python
目录
1 输入、输出(sys.stdout与print、sys.stdin 与 raw_input)
①sys.stdout 与 print
②sys.stdin 与 raw_input
2 strip()
3 open()
(1)参数说明:
(2)open 路径问题
(3)file 对象方法
4 with ……as
5 read()、readline()以及readlines()
①read()
②readline() 方法
③readlines() 方法
6 OS 文件/目录方法
7 split()方法
8 range()
9 异常处理
9.1 python标准异常
9.2 try/except
9.2.1 简单的try....except...else的语法:
9.2.2 使用except而不带任何异常类型
9.2.3 使用except而带多种异常类型
9.3 try-finally 语句
9.4 异常的参数
9.5 触发异常raise
9.6 用户自定义异常
9.7 assert
10 id() 函数
11 hash()
12 PIP源使用国内镜像
13 python 字符串数组互转
13.1 字符串转数组
13.2 数组转字符串
14 pass语句
15 Python中四种交换两个变量的值的方法
16 int
17 enumerate() 函数
18 continue 语句
19 return
20 闭包
21 四则运算
21.1 获取两数相除的商和余数
21.2 *与**
21.2.1 算数运算
21.2.2 函数形参
21.2.3 函数实参
21.2.4 序列解包
22 Python特殊语法:filter、map、reduce、lambda
22.1 filter
22.2 map
22.3 reduce(functools.reduce)
22.4 lambda
23 len()与count
24 random()
25 删除字典元素
25.1 clear
25.2 pop
25.3 popitem
25.4 del
26 空数组
27 Python 排序---sort与sorted学习
27.1 内建方法sort()
27.2 内建函数sorted()
28 choice() 方法
28.1 语法
29 Python input()和raw_input()的区别
29.1 raw_input()
29.2 input()
30 python定义类()中写object和不写的区别
31 Python中单引号,双引号,3个单引号及3个双引号的区别
31.1 单引号和双引号
31.2 3个单引号及3个双引号
32 Python txt文件读取写入字典的方法(json、eval)
32.1 使用json转换方法
32.2 使用str转换方法
33 format 格式化函数
33.1 实例
33.2 数字格式化
实例
34 Python 中如何获取当前位置所在的文件名,函数名,以及行号
34.1 模块sys(不推荐)
34.2 在函数外部获取函数名称(.__name__)
34.3 获取类名称
34.4 inspect模块
35 List index()方法
35.1 描述
35.2 语法
35.3 参数
35.4 返回值
35.5 实例
36 collections.defaultdict()
36.1 default_factory为list
36.1.1 collections.defaultdict
36.1.2 dict.setdefault()
36.2 default_factory为int
36.3 default_factory为set
37 items() 方法
37.1 描述
37.2 语法
37.3 参数
37.4 返回值
37.5 实例
38 Python格式化字符串(格式化输出)
39 zip
40 pickle
40.1 序列化和反序列化
40.2 序列化操作
40.2.1 pickle.dump()
40.2.2 pickle.dumps()
40.2.3 Pickler(file, protocol).dump(obj)
40.3 反序列化操作
40.3.1 pickle.load()
40.3.2 pickle.loads()
40.3.3 Unpickler(file).load()
41 变量赋值
41.1 赋值
41.1 共享引用
41.2 多目标赋值(多重赋值)及共享引用
41.2.1 不可变对象
41.2.2 可变对象
41.3 增强赋值及共享引用
41.3.1 概述
41.3.2 优点
41.3.3 共享引用
41.4 多元赋值
42 Pythonzhi直接赋值、浅拷贝和深度拷贝解析
43 python 变量作用域及其陷阱
43.1 可变对象 & 不可变对象
43.2 函数值传递
43.3 为什么修改全局的dict变量不用global关键字
43.4 可变对象 list 的 = 和 append/extend 差别在哪?
43.5 陷阱:使用可变的默认参数
44 Python中的exec()、eval()、complie()
44.1 eval函数
44.2 exec函数
44.2.1 exec函数介绍
44.2.2 在Python2 和Python3中的exec() 的区别
44.2.3 eval()函数与exec()函数的区别
44.3 compile函数
44.4 globals()与locals()函数
44.5 几个函数的关系
45 python2和python3中“/”和“//”的区别
46 Python 运算符
46.1 位运算符
46.2 逻辑运算符
46.3 身份运算符
46.4 运算符优先级
python内置函数:http://www.runoob.com/python/python-built-in-functions.html
1 输入、输出(sys.stdout与print、sys.stdin 与 raw_input)
①sys.stdout 与 print
当我们在 Python 中打印对象调用 print obj 时候,事实上是调用了 sys.stdout.write(obj+'\n')
print 将你需要的内容打印到了控制台,
以下两行在事实上等价:
sys.stdout.write('hello'+'\n')
print 'hello'然后追加了一个换行符
print 会调用 sys.stdout 的 write 方法
②sys.stdin 与 raw_input
当我们用 raw_input('Input promption: ') 时,事实上是先把提示信息输出,然后捕获输入
以下两组在事实上等价:
hi=raw_input('hello? ')
print 'hello? ', #comma to stay in the same line
hi=sys.stdin.readline()[:-1] # -1 to discard the '\n' in input stream2 strip()
描述
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法
strip()方法语法:
str.strip([chars]);参数
- chars -- 移除字符串头尾指定的字符序列。当参数为空的时候,两端的空白符,\r,\n,\t都被删除了,
返回值
返回移除字符串头尾指定的字符序列生成的新字符串。
实例(Python 3.0+)
#!/usr/bin/python3
str = "123abcrunoob321"
print (str.strip( '12' )) # 字符序列为 12
3abcrunoob3lstrip()和rstrip() :
这两个函数和上面的strip()基本是一样的,参数结构也一样,只不过一个是去掉左边的(头部),一个是去掉右边的(尾部)。
3 open()
文本文件的所有数据输入或数据输出都必须是字符串。
http://www.runoob.com/python/python-func-open.html
python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
open(name[, mode[, buffering]])(1)参数说明:
-
name : 一个包含了你要访问的文件名称的字符串值。
-
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
-
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
(2)open 路径问题
注:我们常用’/‘来表示相对路径,’\‘来表示绝对路径,上面的路径里\\是转义的意思(3也可以写成open(r'D:\user\ccc.txt'),r表示转义),不懂的自行百度。
此外,网页网址和Linux、unix系统下一般都用’/‘
Windows系统文件路径中的斜线符号为'\'。这就引出了转义字符的概念,需要在字符中使用特殊字符时,python用反斜杠’\’转义字符,改正的方法有两种:第一、将’\’的方向反向为’/’,即文首正确的写法;第二、在含有转义符的字符串前加‘r’表示字符串内按原始含义解释,不做转义处理。
①open一个同py文件同一个目录的文件的时候,用以下:
txt = open('filtered_words.txt','rb')
②绝对路径
txt = open('E:\\python_project\\test\github\\filtered_words.txt','rb')
或者
txt = open('E:/python_project/test/github/filtered_words.txt','rb')
或者
f = open(r'D:\test.txt','r')
打开文件后,可以通过 f.write() 将文本写入到文件中,文件方法write 接受字符串作为参数。当所有的输入完成后,用过使用 f.close() 来关闭文件。如果没有能够成功地关闭输出的文件,将会导致数据丢失。
f.write("first line.\nsecond line.\n")
f.close()
(3)file 对象方法
read、readline、readlines具体见 5、read()、readline()以及readlines()
file.read([size]) size未指定则返回整个文件,如果文件大小>2倍内存则有问题.f.read()读到文件尾时返回""(空字串)
file.readline() 返回一行
file.readlines([size]) 返回包含size行的列表,size 未指定则返回全部行
for line in f: print line #通过迭代器访问
f.write("hello\n") #如果要写入字符串以外的数据,先将他转换为字符串.
f.tell() 返回一个整数,表示当前文件指针的位置(就是到文件头的比特数).
f.seek(偏移量,[起始位置]) 用来移动文件指针.
- 偏移量:单位:比特,可正可负
- 起始位置:0-文件头,默认值;1-当前位置;2-文件尾
f.close() 关闭文件
实例:
f = open("myfile.txt",'w')
f.write("first line.\nsecond line.\n")
f.close()
f = open("myfile.txt",'r')
for line in f:
print(line)结果:
first line.
second line.注意:print 似乎输出了一个额外的换行。这是因为从文件输入的每一行文本,都包含一个换航字符。
接上例:
f = open("myfile.txt",'r')
while True:
line = f.readline()
if line == "":
break
print(line)结果:
first
second注意:readline 方法只读取一行的输入并且返回该字符串,包括换行符。如果readline遇到了文件的末尾,它会返回空字符串。本例中“first”和“second”中间还有一行空行,是因为 print 输出时默认的以换行为结尾,将其改成 print(line, end=""),中间空行消失。
4 with ……as
https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonwith/
with 语句的语法格式
| 1 2 |
|
使用 with 语句操作文件对象。Python 对一些内建对象进行改进,加入了对上下文管理器的支持,可以用于 with 语句中,比如可以自动关闭文件、线程锁的自动获取和释放等。
| 1 2 3 4 |
|
这里使用了 with 语句,不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭了打开的文件句柄。如果使用传统的 try/finally 范式,则要使用类似如下代码:
清单1. try/finally 方式操作文件对象
| 1 2 3 4 5 6 7 |
|
比较起来,使用 with 语句可以减少编码量。已经加入对上下文管理协议支持的还有模块 threading、decimal 等。
PEP 0343 对 with 语句的实现进行了描述。with 语句的执行过程类似如下代码块:
清单 2. with 语句执行过程
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
- 执行 context_expression,生成上下文管理器 context_manager
- 调用上下文管理器的 __enter__() 方法;如果使用了 as 子句,则将 __enter__() 方法的返回值赋值给 as 子句中的 target(s)
- 执行语句体 with-body
- 不管是否执行过程中是否发生了异常,执行上下文管理器的 __exit__() 方法,__exit__() 方法负责执行“清理”工作,如释放资源等。如果执行过程中没有出现异常,或者语句体中执行了语句 break/continue/return,则以 None 作为参数调用 __exit__(None, None, None) ;如果执行过程中出现异常,则使用 sys.exc_info 得到的异常信息为参数调用 __exit__(exc_type, exc_value, exc_traceback)
- 出现异常时,如果 __exit__(type, value, traceback) 返回 False,则会重新抛出异常,让with 之外的语句逻辑来处理异常,这也是通用做法;如果返回 True,则忽略异常,不再对异常进行处理
5 read()、readline()以及readlines()
Python File(文件) 方法:http://www.runoob.com/python/file-methods.html
read()、readline()以及readlines()的区别:
read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。.readline() 和 .readlines() 非常相似,.readline() 和 .readlines() 之间的差异是后者一次读取整个文件,像 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。另一方面,.readline() 每次只读取一行,通常比 .readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 .readline()。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
①read()
概述
read() 方法用于从文件读取指定的字节数,如果未给定或为负则读取所有。
语法
read() 方法语法如下:
fileObject.read(); 参数
-
size -- 从文件中读取的字节数。
返回值
返回从字符串中读取的字节。
# 打开文件
fo = open("runoob.txt", "rw+")
print ("文件名为: ", fo.name)
line = fo.read(10)
print ("读取的字符串: %s" % (line))
# 关闭文件
fo.close()②readline() 方法
概述
readline() 方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符。
语法
readline() 方法语法如下:
fileObject.readline(); 参数
-
size -- 从文件中读取的字节数。
返回值
返回从字符串中读取的字节。
# 打开文件
fo = open("runoob.txt", "rw+")
print ("文件名为: ", fo.name)
line = fo.readline()
print ("读取第一行 %s" % (line))
line = fo.readline(5)
print ("读取的字符串为: %s" % (line))
# 关闭文件
fo.close()③readlines() 方法
概述
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行处理。
如果碰到结束符 EOF 则返回空字符串。
语法
readlines() 方法语法如下:
fileObject.readlines( );参数
-
无。
返回值
返回列表,包含所有的行。
# 打开文件
fo = open("runoob.txt", "r")
print ("文件名为: ", fo.name)
for line in fo.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
print ("读取的数据为: %s" % (line))
# 关闭文件
fo.close()运行字符串方法 strip 来删除换行符。
6 OS 文件/目录方法
http://www.runoob.com/python3/python3-os-file-methods.html
| os.chdir(path) |
| os.chroot(path) 改变当前进程的根目录 |
| os.getcwd() 返回当前工作目录 |
os.listdir(path)返回指定目录下的所有文件和目录名。
os.remove(path)函数用来删除一个文件。
import os
path = os.path.abspath(__file__)
path2 = os.path.dirname(__file__)
path3 = os.path.dirname(os.path.abspath(__file__))
path4 = os.path.split(path3)[0]
path5 = os.path.join(path4, "test\\ogf", "inog")
print(path)
print(path2)
print(path3)
print(path4)
print(path5)
#输出:
D:\PycharmProjects\chandao\test_case\testexcel.py
D:/PycharmProjects/chandao/test_case
D:\PycharmProjects\chandao\test_case
D:\PycharmProjects\chandao
D:\PycharmProjects\chandao\test\ogf\inog7 split()方法
描述
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则仅分隔 num 个子字符串
语法
split() 方法语法:
str.split(str="", num=string.count(str)).参数
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。
返回值
返回分割后的字符串列表。
实例
以下实例展示了split()函数的使用方法:
#!/usr/bin/python
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( );
print str.split(' ', 1 );以上实例输出结果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']按某一字符(或字符串)分割,且分割n次,并将分割的完成的字符串(或字符)赋给新的(n+1)个变量。(注:见开头说明)
如:按‘.’分割字符,且分割1次,并将分割后的字符串赋给2个变量str1,str2
url = ('www.google.com')
str1, str2 = url.split('.', 1)
print str1
print str2结果:
www
google.com8 range()
python range() 函数可创建一个整数列表,一般用在 for 循环中。
函数语法
range(start, stop[, step])参数说明:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
e.g.
