
#print('%s%s %s %d' % (' '*(5-len(key)), key, '*'*int(value/3), value))
k = "%s" % (key)
v = int(value)
#for str in namelist:
#print v
if k.decode('utf-8') in namelist:
num = namelist.index(k.decode('utf-8'))
result[num] = result[num] + v
#print namelist[num - 1]
elif k.decode('utf-8') in namelist_1:
num = namelist_1.index(k.decode('utf-8'))
result[num] = result[num] + v
elif k.decode('utf-8') in namelist_2:
num = namelist_2.index(k.decode('utf-8'))
result[num] = result[num] + v
elif k.decode('utf-8') in namelist_3:
num = namelist_3.index(k.decode('utf-8'))
result[num] = result[num] + v
else:
continue
return result
下面出场的就是主函数了:
# encoding:utf-8
import OperateMySQL
import sys
import PaChong
import cipin
import json
def getname(namelist,nameliet_1,nameliet_2,nameliet_3):
url = "localhost"
username = "root"
pwd = "1qaz@wsx3edc"
db = "jingyong"
cu = OperateMySQL.OperateMySQL(url,username,pwd,db)
cu.connection()
sql = "SELECT * FROM jingyong.`character` "
re = cu.select(sql)
for row in re:
nameID = row[0]
namelist.append(row[1])
if len(str(row[2]))!=0:
nameliet_1.append(row[2])
if len(str(row[3]))!=0:
nameliet_2.append(row[3])
if len(str(row[4]))!=0:
nameliet_3.append(row[4])
del cu
# 打印结果
#i = 0
#for strs in namelist:
#print str(i) + " " + strs + " " + nameliet_1[i] + " " + nameliet_2[i] + " " +nameliet_3[i]
#i = i+1
def main():
url = "localhost"
username = "root"
pwd = "1qaz@wsx3edc"
db = "jingyong"
cu2 = OperateMySQL.OperateMySQL(url,username,pwd,db)
cu2.connection()
namelist = []
nameliet_1 = []
nameliet_2 = []
nameliet_3 = []
getname(namelist,nameliet_1,nameliet_2,nameliet_3)
URL = []
URL.append("http://www.jinyongwang.com/fei/")#飞狐外传
URL.append("http://www.jinyongwang.com/xue/")#雪山飞狐
URL.append("http://www.jinyongwang.com/lian/")#连城诀
URL.append("http://www.jinyongwang.com/tian/")#天龙八部
URL.append("http://www.jinyongwang.com/she/")#射雕英雄传
URL.append("http://www.jinyongwang.com/bai/")#白马啸西风
URL.append("http://www.jinyongwang.com/lu/")#鹿鼎记
URL.append("http://www.jinyongwang.com/xiao/")#笑傲江湖
URL.append("http://www.jinyongwang.com/shu/")#书剑恩仇录
URL.append("http://www.jinyongwang.com/shen/")#神雕侠侣
URL.append("http://www.jinyongwang.com/xia/")#侠客行
URL.append("http://www.jinyongwang.com/yi/")#倚天屠龙记
URL.append("http://www.jinyongwang.com/bi/")#碧血剑
URL.append("http://www.jinyongwang.com/yuan/")#鸳鸯刀
URL.append("http://www.jinyongwang.com/yue/")#越女剑
URL_Base = "http://www.jinyongwang.com"
for i in range(len(URL)):
cu = PaChong.PaChong(URL[i],i+1,URL_Base)
cu.OpenSeeion()
for j in range(len(cu.listpath)):
temp = cu.gettext(cu.listpath[j])
print (cu.listpath[j])
for text in temp:
#print text
resultJieDian = cipin.cipin.tongji(namelist,nameliet_1,nameliet_2,nameliet_3,text)
li=list(set(resultJieDian))
if len(li) == 1:
continue
data = []
for t in range(len(resultJieDian)):
if resultJieDian[t]!= 0:
dic = {}
dic["ID"] = t
dic["Nm"] = resultJieDian[t]
data.append(dic)
in_json = json.dumps(data)
sql = "INSERT INTO jingyong.yuanshidata SET Novel = " + str(i + 1) + ", Dtat = '" + str(in_json) + "'"
#print sql
re = cu2.excute(sql)
if re == 0:
print "Error " + cu.listpath[j]
m = raw_input()
del sql
del resultJieDian
del li
del cu
if __name__ == "__main__":
main()
至此,人物通联关系的数据提取以完成,顺便还想分析下金庸小说词频,按照如上套路,对金庸小说的词频顺带进行了统计。

通过上述操作,共获取元数据65418条。

三、利用Gephi构建人物关系
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件,,其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。
首先自然是基于元数据创建二级库。创建边界数据表,其中UserID_1与UserID_2表示通联人物ID,Num表示通联次数,novel表示数据来源文章。

