MesoNet: a Compact Facial Video Forgery Detection Network 论文阅读
MesoNet: a Compact Facial Video Forgery Detection Network
这一篇论文其实还蛮好懂得,没有什么非常复杂的东西。主要思想是基于中层的语义进行检测,MesoNet是mesoscopic network , mesoscopic是细观、介观的意思,在原文中有对这一点进行说明
We propose to detect forged videos of faces by placing our method at a mesoscopic level of analysis. Indeed, microscopic analyses based on image noise cannot be applied in a compressed video context where the image noise is strongly degraded. Similarly, at a higher semantic level, human eye struggles to distinguish forged images [21], especially when the image depicts a human face [1, 7]. That is why we propose to adopt an intermediate approach using a deep neural network with a small number of layers
翻译:我们打算把我们检测视频中假脸的方法置于中层水平的分析。的确,基于图像噪声的低层(语义层级非常低)水平分析不能够应用于被压缩的视频内容中,因为这些内容的图像噪声会被衰弱的。相似的,在高层语义水平,人类的眼睛不能够非好的区分伪造的图片,尤其是当这张图片描述的是人的脸的时候。这是为什么我们采用一个只有很少神经层的深度神经网络中层方法。
Abstract
This paper presents a method to automatically and efficiently detect face tampering in videos, and particularly focuses on two recent techniques used to generate hyperrealistic forged videos: Deepfake and Face2Face.
这篇文章主要是提出了自动检测Deepfake和Face2Face的方法。
Thus, this paper follows a deep learning approach and presents two networks, both with a low number of layers to focus on the mesoscopic properties of images. We evaluate those fast networks on both an existing dataset and a dataset we have constituted from online videos. The tests demonstrate a very successful detection rate with more than 98% for Deepfake and 95% for Face2Face.
告诉我们它提出了两个层数不多的网络,同时还贡献了一个数据集,我感觉这是它主要的贡献了。
1.Introduction
主要告诉了我们假视频的危害还有做deepfake检测的必要性什么的,还有介绍了一些传统方法的检测,然后到了使用DL进行检测。
还介绍了一下两种比较流行的伪造假脸的方式,一个是deepfake另一个是Face2Face,这两个也是这篇论文主要检测的东西。
当然,对于这类的检测最好能够做到实时性。
1.1 DeepFake介绍
说实话,有点久了具体细节不太记得了,但是还是大致了解思想的,大概和gan的思想差不多。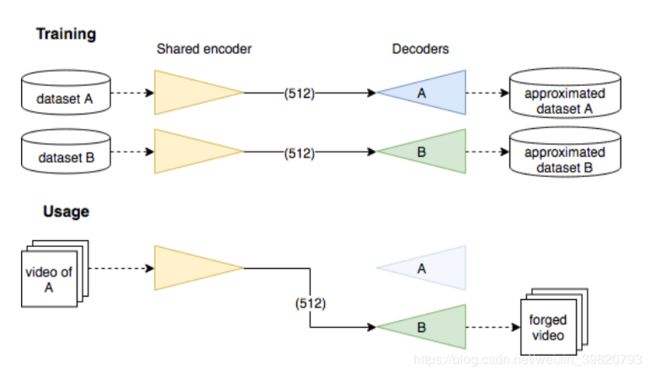
上图为论文中对于deepfake的介绍,主要是训练decoder和encoder。
The process to generate Deepfake images is to gather aligned faces of two different people A and B, then to train an auto-encoder EA to reconstruct the faces of A from the dataset of facial images of A, and an auto-encoder EB to reconstruct the faces of B from the dataset of facial images of B. The trick consists in sharing the weights of the encoding part of the two auto-encoders EA and EB, but keeping their respective decoder separated. Once the optimization is done, any image containing a face of A can be encoded through this shared encoder but decoded with decoder of EB
产生Deepfake图像的过程首先是把两个不同的人A和B的脸对齐,然后训练一个自动编码器EA去重构假脸数据集A中的脸,然后有一个自动编码器EB去重构假脸数据集B。技巧就是分享两个编码器EA和EB编码时候的权值 ,但是保持它们的解码器独立的。直到优化做完,假脸数据集A中的图像能够使用共享权值的编码器进行编码然后使用解码器B进行解码。
以这里为例子,Deepfake就是说我训练出一个通用的编码器和单独的解码器,然后我现在已经能够做到把A中的脸解码成B的脸,就是说我把现在这张图片的脸编码然后使用解码器解码,然后就能够得到假脸了。
这种方式做的假脸在对于细节方面的处理不是非常的到位,可以尝试使用这个确定进行破解。
Basically, the extraction of faces and their reintegration can fail, especially in the case of face occlusions: some frames can end up with no facial reenactment or with a large blurred area or a doubled facial contour. However, those technical errors can easily be avoided with more advanced networks.More deeply, and this is true for other applications, autoencoders tend to poorly reconstruct fine details because of the compression of the input data on a limited encoding space, the result thus often appears a bit blurry.
1.2 Face2Face
Reenactment methods, like [9], are designed to transfer image facial expression from a source to a target person.