>>> range(0, 30, 5) # 步长为 5
[0, 5, 10, 15, 20, 25]
9 异常处理
http://www.runoob.com/python/python-exceptions.html
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
9.1 python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
在python的异常中,有一个万能异常:Exception,他可以捕获任意异常
9.2 try/except
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
9.2.1 简单的try....except...else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字> as <数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生try的工作原理:当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印缺省的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
实例(1):
它打开一个文件,在该文件中的内容写入内容,且并未发生异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()输出结果:
$ python test.py
内容写入文件成功
$ cat testfile # 查看写入的内容
这是一个测试文件,用于测试异常!!实例(2):
它打开一个文件,在该文件中的内容写入内容,但文件没有写入权限,发生了异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()在执行代码前为了测试方便,我们可以先去掉 testfile 文件的写权限,命令如下:
chmod -w testfile执行以上代码:
$ python test.py
Error: 没有找到文件或读取文件失败实例3(发生异常并显示错误代码)
try:
f1 = open("testfile.txt", "r")
f1.read()
except IOError as ercode:
print("Error: 没有找到文件或读取文件失败,错误代码为:" + str(ercode))
else:
print("内容写入文件成功")
f1.close()
====输出结果:====
D:\untitled\venv\Scripts\python.exe D:/untitled/Python_learn/test1.py
Error: 没有找到文件或读取文件失败,错误代码为:[Errno 2] No such file or directory: 'testfile.txt'python2与python3中raise和 except 语法的不同:
python2:
try:
..............
except Exception, e:
.........python3:
try:
..............
except Exception as e:
9.2.2 使用except而不带任何异常类型
可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
9.2.3 使用except而带多种异常类型
可以使用相同的except语句来处理多个异常信息,如下所示:
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码实例:
#一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元祖,例如:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
f1 = open("testfile.txt", "w+")
f1.read()
a = 1 / 0
except (IOError,ZeroDivisionError) as ercode:
print("发生错误了,错误代码为:" + str(ercode))
else:
print("内容写入文件成功")
f1.close()
====输出结果:====
D:\untitled\venv\Scripts\python.exe D:/untitled/Python_learn/test1.py
发生错误了,错误代码为:division by zero9.3 try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
raise实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "Error: 没有找到文件或读取文件失败"如果打开的文件没有可写权限,输出如下所示:
$ python test.py
Error: 没有找到文件或读取文件失败同样的例子也可以写成如下方式:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
try:
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "关闭文件"
fh.close()
except IOError:
print "Error: 没有找到文件或读取文件失败"当在try块中抛出一个异常,立即执行finally块代码。
finally块中的所有语句执行后,异常被再次触发,并执行except块代码。
参数的内容不同于异常。
9.4 异常的参数
一个异常可以带上参数,可作为输出的异常信息参数。
你可以通过except语句来捕获异常的参数,如下所示:
try:
正常的操作
......................
except ExceptionType as Argument:
你可以在这输出 Argument 的值...变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
实例:
以下为单个异常的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def temp_convert(var):
try:
return int(var)
except ValueError as Argument:
print "参数没有包含数字\n", Argument
# 调用函数
temp_convert("xyz");以上程序执行结果如下:
$ python test.py
参数没有包含数字
invalid literal for int() with base 10: 'xyz'9.5 触发异常raise
可以使用raise语句自己触发异常,一旦抛出异常后,后续的代码将无法运行。这实际上的将不合法的输出直接拒之门外,避免黑客通过这种试探找出我们程序的运行机制,从而找出漏洞,获得非法权限。
raise语法格式如下:
raise [Exception [, args [, traceback]]]语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例:
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:(python2)
try:
正常逻辑
except Exception as err:
触发自定义异常
else:
其余代码实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def mye( level ):
if level < 1:
raise Exception as "Invalid level!"
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception,err:
print 1,err
else:
print 2执行以上代码,输出结果为:
$ python test.py
1 Invalid level!raise
在python2中,对raise语句支持以下三种形式:
raise SomeException
raise SomeException(args)
raise SomeException, args而在python3中,raise语句支持以下两种形式:
raise SomeException
raise SomeException(args)9.6 用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg在你定义以上类后,你可以触发该异常,如下所示:
try:
raise Networkerror("Bad hostname")
except Networkerror as e:
print e.args结果:
('B', 'a', 'd', ' ', 'h', 'o', 's', 't', 'n', 'a', 'm', 'e')9.7 assert
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单。在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行中崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助。
断言的意思,解释为:我断定这个程序执行之后或者之前会有这样的结果,如果不是,那就扔出一个错误。
语法:
assert expression [, arguments]
assert 表达式 [, 参数]
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')
>Traceback (most recent call last):
...
AssertionError: n is zero!assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError。
启动Python解释器时可以用-O参数来关闭assert
10 id() 函数
描述:
id() 函数用于获取对象的内存地址。
id 语法:
id([object])参数说明:
object -- 对象。
返回值:
返回对象的内存地址。
实例:
>>>a = 'runoob'
>>> id(a)
4531887632
>>> b = 1
>>> id(b)
14058873108560811 hash()
hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
语法
hash 语法:
hash(object)参数说明:
object -- 对象
返回值:
返回对象的哈希值。
实例:
>>>hash('test') # 字符串
2314058222102390712
>>> hash(1) # 数字
1
>>> hash(str([1,2,3])) # 集合
1335416675971793195
>>> hash(str(sorted({'1':1}))) # 字典
7666464346782421378
hash() 函数可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。
在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关。相应的哈希是通过id除以16实现的。只不过,在py2中的计算是整型,而py3中的计算则是浮点数。
class Test:
def __init__(self, i):
self.i = i
for i in range(10):
t = Test(i)
print(hash(t), id(t))结果:
(277855628, 4445690048)
(277855637, 4445690192)
(277855628, 4445690048)
(277855637, 4445690192)
(277855628, 4445690048)
(277855637, 4445690192)
(277855628, 4445690048)
(277855637, 4445690192)
(277855628, 4445690048)
(277855637, 4445690192)https://blog.csdn.net/cmzsteven/article/details/65628789
12 PIP源使用国内镜像
修改源
国内源(新版ubuntu要求使用https源,要注意。):
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣:http://pypi.douban.com/simple/
临时使用:
可以在使用pip的时候加参数-i https://pypi.tuna.tsinghua.edu.cn/simple
例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider,这样就会从清华这边的镜像去安装pyspider库。
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip,会更新pip
查看pip版本:pip -V
13 python 字符串数组互转
13.1 字符串转数组
①str = '1,2,3'
arr = str.split(',')
②
str1 = 'abcde'
str2 = 'a b c d e'
str3 = 'a, b, c, d, e'
result1 = list(str1)
result2 = str2.split()
result3 = str3.split(', ')
print(result1)
print(result2)
print(result3)结果:
['a', 'b', 'c', 'd', 'e']
['a', 'b', 'c', 'd', 'e']
['a', 'b', 'c', 'd', 'e']
13.2 数组转字符串
可以使用str字符串中的字符来连接join()中的list
语法: ‘sep’.join(seq)
参数说明:
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典
①
>>> a
['H', 'e', 'llo']
>>> b=''.join(a)
>>> b
'Hello'
>>> c='-'.join(a)
>>> c
'H-e-llo'
>>> d='*'
>>> e=d.join(a)
>>> e
'H*e*llo'② 但是当list中存放的数据是整型数据或者数字的话,需要先将数据转换为字符串再进行转换:
list = [1, 2, 3, 4]
str1 = ''.join([str(x) for x in list])
str2 = ' '.join([str(x) for x in list])
str3 = '.'.join([str(x) for x in list])
print(str1)
print(str2)
print(str3)
结果:
1234
1 2 3 4
1.2.3.4
14 pass语句
Python pass是一个空语句,它不做任何事情,一般只用做占位语句,目的是为了保持程序结构的完整性。
实例演示:
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
for letter in 'Python':
if letter == 'h':
pass
print('这是与pass同级的内容')
print('当前字母 :', letter)输出:
当前字母 : P
当前字母 : y
当前字母 : t
这是与pass同级的内容
当前字母 : h
当前字母 : o
当前字母 : n
15 Python中四种交换两个变量的值的方法
方法一:(所有语言都可以通过这种方式进行交换变量)
通过新添加中间变量的方式,交换数值.
def demo1(a,b):
temp = a
a = b
b = temp
print(a,b)方法二:(此方法是Python中特有的方法)
直接将a, b两个变量放到元组中,再通过元组按照index进行赋值的方式进行重新赋值给两个变量。
def demo2(a,b):
a,b = b,a
print(a,b)方法三:
通过简单的逻辑运算进行将两个值进行互换
def demo3(a, b):
a = a + b
b = a - b
a = a - b
print(a, b)方法四:
通过异或运算 将两个值互换 异或运算的原理是根据二进制中的 "1^1=0 1^0=1 0^0=0"
def demo4(a,b):
a = a^b
b = a^b # b = (a^b)^b = a
a = a^b # a = (a^b)^a = b
print(a,b)^按位异或运算符:当两对应的二进位相异时,结果为1
例如:
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = a ^ b; # 49 = 0011 0001
16 int
int() 函数用于将一个字符串或数字转换为整型。
语法: class int(x, base=10)
参数
- x -- 字符串或数字。
- base -- 进制数,默认十进制。
返回值:返回整型数据。
>>>int() # 不传入参数时,得到结果0
0
>>> int(3)
3
>>> int(3.6)
3
>>> int('12',16) # 如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制
18
>>> int('0xa',16)
10
>>> int('10',8)
817 enumerate() 函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
语法:
enumerate(sequence, [start=0])参数:
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置。
返回值:
返回 enumerate(枚举) 对象。
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons))结果:
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]数组中两个数之和等于给定的数:
方法一:取数组内的两个数,用两层for循环进行遍历求和,简单实用。
def get_array_indices_1(integers_array, target_num):
for i, index_i in enumerate(integers_array):
for j, index_j in enumerate(integers_array[i + 1:]):
if index_i + index_j == target_num:
return [i, i + 1 + j]方法二:得到一个数之后,检查另外一个数(给定数-已得数)是否在数组内,如果在,则得到了这两个数。
def get_array_indices_2(integers_array, target_num):
for i, index_i in enumerate(integers_array):
index_j = target_num - index_i
integers_array_j = integers_array[i + 1:]
if index_j in integers_array_j:
return [i, i + 1 + integers_array_j.index(index_j)](方法二对比方法一,减化了第二个循环阶段中的加减运算)
注:使用 .index() 获取列表内元素下标,如果多个同样的元素,仅返回该列表中的第一个元素的下标。为获取多个元素,需使用enumerate()方法,其会返回一个由列表内各个下标与元素元组构成的数组。这里根据题设只有唯一解,则最多只有两个相同元素,且都是解的一部分,即i和j,所以直接从分割后数组内的取元素下标(重复的另一个同样解在另一半数组内)即可。
方法三:通过调整算法的时间复杂度(Hash表 )或空间复杂度(bitmap方法),进一步对算法进行优化。
def get_array_indices_3(integers_array, target_num):
integers_dict = {index_n : n for n, index_n in enumerate(integers_array)}
for k in integers_dict.keys():
if (target_num - k) in integers_dict:
return [integers_dict[k], integers_dict[target_num - k]]Hash,一般翻译做“散列”,就是把任意长度的输入,通过散列算法,变换成固定长度的输出。
在Python中,字典是通过哈希表实现的,通常字典也被认为是可变的哈希表,是该语言中唯一的映射类型。