根据元数据库,出现在同一分析单元的人物两两存在一次关联,二级库提取代码如下:
# encoding:utf-8
import OperateMySQL
import sys
import PaChong
import cipin
import json
def getname(namelist,nameliet_1,nameliet_2,nameliet_3):
url = "localhost"
username = "root"
pwd = "1qaz@wsx3edc"
db = "jingyong"
cu = OperateMySQL.OperateMySQL(url,username,pwd,db)
cu.connection()
sql = "SELECT * FROM jingyong.`character` "
re = cu.select(sql)
for row in re:
nameID = row[0]
namelist.append(row[1])
nameliet_1.append(row[2])
nameliet_2.append(row[3])
nameliet_3.append(row[4])
del cu
def main():
url = "localhost"
username = "root"
pwd = "1qaz@wsx3edc"
db = "jingyong"
cu2 = OperateMySQL.OperateMySQL(url,username,pwd,db)
cu2.connection()
sql = "SELECT count(idYuanShiData) FROM jingyong.yuanshidata "
re = cu2.select(sql)
for row in re:
num = int(row[0])
loop = int(num/1000) + 1
for temp in range(loop):
sql2 = "SELECT * FROM jingyong.yuanshidata " + " limit " + str(temp*1000) + ",1000"
print sql2
re2 = cu2.select(sql2)
for row2 in re2:
IDs = int(row2[0])
novel = int(row2[1])
data = str(row2[2])
sValue = json.loads(data)
for med in sValue:
sql3 = "SELECT count(idJieDian) FROM jingyong.jiedian where UserID = " + str(med["ID"]) + " and Novel = " + str(novel)
#print sql3
re3 = cu2.select(sql3)
for row3 in re3:
num3 = int(row3[0])
if num3 == 0:
sql4 = "INSERT INTO jingyong.jiedian SET UserID = " + str(med["ID"]) + ", Novel = " + str(novel) + ",Num = " + str(med["Nm"])
re4 = cu2.excute(sql4)
if re4 == 0:
print " insert error " + sql4
m = raw_input()
elif num3 == 1:
sql4 = "SELECT Num FROM jingyong.jiedian where UserID = " + str(med["ID"]) + " and Novel = " + str(novel)
re4 = cu2.select(sql4)
for row4 in re4:
num4 = int(row4[0])
count = num4 + med["Nm"]
sql5 = "UPDATE jingyong.jiedian SET Num = " + str(count) + " where UserID = " + str(med["ID"]) + " and Novel = " + str(novel)
re5 = cu2.excute(sql5)
if re5 == 0:
print " insert error " + sql5
m = raw_input()
else:
print " count error " + sql4
m = raw_input()
if __name__ == "__main__":
main()
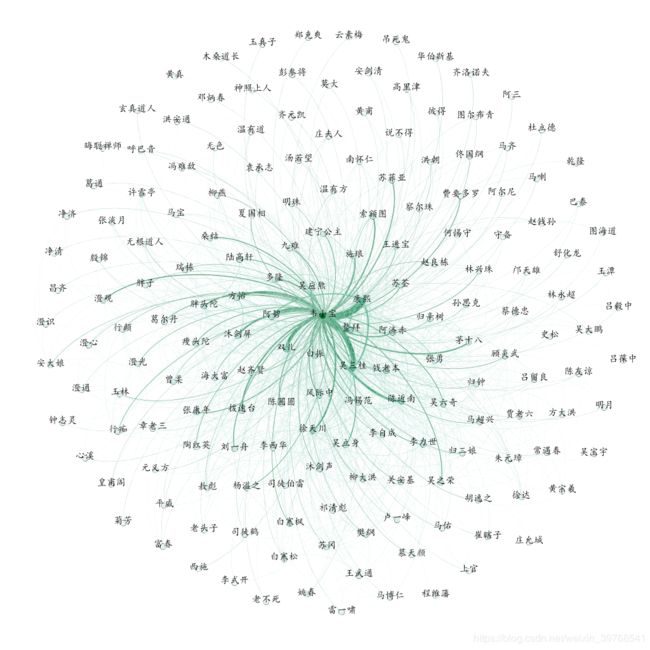
以鹿鼎记为例,首先 根据人物关联二级库,挑选出鹿鼎记中人物关联数据,并导出为CSV文件,编码格式为UTF-8,注意要在文件第一行加上列名。其中前两列为两关联节点名,第三列为权重。

在Gephi数据区,选择边-导入数据表格

选择无向图

导入边数据后,会自动生成节点数据,但是节点数据lable为空,需手动复制过去。
选择外观中节点、边的着色方式,选择一类布局方式,分别点击应用和运行。右侧过滤和统计可以进行数据过滤和统计。

调整标签名称字体

选择预览区,待概览去渲染数据完成后,点击刷新。

右下角可选择数据导出。
四、结果
按照以上思路,基本完成了金庸武侠人物关系知识库。