论文中没有具体的讲,不过这一种方法主要是做到了实时换脸的效果,所以让人惊叹。
2.Proposed method
2.1 Meso-4
方法其实非常明确。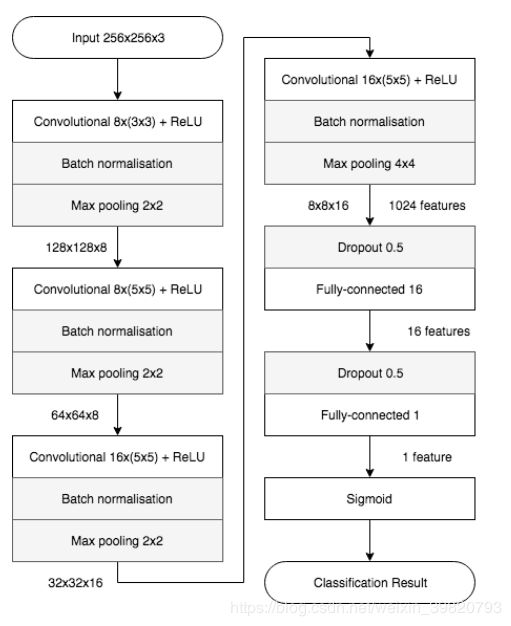
基本上就如上了。
2.2 MesoInception-4
这一个方法也简单,基本如下图: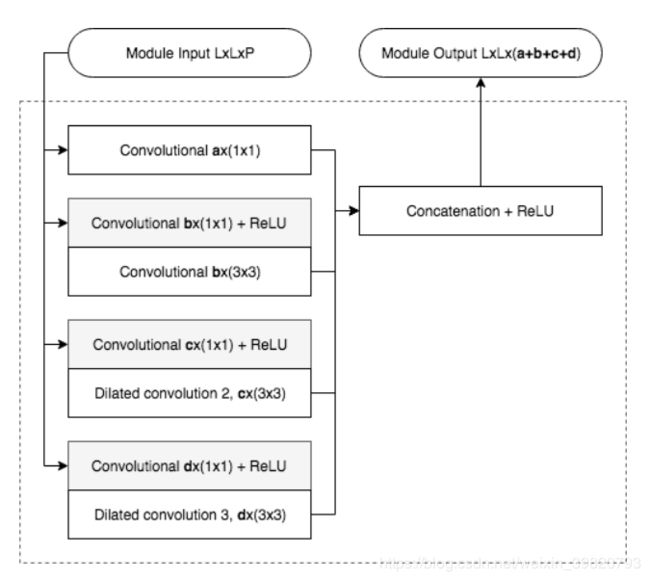
abcd参数也是自己设定的,它在这里用了几个进行实验。

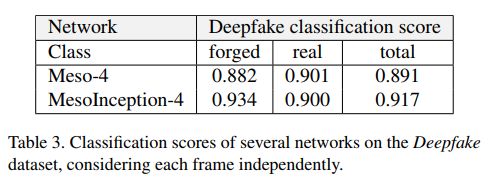
3. Experiments
结果如下:
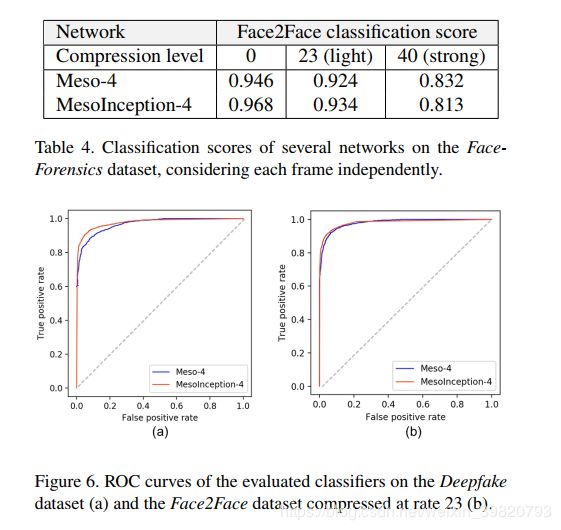
3.4 Image aggregation
这里还提出了图像聚集的方法来提升效果。Theoretically speaking,there is no justification for a gain in scores or a confidence interval indicator as frames of a same video are strongly correlated to one another
虽然它自己也说了理论上应该不会增强的。
In practice, for the viewer comfort,most filmed face contain a majority of stable clear frames.The effect of punctual movement blur, face occlusion and random misprediction can thus be outweighted by a majority of good predictions on a sample of frames taken from the video
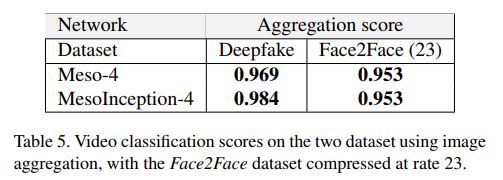
3.5. Aggregation on intra-frames
还做了一个帧内的聚集。
3.6. Intuition behind the network
最后还进行了一些原理解释,大概就是说抽取了中层语义进行判断,同时发现眼睛、鼻子、嘴巴之类的区域对判断有明显的作用,可以如下图所示:
从上面的图片可以看得出真脸的眼睛之类的和假脸的区别还有比较明显的。
4. Conclusion
Our experiments show that our method has an average detection rate of 98% for Deepfake videos and 95% for Face2Face videos under real conditions of diffusion on the internet.