字典创建了两个数组,一个数组下放key,另一个数组下放对应的value。实现集合的方式叫做Hash Set,实现字典的方式叫做Hash Map/Table。(注:Map指的就是通过key来寻找value的过程)
在字典中,key是唯一的值,如以元素作为key,当遇到两个相同元素时,则只保存最后记录元素的下标。
可先对这个特殊的情况(解是不同下标的两个相同元素)进行处理:
def check_double(integers_array, target_num):
for i, index_i in enumerate(integers_array):
if integers_array.count(index_i) == 2 and index_i * 2 == target_num:
return [d for d, index_d in enumerate(integers_array) if index_d == index_i]18 continue 语句
continue 语句跳出本次循环,而break跳出整个循环。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。
continue 语句是一个删除的效果,他的存在是为了删除满足循环条件下的某些不需要的成分:
例如:只打印0-10之间的奇数,可以用continue语句跳过某些循环:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)19 return
return 语句就是讲结果返回到调用的地方,并把程序的控制权一起返回
程序运行到所遇到的第一个return即返回(退出def块),不会再运行第二个return。
(1)例1:在 try 中 raise一个异常,就立刻转入 except 中执行,在except 中遇到 return 时,就强制转到 finally 中执行, 在 finally 中遇到 return 时就返回。
def test1():
try:
print('to do stuff')
raise Exception('hehe')
print('to return in try')
return 'try'
except Exception:
print('process except')
print('to return in except')
return 'except'
finally:
print('to return in finally')
return 'finally'
test1Return = test1()
print('test1Return : ' + test1Return)输出:
to do stuff
process except
to return in except
to return in finally
test1Return : finally
例2:这里在 try 中没有抛出异常,因此不会转到 except 中,但是在try 中遇到return时,也会立即强制转到finally中执行,并在finally中返回。
def test2():
try:
print('to do stuff')
print('to return in try')
return 'try'
except Exception:
print('process except')
print('to return in except')
return 'except'
finally:
print('to return in finally')
return 'finally'
test2Return = test2()
print('test1Return : ' + test2Return)输出:
to do stuff
to return in try
to return in finally
test2Return : finally
test1和test2得到的结论:
无论是在try还是在except中,遇到return时,只要设定了finally语句,就会中断当前的return语句,跳转到finally中执行,如果finally中遇到return语句,就直接返回,不再跳转回try/excpet中被中断的return语句。
(3)例3:
def test3():
i = 0
try:
i += 1
print('i in try : %s'%i)
raise Exception('hehe')
except Exception:
i += 1
print('i in except : %s'%i)
return i
finally:
i += 1
print ('i in finally : %s'%i )
print('test3Return : %s'% test3())输出:
i in try : 1
i in except : 2
i in finally : 3
test3Return : 2例4:
def test4():
i = 0
try:
i += 1
return i
finally:
i += 1
print ('i in finally : %s'%i )
print('test4Return : %s' % test4())输出:
i in finally : 2
test4Return : 1test3和test4得到的结论:
在except和try中遇到return时,会锁定return的值,然后跳转到finally中,如果finally中没有return语句,则finally执行完毕之后仍返回原return点,将之前锁定的值返回(即finally中的动作不影响返回值),如果finally中有return语句,则执行finally中的return语句。
(3)例5:
def test5():
for i in range(5):
try:
print('do stuff %s'%i)
raise Exception(i)
except Exception:
print('exception %s'%i)
continue
finally:
print('do finally %s'%i)
test5()输出:
do stuff 0
exception 0
do finally 0
do stuff 1
exception 1
do finally 1
do stuff 2
exception 2
do finally 2
do stuff 3
exception 3
do finally 3
do stuff 4
exception 4
do finally 4test5得到的结论: 在一个循环中,最终要跳出循环之前,会先转到finally执行,执行完毕之后才开始下一轮循环。
20 闭包
(1)闭包简介
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
例如:
#闭包函数的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer( a ):
b = 10
# inner是内函数
def inner():
#在内函数中 用到了外函数的临时变量
print(a+b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
# 在这里我们调用外函数传入参数5
#此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo
# 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数
demo = outer(5)
# 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量
# demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数
demo() # 15
demo2 = outer(7)
demo2()#17当我们进行a=1的时候,实际上在内存当中有一个地方存了值1,然后用a这个变量名存了1所在内存位置的引用。引用就好像c语言里的指针,大家可以把引用理解成地址。a只不过是一个变量名字,a里面存的是1这个数值所在的地址,就是a里面存了数值1的引用。
相同的道理,当我们在python中定义一个函数def demo(): 的时候,内存当中会开辟一些空间,存下这个函数的代码、内部的局部变量等等。这个demo只不过是一个变量名字,它里面存了这个函数所在位置的引用而已。我们还可以进行x = demo, y = demo, 这样的操作就相当于,把demo里存的东西赋值给x和y,这样x 和y 都指向了demo函数所在的引用,在这之后我们可以用x() 或者 y() 来调用我们自己创建的demo() ,调用的实际上根本就是一个函数,x、y和demo三个变量名存了同一个函数的引用。
对于闭包,在外函数outer中 最后return inner,我们在调用外函数 demo = outer() 的时候,outer返回了inner,inner是一个函数的引用,这个引用被存入了demo中。所以接下来我们再进行demo() 的时候,相当于运行了inner函数。
同时我们发现,一个函数,如果函数名后紧跟一对括号,相当于现在我就要调用这个函数,如果不跟括号,相当于只是一个函数的名字,里面存了函数所在位置的引用。
(2)修改外函数变量
在闭包内函数中,我们可以随意使用外函数绑定来的临时变量,但是如果我们想修改外函数临时变量数值的时候发现出问题了。在基本的python语法当中,一个函数可以随意读取全局数据,但是要修改全局数据的时候有两种方法:1 global 声明全局变量; 2 全局变量是可变类型数据的时候可以修改
在闭包内函数也是类似的情况。在内函数中想修改闭包变量(外函数绑定给内函数的局部变量)的时候:
1 在python3中,可以用nonlocal 关键字声明 一个变量, 表示这个变量不是局部变量空间的变量,需要向上一层变量空间找这个变量。
2 在python2中,没有nonlocal这个关键字,我们可以把闭包变量改成可变类型数据进行修改,比如列表。
例如:
#修改闭包变量的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer( a ):
b = 10 # a和b都是闭包变量
c = [a] #这里对应修改闭包变量的方法2
# inner是内函数
def inner():
#内函数中想修改闭包变量
# 方法1 nonlocal关键字声明
nonlocal b
b+=1
# 方法二,把闭包变量修改成可变数据类型 比如列表
c[0] += 1
print(c[0])
print(b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
demo = outer(5)
demo() # 6 11从上面代码中我们能看出来,在内函数中,分别对闭包变量进行了修改,打印出来的结果也确实是修改之后的结果。以上两种方法就是内函数修改闭包变量的方法。
(3)每次开启内函数都在使用同一份闭包变量
还有一点需要注意:使用闭包的过程中,一旦外函数被调用一次返回了内函数的引用,虽然每次调用内函数,是开启一个函数执行过后消亡,但是闭包变量实际上只有一份,每次开启内函数都在使用同一份闭包变量。
#coding:utf8
def outer(x):
def inner(y):
nonlocal x
x+=y
return x
return inner
a = outer(10)
print(a(1)) //11
print(a(3)) //14两次分别打印出11和14,由此可见,每次调用inner的时候,使用的闭包变量x实际上是同一个。
(4)
程序:
for i in range(3):
print i 在程序里面经常会出现这类的循环语句,Python的问题就在于,当循环结束以后,循环体中的临时变量i不会销毁,而是继续存在于执行环境中。还有一个python的现象是,python的函数只有在执行时,才会去找函数体里的变量的值。
例如:
flist = []
for i in range(3):
def foo(x): print (x + i)
flist.append(foo)
for f in flist:
f(2)
# 3
# 3
# 3 可能有些人认为这段代码的执行结果应该是2,3,4,但是实际的结果是4,4,4。这是因为当把函数加入flist列表里时,python还没有给i赋值,只有当执行时,再去找i的值是什么,这时在第一个for循环结束以后,i的值是2,所以以上代码的执行结果是4,4,4.
解决方法也很简单,改写一下函数的定义就可以了。
flist = []
for i in range(3):
def foo(x,y=i): print (x + y)
flist.append(foo)
for f in flist:
f(2)
# 2
# 3
# 421 四则运算
21.1 获取两数相除的商和余数
方法一:可以使用//求取两数相除的商、%求取两数相除的余数。[/在Python中获取的是相除的结果,一般为浮点数]
方法二:使用divmod()函数,获取商和余数组成的元祖
#!/usr/bin/python3
# -*- coding: utf-8 -*-
a = int(input(u"输入被除数: "))
b = int(input(u"输入除数:"))
div = a // b
mod = a % b
print("{} / {} = {} ... {}".format(a, b, div, mod))
print("{} / {} = {} ... {}".format(a, b, *divmod(a, b)))21.2 *与**
21.2.1 算数运算
* 代表乘法
** 代表乘方
>>> 2 * 5
10
>>> 2 ** 5
32
21.2.2 函数形参
*args 和 **kwargs 主要用于函数定义。
可以将不定数量的参数传递给一个函数。不定的意思是:预先并不知道, 函数使用者会传递多少个参数给你, 所以在这个场景下使用这两个关键字。其实并不是必须写成 *args 和 **kwargs。 *(星号) 才是必须的. 你也可以写成 *ar 和 **k 。而写成 *args 和**kwargs 只是一个通俗的命名约定。
python函数传递参数的方式有两种:
- 位置参数(positional argument)
- 关键词参数(keyword argument)
*args 与 **kwargs 的区别,两者都是 python 中的可变参数:
- *args 表示任何多个无名参数,它本质是一个 tuple,往函数中以列表和元组的形式传参数
- **kwargs 表示关键字参数,它本质上是一个 dict,传入字典的值作为关键词参数
如果同时使用 *args 和 **kwargs 时,必须 *args 参数列要在 **kwargs 之前。
>>> def fun(*args, **kwargs):
... print('args=', args)
... print('kwargs=', kwargs)
...
>>> fun(1, 2, 3, 4, A='a', B='b', C='c', D='d')
args= (1, 2, 3, 4)
kwargs= {'A': 'a', 'B': 'b', 'C': 'c', 'D': 'd'}
示例:
def f(*args,**kwargs):
print args, kwargs
l = [1,2,3]
t = (4,5,6)
d = {'a':7,'b':8,'c':9}
f()
f(1,2,3) # (1, 2, 3) {}
f(1,2,3,"groovy") # (1, 2, 3, 'groovy') {}
f(a=1,b=2,c=3) # () {'a': 1, 'c': 3, 'b': 2}
f(a=1,b=2,c=3,zzz="hi") # () {'a': 1, 'c': 3, 'b': 2, 'zzz': 'hi'}
f(1,2,3,a=1,b=2,c=3) # (1, 2, 3) {'a': 1, 'c': 3, 'b': 2}
f(*l,**d) # (1, 2, 3) {'a': 7, 'c': 9, 'b': 8}
f(*t,**d) # (4, 5, 6) {'a': 7, 'c': 9, 'b': 8}
f(1,2,*t) # (1, 2, 4, 5, 6) {}
f(q="winning",**d) # () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f(1,2,*t,q="winning",**d) # (1, 2, 4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
def f2(arg1,arg2,*args,**kwargs):
print arg1,arg2, args, kwargs
f2(1,2,3) # 1 2 (3,) {}
f2(1,2,3,"groovy") # 1 2 (3, 'groovy') {}
f2(arg1=1,arg2=2,c=3) # 1 2 () {'c': 3}
f2(arg1=1,arg2=2,c=3,zzz="hi") # 1 2 () {'c': 3, 'zzz': 'hi'}
f2(1,2,3,a=1,b=2,c=3) # 1 2 (3,) {'a': 1, 'c': 3, 'b': 2}
f2(*l,**d) # 1 2 (3,) {'a': 7, 'c': 9, 'b': 8}
f2(*t,**d) # 4 5 (6,) {'a': 7, 'c': 9, 'b': 8}
f2(1,2,*t) # 1 2 (4, 5, 6) {}
f2(1,1,q="winning",**d) # 1 1 () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f2(1,2,*t,q="winning",**d) # 1 2 (4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}21.2.3 函数实参
如果函数的形参是定长参数,也可以使用 *args 和 **kwargs 调用函数,类似对元组和字典进行解引用:
>>> def fun(data1, data2, data3):
... print("data1: ", data1)
... print("data2: ", data2)
... print("data3: ", data3)
...
>>> args = ("one", 2, 3)
>>> fun(*args)
data1: one
data2: 2
data3: 3
>>> kwargs = {"data3": "one", "data2": 2, "data1": 3}
>>> fun(**kwargs)
data1: 3
data2: 2
data3: one
21.2.4 序列解包
序列解包没有 **。可以利用 * 表达式获取单个变量中的多个元素,只要它的解释没有歧义即可。* 获取的值默认为 list。
(1)# 获取剩余部分:
>>> a, b, *c = 0, 1, 2, 3
>>> a
0
>>> b
1
>>> c
[2, 3]
(2)# 获取中间部分:
>>> a, *b, c = 0, 1, 2, 3
>>> a
0
>>> b
[1, 2]
>>> c
3
(3)# 如果左值比右值要多,那么带 * 的变量默认为空
>>> a, b, *c = 0, 1
>>> a
0
>>> b
1
>>> c
[]
>>> a, *b, c = 0, 1
>>> a
0
>>> b
[]
>>> c
1
(4)嵌套解包
>>> (a, b), (c, d) = (1, 2), (3, 4)
>>> a
1
>>> b
2
>>> c
3
>>> d
4
>>> a, b, c, d
(1, 2, 3, 4)
例如,假如一个字符串 'ABCDEFGH',要输出下列格式:
A ['B', 'C', 'D', 'E', 'F', 'G', 'H']
B ['C', 'D', 'E', 'F', 'G', 'H']
C ['D', 'E', 'F', 'G', 'H']
D ['E', 'F', 'G', 'H']
E ['F', 'G', 'H']
F ['G', 'H']
G ['H']
H []
即每次取出第一个作为首,然后的字符串拆成列表,放置在后面
一般的处理过程是:
1. 将切片中索引为 0 的字符赋值给 a
2. 将切片中索引为 1 之后字符再赋值给 s
3. 用 list 函数将字符串转变为列表
4. 用 while 循环来 s 来判断,为空,则退出循环
>>> s = 'ABCDEFGH'
>>> while s:
... x, s = s[0], list(s[1:])
... print(x, s)
...
A ['B', 'C', 'D', 'E', 'F', 'G', 'H']
B ['C', 'D', 'E', 'F', 'G', 'H']
C ['D', 'E', 'F', 'G', 'H']
D ['E', 'F', 'G', 'H']
E ['F', 'G', 'H']
F ['G', 'H']
G ['H']
H []
上面的处理,可以用序列解包的方法会来处理。
>>> s = 'ABCDEFGH'
>>> while s:
... x, *s = s
... print(x, s)
...
A ['B', 'C', 'D', 'E', 'F', 'G', 'H']
B ['C', 'D', 'E', 'F', 'G', 'H']
C ['D', 'E', 'F', 'G', 'H']
D ['E', 'F', 'G', 'H']
E ['F', 'G', 'H']
F ['G', 'H']
G ['H']
H []
22 Python特殊语法:filter、map、reduce、lambda
22.1 filter
filter(function, sequence):
ilter(函数,序列)函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
对sequence中的item依次执行function(item),将执行结果为True的item组成一个List/String/Tuple(取决于sequence的类型)返回。function的返回值只能是True或False。把sequence中的值逐个当参数传给function,如果function(x)的返回值是True,就把x加到filter的返回值里面。一般来说filter的返回值是list,特殊情况如sequence是string或tuple,则返回值按照sequence的类型。
>>> def f(x): return x % 2 != 0 and x % 3 != 0
>>> filter(f, range(2, 25))
[5, 7, 11, 13, 17, 19, 23]
>>> def f(x): return x != 'a'
>>> filter(f, "abcdef")
'bcdef'找出1到10之间的奇数:
filter(lambda x:x%2!=0,range(1,11))返回值:[1,3,5,7,9]
22.2 map
map(function, sequence) :对sequence中的item依次执行function(item),见执行结果组成一个List返回。
>>> def cube(x): return x*x*x
>>> map(cube, range(1, 11))
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]另外map也支持多个sequence,这就要求function也支持相应数量的参数输入:
>>> def add(x, y): return x+y
>>> map(add, range(8), range(8))
[0, 2, 4, 6, 8, 10, 12, 14]
>>> b=map(lambda a,b:a+b,range(1,5),range(3,7))
>>> c=[x for x in b ]
>>> c
[4, 6, 8, 10]求1*1,2*2,3*3,4*4:
map(lambda x:x*x,range(1,5))返回值是[1,4,9,16]。
22.3 reduce(functools.reduce)
reduce(function, sequence, starting_value):对sequence中的item顺序迭代调用function,如果有starting_value,还可以作为初始值调用。function接收的参数个数只能为2。先把sequence中第一个值和第二个值当参数传给function,再把function的返回值和第三个值当参数传给function,然后只返回一个结果。
例如可以用来对List求和:
>>> import functools
>>> def add(x,y): return x + y
>>> functools.reduce(add, range(1, 11))
55 (注:1+2+3+4+5+6+7+8+9+10)
>>> reduce(add, range(1, 11), 20)
75 (注:1+2+3+4+5+6+7+8+9+10+20)求1到10的累加:
reduce(lambda x,y:x+y,range(1,11))返回值是55。
22.4 lambda
Python使用lambda来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
这是Python支持一种有趣的语法,它允许你快速定义单行的最小函数,类似与C语言中的宏,这些叫做lambda的函数,是从LISP借用来的,可以用在任何需要函数的地方。lambda表达式返回一个函数对象。Python 要求 lambda 表达式只能是单行表达式。
lambda 表达式的语法格式如下:
lambda [parameter_list] : 表达式
从上面的语法格式可以看出 lambda 表达式的几个要点:
- lambda 表达式必须使用 lambda 关键字定义。
- 在 lambda 关键字之后、冒号左边的是参数列表,可以没有参数,也可以有多个参数。如果有多个参数,则需要用逗号隔开,冒号右边是该 lambda 表达式的返回值。
例如:
func = lambda x,y:x+y
func相当于下面这个函数
def func(x,y):
return x+y23 len()与count
len():返回对象的长度,注意不是length()函数
len([1,2,3]),返回值为3
len([[1,2,3],[3,4,5]]),返回值为2
count():计算包含对象个数
[1,1,1,2].count(1),返回值为3
‘asddf’.count(‘d’),返回值为2
24 random()
import random
random.random()random.random() 方法返回随机生成的一个实数,它在[0,1)范围内。
在python中的random.randint(a,b)用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice('tomorrow') ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
a=[1,3,5,6,7] # 将序列a中的元素顺序打乱
random.shuffle(a)
print(a)25 删除字典元素
25.1 clear
Python字典的clear()方法(删除字典内所有元素)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
dict = {'name': '我的博客地址', 'alexa': 10000, 'url': 'http://baaaaa'}
dict.clear(); # 清空词典所有条目
25.2 pop
pop( key [, default ]),从字典中删除键,并返回映射值。若键不存在,则返回default,未指定default参数时则会出错。
Python字典的pop()方法(删除字典给定键 key 所对应的值,返回值为被删除的值)。
site= {'name': '我的博客地址', 'alexa': 10000, 'url':'http://aaaaaa'}
pop_obj=site.pop('name') # 删除要删除的键值对,如{'name':'我的博客地址'}这个键值对
print pop_obj # 输出 :我的博客地址
注:与列表的pop删除不同,列表的pop用法:pop()方法可删除指定位置的对象,省略位置时删除列表最后一个对象,同时返回删除对象。例如:
>>>x=[1,2,3,4]
>>>x.pop()
4
>>>x
[1, 2, 3]
>>>x.pop(1)
2
>>>x
[1, 3]25.3 popitem
Python字典的popitem()方法(随机返回并删除字典中的一对键和值)。空字典调用该方法会产生KeyError错误。
site= {'name': '我的博客地址', 'alexa': 10000, 'url':'http://aaa'}
pop_obj=site.popitem() # 随机返回并删除一个键值对
print pop_obj # 输出结果可能是{'url','http://aaa'}
25.4 del
全局方法,(能删单一的元素也能清空字典,清空只需一项操作)
site= {'name': '我的博客地址', 'alexa': 10000, 'url':'http://aaa'}
del site['name'] # 删除键是'name'的条目
del site # 清空字典所有条目26 空数组
>>>a=[None]
>>>b=a*3
>>>b
[None, None, None]
>>>a=[[None]]
>>>b=a*3
>>>b
[[None], [None], [None]]
>>>b=[[None]*3]
>>>b
[[None, None, None]]
>>>a=[]
>>>b=a*3
>>>b
[]
>>>a=[[]]
>>>b=a*3
>>>b
[[], [], []]
27 Python 排序---sort与sorted学习
27.1 内建方法sort()
可以直接对列表进行排序。默认为升序。
用法:
list.sort(func=None, key=None, reverse=False(or True))
- 对于reverse这个bool类型参数,当reverse=False时,为正向排序;当reverse=True时,为方向排序。默认为False。
- 执行完后会改变原来的list,如果你不需要原来的list,这种效率稍微高点
- 为了避免混乱,其会返回none
>>> list = [2,8,4,6,9,1,3]
>>> list.sort()
>>> list
[1, 2, 3, 4, 6, 8, 9]27.2 内建函数sorted()
这个和第一种的差别之处在于:
- sorted()不会改变原来的list,而是会返回一个新的已经排序好的list
- list.sort()方法仅仅被list所定义,sorted()可用于任何一个可迭代对象
用法:
sorted(iterable, cmp=None, key=None, reverse=False)
- 该函数也含有reverse这个bool类型的参数,当reverse=False时:为正向排序(从小到大);当reverse=True时:为反向排序(从大到小)。当然默认为False。
- 执行完后会有返回一个新排序好的list
- iterable:是可迭代类型;
cmp:用于比较的函数,比较什么由key决定;
key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则。reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:是一个经过排序的可迭代类型,与iterable一样。 -
参数说明:
(1) cmp参数
cmp接受一个函数,拿整型举例,形式为:
def f(a,b):
return a-b
如果排序的元素是其他类型的,如果a逻辑小于b,函数返回负数;a逻辑等于b,函数返回0;a逻辑大于b,函数返回正数就行了。
(2) key参数
key也是接受一个函数,不同的是,这个函数只接受一个元素,形式如下
def f(a):
return len(a)
key接受的函数返回值,表示此元素的权值,sort将按照权值大小进行排序
(3) reverse参数
接受False 或者True 表示是否逆序
>>> list = [2,8,4,1,5,7,3]
>>> other = sorted(list)
>>> other
[1, 2, 3, 4, 5, 7, 8]
>>> b=sorted(list,reverse=True)
>>> b
[8, 7, 5, 4, 3, 2, 1]
>>> L = [{1:5,3:4},{1:3,6:3},{1:1,2:4,5:6},{1:9}]
... def f(x):
... return len(x)
... L.sort(key=f)
... print (L)
[{1: 9}, {1: 5, 3: 4}, {1: 3, 6: 3}, {1: 1, 2: 4, 5: 6}]28 choice() 方法
choice() 方法返回一个列表,元组或字符串的随机项。
28.1 语法
以下是 choice() 方法的语法:
import random
random.choice( seq )注意:choice()是不能直接访问的,需要导入 random 模块,然后通过 random 静态对象调用该方法。返回随机项。
- seq -- 可以是一个列表,元组或字符串。
#!/usr/bin/python
import random
print "choice([1, 2, 3, 5, 9]) : ", random.choice([1, 2, 3, 5, 9])
print "choice('A String') : ", random.choice('A String')29 Python input()和raw_input()的区别
raw_input()随便输都是字符串,而input()必须按照Python的规则来~
(1)python3里面已经把raw_input()给去掉了
事实上是这样的:在 Python 3 内,将 raw_input() 重命名为 input(),这样一来,无须导入也能从标准输入获得数据了。如果您需要保留版本 2.x 的 input() 功能,可以使用 eval(input()),效果基本相同。
(2)Python 版本 2.x 中,raw_input() 会从标准输入(sys.stdin)读取一个输入并返回一个字符串,且尾部的换行符从末尾移除
29.1 raw_input()
raw_input()
name=raw_input('输入姓名:')
age=raw_input('输入年龄')
我们输入汉字的姓名和数字的年龄
输入姓名:许嵩
输入年龄:31
许嵩 31
年龄的格式是string。
29.2 input()
input()
name=input('输入姓名:')
age=input('输入年龄:')
我们还是输入汉字的姓名和数字的年龄
输入姓名:'许嵩'
输入年龄:31
许嵩 31input()输入严格按照Python的语法,是字符就自觉的加 ' ' ,数字就是数字。
30 python定义类()中写object和不写的区别
- python3中,类定义默认继承object,所以写不写没有区别
- 但在python2中,并不是这样
测试代码如下:
# -.- coding:utf-8 -.-
class Person:
"""
不带object
"""
name = "zhengtong"
class Animal(object):
"""
带有object
"""
name = "chonghong"
if __name__ == "__main__":
x = Person()
print "Person", dir(x)
y = Animal()
print "Animal", dir(y)输出如下:
Person ['__doc__', '__module__', 'name']
Animal ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__',
'__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name']Person类很明显能够看出区别,不继承object对象,只拥有了__doc__ , module 和 自己定义的name变量, 也就是说这个类的命名空间只有三个对象可以操作。
Animal类继承了object对象,拥有了好多可操作对象,这些都是类中的高级特性。
对于不太了解python类的同学来说,这些高级特性基本上没用处,但是对于那些要着手写框架或者写大型项目的高手来说,这些特性就比较有用了,比如说tornado里面的异常捕获时就有用到__class__来定位类的名称,还有高度灵活传参数的时候用到__dict__来完成等。
- python2中不继承object的类叫经典类,继承object的类叫做新式类。
- 我们平时写程序时,不妨养成良好的习惯,将object类继承上。
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
dir 语法:
- dir([object])
参数说明:
- object -- 对象、变量、类型。
31 Python中单引号,双引号,3个单引号及3个双引号的区别
31.1 单引号和双引号
在Python中单引号和双引号都可以用来表示一个字符串,比如
str1 = 'python'
str2 = "python"
str1和str2是没有任何区别的。
但是如果想输出:I'm a big fans of Python
可以注意到,原来的字符串中有一个',而Python又允许使用单引号' '来表示字符串,所以字符串中间的'必须用转义字符 \ 才可以:str3 = 'I\'m a big fan of Python.'
如果想输出:We all know that 'A' and 'B' are two capital letters.
使用单引号的话,也需要转义字符 \ :str4 = 'We all know that \'A\' and \'B\' are two capital letters.'
这么写比较麻烦,因此可以用双引号:str4_ = "We all know that 'A' and 'B' are two capital letters."
这就是Python支持双引号和单引号都能用来定义字符串的原因。
反之,如果字符串中有双引号,为了避免使用转义符,你可以使用单引号来定义这个字符串。比如:
str5 = 'The teacher said: "Practice makes perfect" is a very famous proverb.'
这就是Python易用性和人性化的一个极致体现,当你用单引号' '定义字符串的时候,它就会认为你字符串里面的双引号" "是普通字符,从而不需要转义。反之当你用双引号定义字符串的时候,就会认为你字符串里面的单引号是普通字符无需转义。
31.2 3个单引号及3个双引号
实际上3个单引号和3个双引号不经常用,但是在某些特殊格式的字符串下却有大用处。通常情况下我们用单引号或者双引号定义一个字符串的时候只能把字符串连在一起写成一行,如果非要写成多行,就得在每一行后面加一个 \ 表示连字符,比如:
str1 = "List of name:\
Hua Li\
Chao Deng"
而且即使你这样写也不能得到期望的输出:
List of name:
Hua Li
Chao Deng
实际上输出是下面这样的:
>>> str1 = "List of name:\
... Hua Li\
... Chao Deng"
>>> print(str1)
List of name: Hua Li Chao Deng
那么该如何得到我们期望的一行一个名字的输出格式呢?这就是3个引号的作用了:
>>> str1 = """List of name:
... Hua Li
... Chao Deng
... """
>>> print(str1)
List of name:
Hua Li
Chao Deng
我们也可以通过给字符串加上 \n 实现:
>>> str1 = "List of name:\nHua Li\nChao Deng"
>>> print(str1)
List of name:
Hua Li
Chao Deng
但是这样在输入的时候看起来就乱了很多,所以这种情况下尽量使用3个引号,至于3个单引号还是双引号都是一样的,只需要注意如果字符串中包含有单引号就要使用双引号来定义就好了。
而且使用3个引号还有一个作用:加注释!
>>> str1 = """
... List of name:
... Hua Li # LiHua
... Chao Deng # DengChao
... """
>>> print(str1)
List of name:
Hua Li # LiHua
Chao Deng # DengChao
32 Python txt文件读取写入字典的方法(json、eval)
https://blog.csdn.net/li532331251/article/details/78203438
32.1 使用json转换方法
1、字典写入txt
import json
dic = {
'andy':{
'age': 23,
'city': 'beijing',
'skill': 'python'
},
'william': {
'age': 25,
'city': 'shanghai',
'skill': 'js'
}
}
js = json.dumps(dic)
file = open('test.txt', 'w')
file.write(js)
file.close() 2、读取txt中的字典
import json
file = open('test.txt', 'r')
js = file.read()
dic = json.loads(js)
print(dic)
file.close() 32.2 使用str转换方法
1、字典写入txt
dic = {
'andy':{
'age': 23,
'city': 'beijing',
'skill': 'python'
},
'william': {
'age': 25,
'city': 'shanghai',
'skill': 'js'
}
}
fw = open("test.txt",'w+')
fw.write(str(dic)) #把字典转化为str
fw.close()
2、读取txt中字典
fr = open("test.txt",'r+')
dic = eval(fr.read()) #读取的str转换为字典
print(dic)
fr.close()
33 format 格式化函数
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
33.1 实例
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'"hello", "world") # 设置指定位置 'hello world' >>> "{1} {0} {1}".format("hello", "world") # 设置指定位置 'world hello world'
也可以设置参数:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
my_list = ['菜鸟教程', 'www.runoob.com']
my_list2 = ['da','dasd']
print("网站名:{1[0]}, 地址 {1[1]}".format(my_list,my_list2)) # "0"或"1"是必须的,代表format后面小括号中的第几个值。
输出结果为:
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:da, 地址 dasd也可以向 str.format() 传入对象:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) 33.2 数字格式化
下表展示了 str.format() 格式化数字的多种方法:
>>> print("{:.2f}".format(3.1415926));
3.14| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | |
|
进制 |
- ^, <, > 分别是居中、左对齐、右对齐,后面带宽度,
- : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
- + 表示在正数前显示 +,负数前显示 -;
- (空格)表示在正数前加空格
- b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,如下实例:
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
print ("{} 对应的位置是 {{0}}".format("runoob"))输出结果为:
runoob 对应的位置是 {0}34 Python 中如何获取当前位置所在的文件名,函数名,以及行号
34.1 模块sys(不推荐)
import sys
def function():
print(sys._getframe().f_code.co_filename) #当前位置所在的文件名
print(sys._getframe().f_code.co_name) #当前位置所在的函数名
print(sys._getframe().f_lineno) #当前位置所在的行号
if __name__ == '__main__':
function()
获取类里面方法名称,跟获取函数名称一样 sys._getframe().f_code.co_name
import sys
class pra():
def function_name(self):
print("获取当前类名称:%s" % self.__class__.__name__)
print("获取类中函数名:%s" % sys._getframe().f_code.co_name)
if __name__ == "__main__":
pra().function_name()34.2 在函数外部获取函数名称(.__name__)
def practice():
print("hello")
n = practice.__name__
print(n)34.3 获取类名称
获取类名称 self.__class__.__name__
class pra():
def function_name(self):
print("获取当前类名称:%s" % self.__class__.__name__)
if __name__ == "__main__":
pra().function_name()34.4 inspect模块
(1)
import inspect
def debug():
callnamer = inspect.stack()
print('[debug] enter: {}'.format(callnamer))
debug()
结果(一个列表):
[debug] enter: [FrameInfo(frame=', line 4, code debug>, filename='', lineno=3, function='debug', code_context=[' callnamer = inspect.stack()\n'], index=0), FrameInfo(frame=', line 6, code >, filename='', lineno=6, function='', code_context=['debug()\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\interactiveshell.py', lineno=3325, function='run_code', code_context=[' exec(code_obj, self.user_global_ns, self.user_ns)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\interactiveshell.py', lineno=3248, function='run_ast_nodes', code_context=[' if (await self.run_code(code, result, async_=asy)):\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\interactiveshell.py', lineno=3057, function='run_cell_async', code_context=[' interactivity=interactivity, compiler=compiler, result=result)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\async_helpers.py', lineno=68, function='_pseudo_sync_runner', code_context=[' coro.send(None)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\interactiveshell.py', lineno=2880, function='_run_cell', code_context=[' return runner(coro)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\Anaconda\\Anaconda\\lib\\site-packages\\IPython\\core\\interactiveshell.py', lineno=2854, function='run_cell', code_context=[' raw_cell, store_history, silent, shell_futures)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\_pydev_bundle\\pydev_ipython_console_011.py', lineno=441, function='add_exec', code_context=[' self.ipython.run_cell(line, store_history=True)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\_pydev_bundle\\pydev_ipython_console.py', lineno=39, function='do_add_exec', code_context=[' res = bool(self.interpreter.add_exec(code_fragment.text))\n'], index=0), FrameInfo(frame=, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\_pydev_bundle\\pydev_code_executor.py', lineno=106, function='add_exec', code_context=[' more = self.do_add_exec(code_fragment)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\pydevconsole.py', lineno=174, function='process_exec_queue', code_context=[' more = interpreter.add_exec(code_fragment)\n'], index=0), FrameInfo(frame=, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\pydevconsole.py', lineno=327, function='start_client', code_context=[' process_exec_queue(interpreter)\n'], index=0), FrameInfo(frame=>, filename='D:\\software\\pycharm\\pycharm\\PyCharm 2018.3.5\\helpers\\pydev\\pydevconsole.py', lineno=386, function='', code_context=[' pydevconsole.start_client(host, port)\n'], index=0)]
(2)
import inspect
def debug():
callnamer = inspect.stack()[1]
print('[debug] enter: {}'.format(callnamer))
debug()结果:
[debug] enter: FrameInfo(frame=', line 6, code >, filename='', lineno=6, function='', code_context=['debug()\n'], index=0)
(3)
import inspect
def debug():
callnamer = inspect.stack()[1][4]
print('[debug] enter: {}'.format(callnamer))
debug()结果:
[debug] enter: ['debug()\n'](4)
使用inspect模块动态获取当前运行的函数名(或方法名称)
# coding:utf-8
import inspect
def get__function_name():
'''获取正在运行函数(或方法)名称'''
return inspect.stack()[1][3]
def yoyo():
print("函数名称:%s"%get__function_name())
class Yoyo():
def yoyoketang(self):
'''# 上海-悠悠 QQ群:588402570'''
print("获取当前类名称.方法名:%s.%s" % (self.__class__.__name__, get__function_name()))
if __name__ == "__main__":
yoyo()
Yoyo().yoyoketang()
运行结果:
函数名称:yoyo
获取当前类名称.方法名:Yoyo.yoyoketang(5)
import sys
import inspect
def my_name():
print '1' ,sys._getframe().f_code.co_name
print '2' ,inspect.stack()[0][3]
def get_current_function_name():
print '5', sys._getframe().f_code.co_name
return inspect.stack()[1][3]
class MyClass:
def function_one(self):
print '3',inspect.stack()[0][3]
print '4', sys._getframe().f_code.co_name
print "6 %s.%s invoked"%(self.__class__.__name__, get_current_function_name())
if __name__ == '__main__':
my_name()
myclass = MyClass()
myclass.function_one()
35 List index()方法
35.1 描述
index() 函数用于从列表中找出某个值第一个匹配项的索引位置。
35.2 语法
index()方法语法:
list.index(x[, start[, end]])35.3 参数
- x-- 查找的对象。
- start-- 可选,查找的起始位置。
- end-- 可选,查找的结束位置。
35.4 返回值
该方法返回查找对象的索引位置,如果没有找到对象则抛出异常。
35.5 实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
aList = [123, 'xyz', 'runoob', 'abc']
print "xyz 索引位置: ", aList.index( 'xyz' )
print "runoob 索引位置 : ", aList.index( 'runoob', 1, 3 )以上实例输出结果如下:
xyz 索引位置: 1
runoob 索引位置 : 236 collections.defaultdict()
https://blog.csdn.net/yangsong95/article/details/82319675
https://www.jianshu.com/p/26df28b3bfc8
Python中通过Key访问字典,当Key不存在时,会引发‘KeyError’异常。为了避免这种情况的发生,可以使用collections类中的defaultdict()方法来为字典提供默认值。
语法格式:
collections.defaultdict([default_factory[, …]])
该函数返回一个类似字典的对象。defaultdict是Python内建字典类(dict)的一个子类,它重写了方法_missing_(key),增加了一个可写的实例变量default_factory,实例变量default_factory被missing()方法使用,如果该变量存在,则用以初始化构造器,如果没有,则为None。其它的功能和dict一样。
第一个参数为default_factory属性提供初始值,默认为None;其余参数包括关键字参数(keyword arguments)的用法,和dict构造器用法一样。
36.1 default_factory为list
36.1.1 collections.defaultdict
使用list作第一个参数,可以很容易将键-值对序列转换为列表字典。
代码如下:
from collections import defaultdict
s=[('yellow',1),('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d=defaultdict(list)
for k, v in s:
d[k].append(v)
a=sorted(d.items())
print(a)结果:
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]当字典中没有的键第一次出现时,default_factory自动为其返回一个空列表,list.append()会将值添加进新列表;再次遇到相同的键时,list.append()将其它值再添加进该列表。
36.1.2 dict.setdefault()
这种方法比使用dict.setdefault()更为便捷,dict.setdefault()也可以实现相同的功能。
代码如下:
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d={}
for k, v in s:
d.setdefault(k,[]).append(v)
print('\n',d)
a=sorted(d.items())
print('\n',a)结果:
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]36.2 default_factory为int
from collections import defaultdict
s = 'mississippi'
d = defaultdict(int)
for k in s:
d[k] += 1
print('\n',d)
a=sorted(d.items())
print('\n',a)
结果:
defaultdict(, {'m': 1, 'i': 4, 's': 4, 'p': 2})
[('i', 4), ('m', 1), ('p', 2), ('s', 4)] 字符串中的字母第一次出现时,字典中没有该字母,default_factory函数调用int()为其提供一个默认值0,加法操作将计算出每个字母出现的次数。
函数int()是常值函数的一种特例,总是返回0。使用匿名函数(lambda function)可以更快、更灵活的创建常值函数,返回包括0在内的任意常数值。
from collections import defaultdict
def constant_factory(value):
return lambda: value
d = defaultdict(constant_factory(''))
print('\n',d)
d.update(name='John', action='ran')
print('\n',d)
print('\n','%(name)s %(action)s to %(object)s' % d)
结果:
defaultdict(. at 0x00000200CB0C2E18>, {})
defaultdict(. at 0x00000200CB0C2E18>, {'name': 'John', 'action': 'ran'})
John ran to 36.3 default_factory为set
from collections import defaultdict
s = [('red', 1), ('blue', 2), ('red', 3), ('blue', 4), ('red', 1), ('blue', 4)]
d = defaultdict(set)
for k, v in s:
d[k].add(v)
print('\n',d)
a=sorted(d.items())
print('\n',a)
结果:
defaultdict(, {'red': {1, 3}, 'blue': {2, 4}})
[('blue', {2, 4}), ('red', {1, 3})] 37 items() 方法
37.1 描述
Python 字典 items() 方法以列表返回可遍历的(键, 值) 元组数组。
37.2 语法
items()方法语法:
dict.items()37.3 参数
- NA。
37.4 返回值
返回可遍历的(键, 值) 元组数组。
37.5 实例
(1)
#!/usr/bin/python3
dict = {'Name': 'Runoob', 'Age': 7}
print ("Value : %s" % dict.items())
print (dict.items())
a=dict.items()
print(type(a))以上实例输出结果为:
Value : dict_items([('Age', 7), ('Name', 'Runoob')])
dict_items([('Name', 'Runoob'), ('Age', 7)])
dict_items(2)
dict = {'Name': 'Runoob', 'Age': 7}
for i,j in dict.items():
print(i, ":\t", j)输出:
Name : Runoob
Age : 7(3)
将字典的 key 和 value 组成一个新的列表:
d={1:"a",2:"b",3:"c"}
result=[]
for k,v in d.items():
result.append(k)
result.append(v)
print(result)输出:
[1, 'a', 2, 'b', 3, 'c']38 Python格式化字符串(格式化输出)
Python 提供了“%”对各种类型的数据进行格式化输出,例如如下代码:
price = 108
print ("the book's price is %s" % price)上面程序中的 print 函数包含以下三个部分,第一部分是格式化字符串(相当于字符串模板),该格式化字符串中包含一个“%s”占位符,它会被第三部分的变量或表达式的值代替;第二部分固定使用“%”作为分隔符。
格式化字符串中的“%s”被称为转换说明符(Conversion Specifier),其作用相当于一个占位符,它会被后面的变量或表达式的值代替。“%s”指定将变量或值使用 str() 函数转换为字符串。
如果格式化字符串中包含多个“%s”占位符,第三部分也应该对应地提供多个变量,并且使用圆括号将这些变量括起来。例如如下代码:
user = "Charli"
age = 8
# 格式化字符串有两个占位符,第三部分提供2个变量
print("%s is a %s years old boy" % (user , age))
Python 提供了如下表所示的转换说明符:
| 转换说明符 | 说明 |
|---|---|
| %d,%i | 转换为带符号的十进制形式的整数 |
| %o | 转换为带符号的八进制形式的整数 |
| %x,%X | 转换为带符号的十六进制形式的整数 |
| %e | 转化为科学计数法表示的浮点数(e 小写) |
| %E | 转化为科学计数法表示的浮点数(E 大写) |
| %f,%F | 转化为十进制形式的浮点数 |
| %g | 智能选择使用 %f 或 %e 格式 |
| %G | 智能选择使用 %F 或 %E 格式 |
| %c | 格式化字符及其 ASCII 码 |
| %r | 使用 repr() 将变量或表达式转换为字符串 |
| %s | 使用 str() 将变量或表达式转换为字符串 |
在默认情况下,转换出来的字符串总是右对齐的,不够宽度时左边补充空格。Python 也允许在最小宽度之前添加一个标志来改变这种行为,Python 支持如下标志:
- -:指定左对齐。
- +:表示数值总要带着符号(正数带“+”,负数带“-”)。
- 0:表示不补充空格,而是补充 0。
提示:这三个标志可以同时存在。
对于转换浮点数,Python 还允许指定小数点后的数字位数:如果转换的是字符串,Python 允许指定转换后的字符串的最大字符数。这个标志被称为精度值,该精度值被放在最小宽度之后,中间用点 () 隔开。例如如下代码:
my_value = 3.001415926535
# 最小宽度为8,小数点后保留3位
print("my_value is: %8.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0
print("my_value is: %08.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0,始终带符号
print("my_value is: %+08.3f" % my_value)
the_name = "Charlie"
# 只保留3个字符
print("the name is: %.3s" % the_name) # 输出Cha
# 只保留2个字符,最小宽度10
print("the name is: %10.2s" % the_name)运行上面代码,可以看到如下输出结果:
my_value is: 3.001
my_value is: 0003.001
my_value is: +003.001
the name is: Cha
the name is: Ch39 zip
描述:
zip() 函数用于将可迭代对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象。
如果各个可迭代对象的元素个数不一致,则返回的对象长度与最短的可迭代对象相同。
利用 * 号操作符,与zip相反,进行解压。
zip() 函数语法:
zip(iterable1,iterable2, ...)
参数说明:
- iterable -- 一个或多个可迭代对象(字符串、列表、元祖、字典)
返回值:
Python2中直接返回一个由元组组成的列表,Python3中返回的是一个对象,如果想要得到列表,可以用 list() 函数进行转换。
实例:
以下实例展示了 zip() 函数的使用方法:
python2:
>>> a = [1,2,3] #此处可迭代对象为列表
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
>>> zipped
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,可理解为解压
[(1, 2, 3), (4, 5, 6)]python3:
例(1):
>>> a = [1,2,3] #此处可迭代对象为列表
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b)
>>> zipped
#返回的是一个对象
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)] #使用list()函数转换为列表
>>> list(zip(a,c))
[(1, 4), (2, 5), (3, 6)]
>>> zipped = zip(a,b)
>>> list(zip(*zipped)) #解压也使用list进行转换
[(1, 2, 3), (4, 5, 6)] 例(2):
#!/usr/bin/python3
#v1,v2,v3可是是任何可迭代对象,如:字符串、列表、元祖、字典
v1 = {1:11,2:22} #此处可迭代对象为字典
v2 = {3:33,4:44}
v3 = {5:55,6:66}
v = zip(v1,v2,v3) #压缩
print(list(v))
w = zip(*zip(v1,v2,v3)) #解压
print(list(w))结果:
[(1, 3, 5), (2, 4, 6)]
[(1, 2), (3, 4), (5, 6)]例(3),搭配for循环支持并行迭代:
#!/usr/bin/python3
list1 = [2,3,4]
list2 = [4,5,6]
for x,y in zip(list1,list2):
print(x,y,'--',x*y)结果:
2 4 -- 8
3 5 -- 15
4 6 -- 24例(4),二维矩阵变换(矩阵的行列互换):
>>> l1=[[1,2,3],[4,5,6],[7,8,9]]
>>> print ([(j[i] for j in l1) for i in range(len(l1[0]))])
[. at 0x00000200CB119D68>, . at 0x00000200CB119DE0>, . at 0x00000200CB119C78>]
>>> print([[j[i] for j in l1] for i in range(len(l1[0])) ])
[[1, 4, 7], [2, 5, 8], [3, 6, 9]] >>> l1=[[1,2,3],[4,5,6],[7,8,9]]
>>> zip(*l1)
Out[87]:
>>> for i in zip(*l1):
>>> print(i)
(1, 4, 7)
(2, 5, 8)
(3, 6, 9) 40 pickle
官方文档:https://docs.python.org/3/library/pickle.html
在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间。Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。
pickle模块实现了用于序列化和反序列化python对象结构的二进制协议。 序列化操作"pickling"是将python对象层次结构转换为字节流的过程,反序列化操作 "unpickling"则是将字节流转换回对象层次结构。
不得不提到的是,pickle是python所独有的,因此非python程序可能无法重构pickle对象。即用sklearn训练得到的机器学习模型,用pickle保存下来后,工程方面的同事是没法用java调用这个模型的。
pickle是python语言的一个标准模块,安装python后已包含pickle库,不需要单独再安装。
pickle模块实现了基本的数据序列化和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
40.1 序列化和反序列化
为什么需要序列化和反序列化这一操作呢?
1. 便于存储。序列化过程将文本信息转变为二进制数据流。这样就信息就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据。在Python程序运行中得到了一些字符串、列表、字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据。python模块中的 pickle模块 就派上用场了,它可以将对象转换为一种可以传输或存储的格式。
2. 便于传输。当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把這个对象转换为字节序列,在能在网络上传输;接收方则需要把字节序列在恢复为对象。
在官方的介绍中,序列化操作的英文描述有好几个单词,如”serializing”, “pickling”, “serialization”, “marshalling” 或者”flattening”等,它们都代表的是序列化的意思。相应的,反序列化操作的英文单词也有好多个,如”de-serializing”, “unpickling”, “deserailization”等。为了避免混淆,一般用”pickling”/“unpickling”, 或者”serialization”/“deserailization”。
pickle模块是以二进制的形式序列化后保存到文件中(保存文件的后缀为”.pkl”),不能直接打开进行预览。而python的另一个序列化标准模块json,则是human-readable的,可以直接打开查看(例如在notepad++中查看)。
pickle模块有两类主要的接口,即序列化和反序列化。
序列化操作包括:
pickle.dump()
Pickler(file, protocol).dump(obj)
反序列化操作包括:
pickle.load()
Unpickler(file).load()
40.2 序列化操作
40.2.1 pickle.dump()
序列化的方法为 pickle.dump(),该方法的相关参数如下:
|
|
关于参数file,有一点需要注意,必须是以二进制的形式进行操作(写入)。该方法实现的是将序列化后的对象obj以二进制形式写入文件file中,进行保存。它的功能等同于 Pickler(file, protocol).dump(obj)。
参考前文的案例如下:
|
|
file为'svm_model_iris.pkl',并且以二进制的形式('wb')写入。
关于参数protocol,参数protocol代表了序列化模式(pickle协议),在python2.X版本默认值为0,在python3.X本默认值为3。一共有5中不同的类型,即(0,1,2,3,4)。(0,1,2)对应的是python早期的版本,(3,4)则是在python3之后的版本。
此外,参数可选 pickle.HIGHEST_PROTOCOL和pickle.DEFAULT_PROTOCOL。当前,python3.5版本中,pickle.HIGHEST_PROTOCOL的值为4,pickle.DEFAULT_PROTOCOL的值为3。当protocol参数为负数时,表示选择的参数是pickle.HIGHEST_PROTOCOL。
protocol值越大,dump的速度越快,并且支持的数据类型更多,保存下来的文件占用空间更小,同时也带来一些其他优化,例如在python3.4中,协议版本4新支持对非常大的数据进行序列化。因此可以的话,请选择最高协议版本作为protocol参数的值,即设protocol=pickle.HIGHEST_PROTOCOL即可。
40.2.2 pickle.dumps()
pickle.dumps()方法的参数如下:
|
|
pickle.dumps()方法跟 pickle.dump() 方法的区别在于,pickle.dumps()方法不需要写入文件中,它是直接返回一个序列化的bytes对象。
40.2.3 Pickler(file, protocol).dump(obj)
pickle模块提供了序列化的面向对象的类方法,即 class pickle.Pickler(file, protocol=None,*,fix_imports=True),Pickler类有dump()方法。
Pickler(file, protocol).dump(obj) 实现的功能跟 pickle.dump() 是一样的。
40.3 反序列化操作
40.3.1 pickle.load()
序列化的方法为 pickle.load(),该方法的相关参数如下:
|
|
该方法实现的是将序列化的对象从文件file中读取出来。它的功能等同于 Unpickler(file).load()。
关于参数file,有一点需要注意,必须是以二进制的形式进行操作(读取)。
import picklewith
open('svm_model_iris.pkl', 'rb') as f:
model = pickle.load(f)
file为'svm_model_iris.pkl',并且以二进制的形式('rb')读取。
读取的时候,参数protocol是自动选择的,load()方法中没有这个参数。
40.3.2 pickle.loads()
pickle.loads() 方法的参数如下:
|
|
pickle.loads()方法跟 pickle.load() 方法的区别在于,pickle.loads()方法是直接从bytes对象中读取序列化的信息,而非从文件中读取。
40.3.3 Unpickler(file).load()
pickle模块提供了反序列化的面向对象的类方法,即
class pickle.Unpickler(file, *,fix_imports=True, encoding="ASCII". errors="strict")
Pickler类有load()方法。
pickle.Unpickler(file).load() 实现的功能跟 pickle.load() 是一样的。
41 变量赋值
41.1 赋值
https://www.cnblogs.com/jiangzhaowei/p/5740913.html
在 python 中赋值语句总是建立对象的引用值,而不是复制对象。因此,python 变量更像是指针,而不是数据存储区域,
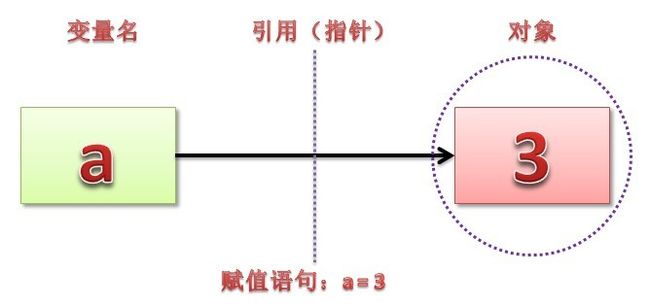
例一:
values = [0, 1, 2]
values = [3, 4, 5] 执行 values = [0, 1, 2] 的时候,Python 做的事情是首先创建一个列表对象 [0, 1, 2],然后给它贴上名为 values 的标签。如果随后又执行 values = [3, 4, 5] 的话,Python 做的事情是创建另一个列表对象 [3, 4, 5],然后把刚才那张名为 values 的标签从前面的 [0, 1, 2] 对象上撕下来,重新贴到 [3, 4, 5] 这个对象上。
至始至终,并没有一个叫做 values 的列表对象容器存在,Python 也没有把任何对象的值复制进 values 去。过程如图所示: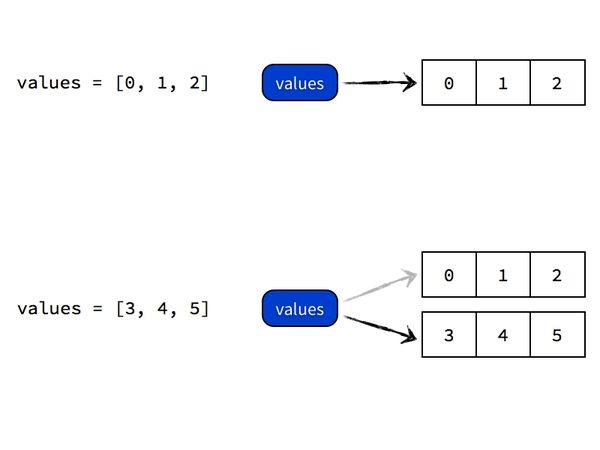
例二:
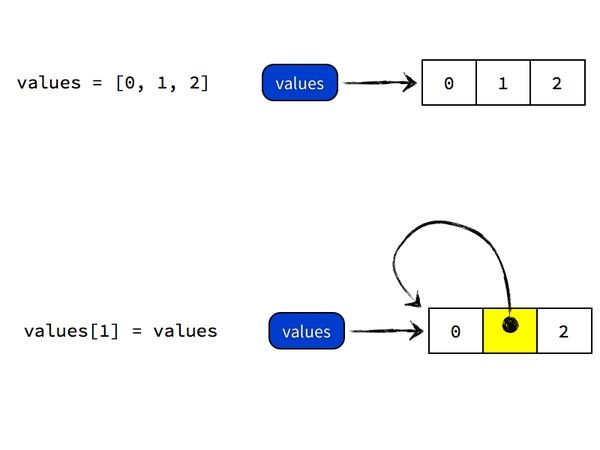
values = [0, 1, 2]
values[1] = values
print(values)结果:
[0, [...], 2]并没有像预想的一样得到 [0, [0, 1, 2], 2],可以说 Python 没有赋值,只有引用。你这样相当于创建了一个引用自身的结构,所以导致了无限循环。执行 values[1] = values的时候,Python 做的事情则是把 values 这个标签所引用的列表对象的第二个元素指向 values 所引用的列表对象本身。执行完毕后,values 标签还是指向原来那个对象,只不过那个对象的结构发生了变化,从之前的列表 [0, 1, 2] 变成了 [0, ?, 2],而这个 ? 则是指向那个对象本身的一个引用。如图所示:
要达到你所需要的效果,即得到 [0, [0, 1, 2], 2] 这个对象,你不能直接将 values[1] 指向 values 引用的对象本身,而是需要把 [0, 1, 2] 这个对象「复制」一遍,得到一个新对象,再将 values[1] 指向这个复制后的对象。Python 里面复制对象的操作因对象类型而异,复制列表 values 的操作是
values[:] #生成对象的拷贝或者是复制序列,不再是引用和共享变量,但此法只能顶层复制所以你需要执行
values[1] = values[:]Python 做的事情是,先 dereference 得到 values 所指向的对象 [0, 1, 2],然后执行 [0, 1, 2][:] 复制操作得到一个新的对象,内容也是 [0, 1, 2],然后将 values 所指向的列表对象的第二个元素指向这个复制而来的列表对象,最终 values 指向的对象是 [0, [0, 1, 2], 2]。过程如图所示:
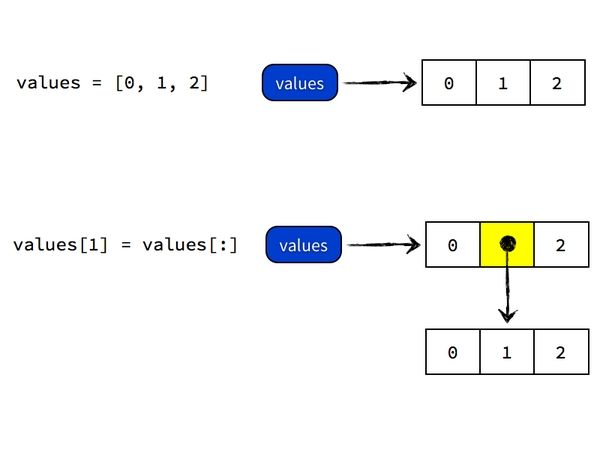
注:values[:] 复制操作是所谓的「浅复制」(shallow copy),当列表对象有嵌套的时候也会产生出乎意料的错误。如下:
例三:
a = [0, [1, 2], 3]
b = a[:]
a[0] = 8
a[1][1] = 9
print(a)
print(b)结果:
[8, [1, 9], 3]
[0, [1, 9], 3]b 的第二个元素也被改变了。原因如下:
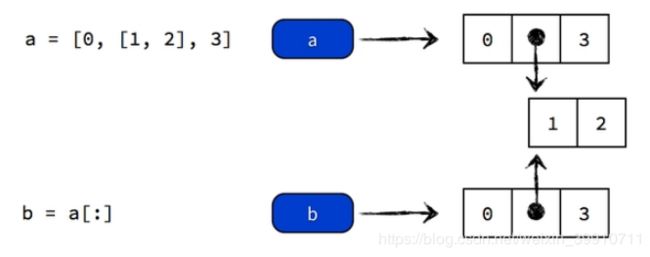
正确的复制嵌套元素的方法是进行「深复制」(deep copy),方法如下:
import copy
a = [0, [1, 2], 3]
b = copy.deepcopy(a)
a[0] = 8
a[1][1] = 9
print(a)
print(b)结果:
[8, [1, 9], 3]
[0, [1, 2], 3]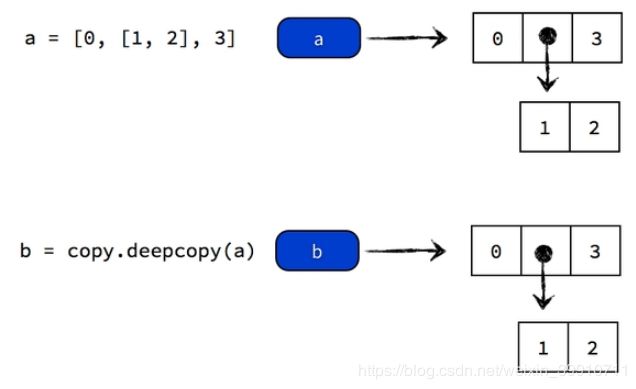
41.1 共享引用
>>> a=3
>>> b=ab=a 会使 python 创建变量b。变量 a 正在使用,并且 a 这里没有被赋值,所以 a 被替换成其引用的对象 3,从而 b 也成为这一对象的引用。 a 和 b 指向了相同的内存空间。这在 Python 中叫做共享引用——多个变量名引用了同一个对象。
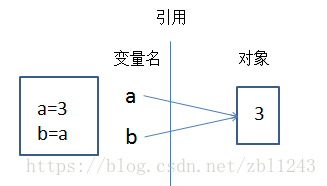
41.2 多目标赋值(多重赋值)及共享引用
Python中多目标赋值即将等号左边所有的变量名都赋值给右边的对象,完成赋值操作,比如将三个变量同时赋值给一个字符串。
a = b = c = 'Python'
print(a,b,c)
结果:
Python Python Python
在多目标赋值中,其本质即类似三个变量的指针指向了同一个内存空间,即三个变量共享了内存内同一对象。
41.2.1 不可变对象
对于不可变对象来说,我们在使用这些变量是不存在问题的。
a = b = c = 'Python'
a = 'i like Python'
b = 'Python make me happy'
print(a)
print(b)
print(c)示例结果:
i like Python
Python make me happy
Python可以看到这些变量并不会互相影响。
41.2.2 可变对象
而对可变对象来说,比如列表,字典等,多目标赋值变量的使用便会变得棘手些。
L1 = L2 = [1, 2, 3, 4, 5]
print(L1)
print(L2)
# 更改列表L2,从列表尾部删除一个元素
L2.pop()
print(L1)
print(L2)结果:
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
[1, 2, 3, 4]
[1, 2, 3, 4]即当我们在使用多目标赋值时,需要考虑对象本身属性是否为可变对象,否则我们应该考虑对每个变量名进行单独赋值或者利用浅拷贝、深拷贝等方式完成多变量的可变对象的赋值。
41.3 增强赋值及共享引用
41.3.1 概述
Python中的增强赋值是从C语言中借鉴出来的,所以这些格式的用法大多和C一致,本身就是对表达式的简写,即二元表达式和赋值语句的结合,比如a += b 和a = a + b 就是一致的,比如还有以下的增强赋值语句。
| - | - | - | - |
|---|---|---|---|
| a += b | a &= b | a -= b | a |= b |
| a *= b | a ^= b | a /= b | a >>=b |
| a %= b | a <<= b | a **= b | a //=b |
即增强赋值语句适用于任何支持隐式二元表达式的类型,比如“+”的多态:数字的相加和字符串的合并。
(1)数字加减
a = 1
a = a + 1
print(str(a))
a += 1
print(str(a))结果:
2
3(2)字符串合并
S = 'I'
S = S + ' like '
print(S)
S += 'Python.'
print(S)结果:
I like
I like Python.41.3.2 优点
- 简洁
- 减少一次
a的执行,执行速度更快 - 针对可变对象,增强赋值会自动选择执行原处的修改运算,而不是速度更慢的复制。这就引申出我们在可变对象中可能涉及的共享引用问题。
41.3.3 共享引用
当我们想要扩展列表时,比如将一组元素添加到末尾:
L = [1, 2, 3]
# 传统“+”法
L = L + [4, 5]
print(L)
# 利用列表方法extend
L.extend([6, 7])
print(L)结果:
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5, 6, 7] 示例中第一种“+”法,即采用合并的方法,需要新创建一个对象把左侧的 L 复制到新列表中,然后再[4, 5]复制到新列表中。而第二种extend则是直接在内存空间列表L末尾L加上[4, 5],即速度会更快,增强赋值则是自动采用的第二种,属于共享引用,即L.extend([6, 7])和L += [6, 7]是等价的,也是最优的选择。这种合并方式虽然快,但对于可变对象的共享引用则会变的棘手些。
例如:
L1 = [1, 2, 3]
L2 = L1
L2 = L2 + [4, 5]
print(L2)
print(L1)
print('-' * 21)
L1 = [1, 2, 3]
L2 = L1
L2 += [4, 5]
print(L2)
print(L1)示例结果:
[1, 2, 3, 4, 5]
[1, 2, 3]
---------------------
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
我们可以从示例中看到如果同一个可变对象赋值了多个变量,那么在破坏共享引用结构时,就应该对可变对象拷贝后在进行操作。
41.4 多元赋值
另一种将多个变量同时赋值的方法我们称为多元赋值(multuple)。将 "mul-tuple"连在一起自造的。因为采用这种方式赋值时, 等号两边的对象都是元组。
x, y, z = 1, 2, 'a string'
等同于 (x, y, z) = (1, 2, 'a string')
两个整数对象(值分别为 1 和 2)及一个字符串对象, 被分别赋值给x, y 和 z。通常元组需要用圆括号(小括号)括起来,尽管它们是可选的。但是加上圆括号以使得代码有更高的可读性,当然误解也就更少了。
在其他语言中(如C++),要交换两个值, 会想到使用一个临时变量比如 tmp 来临时保存其中一个值:
tmp = x;
x = y;
y = tmp;
在上面的 代码片段中,变量 x 和变量 y 的值被互相交换。临时变量 tmp 用于在将 y 赋值给 x 前先保存 x 的值。将 y 的值赋给 x 之后, 才可以将保存在 tmp 变量中的 x 的值赋给 y。
Python 的多元赋值方式可以实现无需中间变量交换两个变量的值。
x, y = 123, 'a string'
print(x,y)
x, y = y, x
print(x,y)
输出:
123 a string
a string 123Python 在赋值之前已经事先对 x 和 y 的新值做了计算。
关于交换值的例子,可以通过 https://docs.python.org/2/library/dis.html 查看原理。当交换两个值或三个值时,python自己进行了优化,没有新建元组,直接在栈上进行交换;但是当交换四个及以上个值时,python新建了元组。
例一(交换2个值):
def a():
x = 1
y=2
x, y = y, x
dis(a)结果:
2 0 LOAD_CONST 1 (3)
2 DUP_TOP
4 STORE_FAST 0 (x)
6 STORE_FAST 1 (y)
3 8 LOAD_FAST 1 (y)
10 LOAD_FAST 0 (x)
12 ROT_TWO
14 STORE_FAST 0 (x)
16 STORE_FAST 1 (y)
18 LOAD_CONST 0 (None)
20 RETURN_VALUE例二(交换4个值):
from dis import dis
def a():
x = y = z = p =3
x, y, z, q = p, z, y, x
dis(a)结果:
2 0 LOAD_CONST 1 (3)
2 DUP_TOP
4 STORE_FAST 0 (x)
6 DUP_TOP
8 STORE_FAST 1 (y)
10 DUP_TOP
12 STORE_FAST 2 (z)
14 STORE_FAST 3 (p)
3 16 LOAD_FAST 3 (p)
18 LOAD_FAST 2 (z)
20 LOAD_FAST 1 (y)
22 LOAD_FAST 0 (x)
24 BUILD_TUPLE 4
26 UNPACK_SEQUENCE 4
28 STORE_FAST 0 (x)
30 STORE_FAST 1 (y)
32 STORE_FAST 2 (z)
34 STORE_FAST 4 (q)
36 LOAD_CONST 0 (None)
38 RETURN_VALUE注:在结果中的空行之前,栈空。
42 Pythonzhi直接赋值、浅拷贝和深度拷贝解析
官方文档:https://docs.python.org/3/library/copy.html
- 直接赋值:其实就是对象的引用(别名)。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
字典浅拷贝实例:
>>>a = {1: [1,2,3]}
>>> b = a.copy()
>>> a, b
({1: [1, 2, 3]}, {1: [1, 2, 3]})
>>> a[1].append(4)
>>> a, b
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})深度拷贝需要引入 copy 模块:
>>>import copy
>>> c = copy.deepcopy(a)
>>> a, c
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
>>> a[1].append(5)
>>> a, c
({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})解析:
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
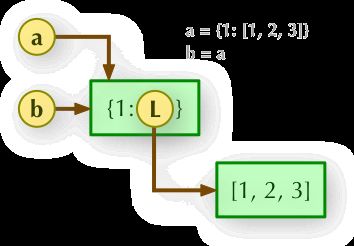
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
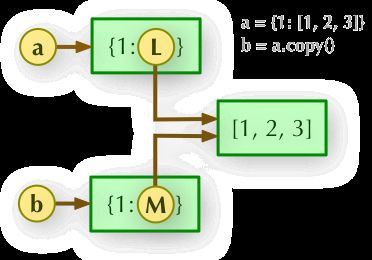
3、b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
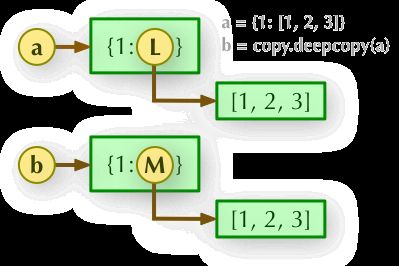
示例:
import copy
a={1:[1,2]}
b=a.copy()
c=a
d=copy.deepcopy(a)
print(a,b,c,d)
# {1: [1, 2]} {1: [1, 2]} {1: [1, 2]} {1: [1, 2]}
print(id(a),id(b),id(c),id(d))
# 185587176 185675496 185587176 185702152
print(id(a[1]),id(b[1]),id(c[1]),id(d[1]))
# 178923272 178923272 178923272 185329864
a[1].append(3)
print(a,b,c,d)
# {1: [1, 2, 3]} {1: [1, 2, 3]} {1: [1, 2, 3]} {1: [1, 2]}
print(id(a),id(b),id(c),id(d))
# 185587176 185675496 185587176 185702152
print(id(a[1]),id(b[1]),id(c[1]),id(d[1]))
# 178923272 178923272 178923272 185329864
a[1]=a[1]+[4]
print(a,b,c,d)
# {1: [1, 2, 3, 4]} {1: [1, 2, 3]} {1: [1, 2, 3, 4]} {1: [1, 2]}
print(id(a),id(b),id(c),id(d))
# 185587176 185675496 185587176 185702152
print(id(a[1]),id(b[1]),id(c[1]),id(d[1]))
# 178923592 178923272 178923592 185329864
注:copy模块中也有copy函数。id() 函数用于获取对象的内存地址。
import copy
a=["asd",28,[1,2]]
b=copy.deepcopy(a)
print(id(a[0]),id(a[1]),id(a[2]))
pritn(id(b[0]),id(b[1]),id(b[2]))
# (2579326064880, 140715273787040, 2579326453768)
# (2579326064880, 140715273787040, 2579326454216)
# 深拷贝时,列表中的字符串和数字的内存地址不变
a[0]=2
print(a,b)
print(id(a[0]),id(a[1]),id(a[2]))
pritn(id(b[0]),id(b[1]),id(b[2]))
# [2, 28, [1, 2]] ['asd', 28, [1, 2]]
# (140715273786208, 140715273787040, 2579326453768)
# (2579326064880, 140715273787040, 2579326454216)
# 深拷贝后,原列表中的某个字符串更改后,原列表的该位置引用的内存地址改变,指向新的内存空间深拷贝时,列表中的字符串和数字的内存地址不变;深拷贝后,原列表中的某个字符串更改后,原列表的该位置引用的内存地址改变,指向新的内存空间。
43 python 变量作用域及其陷阱
43.1 可变对象 & 不可变对象
在Python中,对象分为两种:可变对象和不可变对象,不可变对象包括int,float,long,str,tuple等,可变对象包括list,set,dict等。需要注意的是:这里说的不可变指的是值的不可变。
- 对于不可变类型的变量,如果要更改变量,则会创建一个新值,把变量绑定到新值上,而旧值如果没有被引用就等待垃圾回收。另外,不可变的类型可以计算hash值,作为字典的key。
- 可变类型数据对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的内存地址会保持不变,但区域会变长或者变短。
a_list = [1, 2, 3]
id(a_list) # 63085128
a_list=a_list+[4]
id(a_list) # 58711496
a_list.append(5)
id(a_list) # 58711496列表a_list重新赋值之后,变量 a_list 的内存地址并未改变,append 操作只是改变了其 value,变量 a_list 指向没有变。
43.2 函数值传递
def func_int(a):
a += 4
def func_list(a_list):
a_list[0] = 4
t = 0
func_int(t)
print t
# output: 0
t_list = [1, 2, 3]
func_list(t_list)
print t_list
# output: [4, 2, 3]主要是因为可变对象和不可变对象的原因:对于可变对象,对象的操作不会重建对象,而对于不可变对象,每一次操作就重建新的对象。
在函数参数传递的时候,Python其实就是把参数里传入的变量对应的对象的引用依次赋值给对应的函数内部变量。参照上面的例子来说明更容易理解,func_int 中的局部变量"a"其实是全部变量"t"所指向对象的另一个引用,由于整数对象是不可变的,所以当 func_int 对变量"a"进行修改的时候,实际上是将局部变量"a"指向到了整数对象"4"。所以很明显,func_list修改的是一个可变的对象,局部变量"a"和全局变量"t_list"指向的还是同一个对象。
43.3 为什么修改全局的dict变量不用global关键字
s = 'foo'
d = {'a':1}
def f():
s = 'bar'
d['b'] = 2
f()
print s # foo
print d # {'a': 1, 'b': 2}这是因为,在s = 'bar'这句中,它是“有歧义的“,因为它既可以是表示引用全局变量s,也可以是创建一个新的局部变量,所以在python中,默认它的行为是创建局部变量,除非显式声明global,global定义的本地变量会变成其对应全局变量的一个别名,即是同一个变量。
在d['b']=2这句中,它是“明确的”,因为如果把d当作是局部变量的话,它会报KeyError,所以它只能是引用全局的d,故不需要多此一举显式声明global。
上面这两句赋值语句其实是不同的行为,一个是rebinding(不可变对象), 一个是mutation(可变对象).。
d = {'a':1}
def f():
d = {}
d['b'] = 2
f()
print d # {'a': 1}在d = {}这句,它是”有歧义的“了,所以它是创建了局部变量d,而不是引用全局变量d,所以d['b']=2也是操作的局部变量。要改成全局变量,如下:
d = {'a':1}
def f():
global d
d={}
d['b'] = 2
f()
print (d) # {'b': 2}推而远之,这一切现象的本质就是”它是否是明确的“。
仔细想想,就会发现不止dict不需要global,所有”明确的“东西都不需要global。因为int类型str类型之类的不可变对象,每一次操作就重建新的对象,他们只有一种修改方法,即x = y, 恰好这种修改方法同时也是创建变量的方法,所以产生了歧义,不知道是要修改还是创建。而dict/list/对象等可变对象,操作不会重建对象,可以通过dict['x']=y或list.append()之类的来修改,跟创建变量不冲突,不产生歧义,所以都不用显式global。
43.4 可变对象 list 的 = 和 append/extend 差别在哪?
接上面 43.3 的理论,下面再看一例常见的错误:
# coding=utf-8
# 测试utf-8编码
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
list_a = []
def a():
list_a = [1] ## 语句1
a()
print list_a # []
print "======================"
list_b = []
def b():
list_b.append(1) ## 语句2
b()
print list_b # [1]大家可以看到为什么语句1 不能改变 list_a 的值,而 语句2 却可以?他们的差别在哪呢?
因为 = 创建了局部变量,而 .append() 或者 .extend() 重用了全局变量。
对比:
(1)
list_a = []
def a():
list_a = [1] ## 语句1
a()
print list_a # []
(2)
def func_list(a_list):
a_list[0] = 4
t_list = [1, 2, 3]
func_list(t_list)
print(t_list) # [4, 2, 3]
(3)
list_a = []
def a(a):
a[0] = 1 ## 语句1
a(list_a)
print (list_a)
结果:
Traceback (most recent call last):
File "", line 4, in
File "", line 3, in a
IndexError: list assignment index out of range 43.5 陷阱:使用可变的默认参数
如下例,运行多次时会出现问题。
def foo(a, b, c=[]):
# append to c
# do some more stuff永远不要使用可变的默认参数,可以使用如下的代码代替:
def foo(a, b, c=None):
if c is None:
c = []
# append to c
# do some more stuff 与其解释这个问题是什么,不如展示下使用可变默认参数的影响:
def foo(a, b, c=[]):
c.append(a)
c.append(b)
print(c)
foo(1, 1) # [1, 1]
foo(1, 1) # [1, 1, 1, 1]
foo(1, 1) # [1, 1, 1, 1, 1, 1]同一个变量c在函数调用的每一次都被反复引用。这可能有一些意想不到的后果。
44 Python中的exec()、eval()、complie()
https://www.cnblogs.com/yangmingxianshen/p/7810496.html
https://www.jianshu.com/p/3cf0a649e7bc
https://www.cnblogs.com/yyds/p/6276746.html
44.1 eval函数
函数的作用:
计算指定表达式的值。也就是说它要执行的Python代码只能是单个运算表达式(注意eval不支持任意形式的赋值操作),而不能是复杂的代码逻辑,这一点和lambda表达式比较相似。
函数定义:
eval(expression, globals=None, locals=None)参数说明:
- expression:必选参数,可以是字符串,也可以是一个任意的code对象实例(可以通过compile函数创建)。如果它是一个字符串,它会被当作一个(使用globals和locals参数作为全局和本地命名空间的)Python表达式进行分析和解释。
- globals:可选参数,表示全局命名空间(存放全局变量),如果被提供,则必须是一个字典对象。
- locals:可选参数,表示当前局部命名空间(存放局部变量),如果被提供,可以是任何映射对象。如果该参数被忽略,那么它将会取与globals相同的值。
- 如果globals与locals都被忽略,那么它们将取eval()函数被调用环境下的全局命名空间和局部命名空间。
返回值:
- 如果expression是一个code对象,且创建该code对象时,compile函数的mode参数是'exec',那么eval()函数的返回值是None;
- 否则,如果expression是一个输出语句,如print(),则eval()返回结果为None;
- 否则,expression表达式的结果就是eval()函数的返回值;
实例:
x = 10
def func():
y = 20
a = eval('x + y')
print('a: ', a)
b = eval('x + y', {'x': 1, 'y': 2})
print('b: ', b)
c = eval('x + y', {'x': 1, 'y': 2}, {'y': 3, 'z': 4})
print('c: ', c)
d = eval('print(x, y)')
print('d: ', d)
func()输出结果:
a: 30
b: 3
c: 4
10 20
d: None对输出结果的解释:
- 对于变量a,eval函数的globals和locals参数都被忽略了,因此变量x和变量y都取得的是eval函数被调用环境下的作用域中的变量值,即:x = 10, y = 20,a = x + y = 30
- 对于变量b,eval函数只提供了globals参数而忽略了locals参数,因此locals会取globals参数的值,即:x = 1, y = 2,b = x + y = 3
- 对于变量c,eval函数的globals参数和locals都被提供了,那么eval函数会先从全部作用域globals中找到变量x, 从局部作用域locals中找到变量y,即:x = 1, y = 3, c = x + y = 4
- 对于变量d,因为print()函数不是一个计算表达式,没有计算结果,因此返回值为None
44.2 exec函数
44.2.1 exec函数介绍
函数的作用:
动态执行Python代码。也就是说exec可以执行复杂的Python代码,而不像eval函数那么样只能计算一个表达式的值。
函数定义:
exec(object[, globals[, locals]])参数说明:
- object:必选参数,表示需要被指定的Python代码。它必须是字符串或code对象。如果object是一个字符串,该字符串会先被解析为一组Python语句,然后在执行(除非发生语法错误)。如果object是一个code对象,那么它只是被简单的执行。
- globals:可选参数,同eval函数
- locals:可选参数,同eval函数
返回值:
exec函数的返回值永远为None.
44.2.2 在Python2 和Python3中的exec() 的区别
需要说明的是在Python 2中exec不是函数,而是一个内置语句(statement),但是Python 2中有一个execfile()函数。可以理解为Python 3把exec这个statement和execfile()函数的功能够整合到一个新的exec()函数中去了,而在函数中变量默认都是局部的:
def test():
a = False
exec ("a = True")
print ("a = ", a)
test()
b = False
exec ("b = True")
print ("b = ", b)结果:
Python2:
a = True
b = True
Python3:
a = False
b = True解释:Python3 中 exec 由语句变成函数了,而在函数中变量默认都是局部的,也就是说你所见到的两个 a,是两个不同的变量,分别处于不同的命名空间中,而不会冲突。
我们可以这么改改:
def test():
a = False
ldict = locals()
exec("a=True",globals(),ldict)
a = ldict['a']
print(a)
test()
b = False
exec("b = True", globals())
print("b = ", b)44.2.3 eval()函数与exec()函数的区别
- eval()函数只能计算单个表达式的值,而exec()函数可以动态运行代码段。
- eval()函数可以有返回值,而exec()函数返回值永远为None。
实例1:
我们把实例1中的eval函数换成exec函数试试:
x = 10
def func():
y = 20
a = exec('x + y')
print('a: ', a)
b = exec('x + y', {'x': 1, 'y': 2})
print('b: ', b)
c = exec('x + y', {'x': 1, 'y': 2}, {'y': 3, 'z': 4})
print('c: ', c)
d = exec('print(x, y)')
print('d: ', d)
func()输出结果:
a: None
b: None
c: None
10 20
d: None因为我们说过了,exec函数的返回值永远为None。
实例2:
x = 10
expr = """
z = 30
sum = x + y + z
print(sum)
"""
def func():
y = 20
exec(expr)
exec(expr, {'x': 1, 'y': 2})
exec(expr, {'x': 1, 'y': 2}, {'y': 3, 'z': 4})
func()输出结果:
60
33
34对输出结果的解释:
前两个输出跟上面解释的eval函数执行过程一样,不做过多解释。关于最后一个数字34,我们可以看出是:x = 1, y = 3是没有疑问的。关于z为什么还是30而不是4,这其实也很简单,我们只需要在理一下代码执行过程就可以了,其执行过程相当于:
x = 1
y = 2
def func():
y = 3
z = 4
z = 30
sum = x + y + z
print(sum)
func()44.3 compile函数
函数的作用:
将source编译为code对象或AST对象。code对象能够通过exec()函数来执行或者通过eval()函数进行计算求值。
函数定义:
compile(source, filename, mode[, flags[, dont_inherit]])参数说明:
- source:字符串或AST(Abstract Syntax Trees)对象,表示需要进行编译的Python代码
- filename:指定需要编译的代码文件名称,如果不是从文件读取代码则传递一些可辨认的值(通常是用'
') - mode:用于标识必须当做那类代码来编译;如果source是由一个代码语句序列组成,则指定mode='exec';如果source是由单个表达式组成,则指定mode='eval';如果source是由一个单独的交互式语句组成,则指定mode='single'。必须要制定,不然肯定会报错。
实例:
s = """
for x in range(10):
print(x, end='')
print()
"""
code_exec = compile(s, '', 'exec')
code_eval = compile('10 + 20', '', 'eval')
code_single = compile('name = input("Input Your Name: ")', '', 'single')
a = exec(code_exec)
b = eval(code_eval)
c = exec(code_single)
d = eval(code_single)
e = exec(code_eval)
f = eval(code_exec)
print('a: ', a)
print('b: ', b)
print('c: ', c)
print('name: ', name)
print('d: ', d)
print('name; ', name)
print('e: ', e)
print('f: ', f) 输出结果:
0123456789 #有print就会打印
a: None # 使用的exec,因此没有返回值
b: 30
c: None
name: b
d: None
name; b
e: None
f: None44.4 globals()与locals()函数
函数定义及功能说明:
先来看下这两个函数的定义和文档描述
globals() 描述: Return a dictionary representing the current global symbol table. This is always the dictionary of the current module (inside a function or method, this is the module where it is defined, not the module from which it is called).
翻译: 返回一个表示当前全局标识符表的字典。这永远是当前模块的字典(在一个函数或方法内部,这是指定义该函数或方法的模块,而不是调用该函数或方法的模块)
locals()描述: Update and return a dictionary representing the current local symbol table. Free variables are returned by locals() when it is called in function blocks, but not in class blocks.
Note The contents of this dictionary should not be modified; changes may not affect the values of local and free variables used by the interpreter.
翻译: 更新并返回一个表示当前局部标识符表的字典。自由变量在函数内部被调用时,会被locals()函数返回;自由变量在类累不被调用时,不会被locals()函数返回。
注意: locals()返回的字典的内容不应该被改变;如果一定要改变,不应该影响被解释器使用的局部变量和自由变量。
总结:
- globals()函数以字典的形式返回的定义该函数的模块内的全局作用域下的所有标识符(变量、常量等)
- locals()函数以字典的形式返回当前函数内的局域作用域下的所有标识符
- 如果直接在模块中调用globals()和locals()函数,它们的返回值是相同的
实例1:
name = 'Tom'
age = 18
def func(x, y):
sum = x + y
_G = globals()
_L = locals()
print(id(_G), type(_G), _G)
print(id(_L), type(_L), _L)
func(10, 20)输出结果:
2131520814344 {'__builtins__': , 'func': , '__doc__': None, '__file__': 'C:/Users/wader/PycharmProjects/LearnPython/day04/func5.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F048BF4C50>, '__spec__': None, 'age': 18, '__name__': '__main__', 'name': 'Tom', '__package__': None, '__cached__': None}
2131524302408 {'y': 20, 'x': 10, '_G': {'__builtins__': , 'func': , '__doc__': None, '__file__': 'C:/Users/wader/PycharmProjects/LearnPython/day04/func5.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F048BF4C50>, '__spec__': None, 'age': 18, '__name__': '__main__', 'name': 'Tom', '__package__': None, '__cached__': None}, 'sum': 30} 实例2:
name = 'Tom'
age = 18
G = globals()
L = locals()
print(id(G), type(G), G)
print(id(L), type(L), L)输出结果:
2494347312392 {'__file__': 'C:/Users/wader/PycharmProjects/LearnPython/day04/func5.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000244C2E44C50>, 'name': 'Tom', '__spec__': None, '__builtins__': , '__cached__': None, 'L': {...}, '__package__': None, '__name__': '__main__', 'G': {...}, '__doc__': None, 'age': 18}
2494347312392 {'__file__': 'C:/Users/wader/PycharmProjects/LearnPython/day04/func5.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000244C2E44C50>, 'name': 'Tom', '__spec__': None, '__builtins__': , '__cached__': None, 'L': {...}, '__package__': None, '__name__': '__main__', 'G': {...}, '__doc__': None, 'age': 18} 上面打印出的G和L的内存地址是一样的,说明在模块级别locals()的返回值和globals()的返回值是相同的。
44.5 几个函数的关系
comiple()函数、globals()函数、locals()函数的返回结果可以当作eval()函数与exec()函数的参数使用。
另外,我们可以通过判断globals()函数的返回值中是否包含某个key来判断,某个全局变量是否已经存在(被定义)。
45 python2和python3的区别
45.1 “/”和“//”的区别
python2与python3的区别齐全【整理】:https://blog.csdn.net/pangzhaowen/article/details/80650478
使用2to3将代码移植到Python 3:https://woodpecker.org.cn/diveintopython3/porting-code-to-python-3-with-2to3.html
“ / ”:
Python2:若为两个整形数进行运算,结果为整形,但若两个数中有一个为浮点数,则结果为浮点数;
Python3:为真除法,运算结果不再根据参加运算的数的类型。
“//”:
Python2:返回小于除法运算结果的最大整数;从类型上讲,与"/"运算符返回类型逻辑一致。
Python3:和 Python2 运算结果一样。
45.2 不同数据类型间的运算
python 3的更新中,不再支持 str 和 int 直接判定。
python2 中:
- 任何两个对象都可以比较
- 相同类型的对象(实例),如果是数字型(int/float/long/complex),则按照简单的大小来比较;如果是非数字型,且类(型)中定义了__cmp__(含__gt__,__lt__等)则按照__cmp__来比较,否则按照地址(id)来比较
- 不同类型的对象(实例),如果其中一个比较对象是数字型(int/float/long/complex等),则数字型的对象<其它非数字型的对象;如果两个都是非数字型的对象,则按照类型名的顺序比较,如{} < "abc"(按照"dict" < "str"),而"abc" > [1,2], "abc" < (1,2)。
- 对于自定义的类(型)实例,如果继承自基本类型,则按照基本类型的规则比较(1-3)。否则,old-style class < new-style class, new-style class之间按照类型名顺序比较,old-style class之间按照地址进行比较
- bool类型是int的子类,且True=1, False=0,比较时按照1-4来比较,如True > -1, True < 4.2, True < "abc"等
45.3 cmp()(python2)与operator 模块(python3)
45.3.1 cmp()
cmp(x,y) 函数用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
以下是 cmp() 方法的语法:
cmp( x, y )参数
- x -- 数值表达式。
- y -- 数值表达式。
返回值:
如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
cmp() 方法也可以用于比较两个列表的元素。
语法: cmp(list1, list2)
- list1 -- 比较的列表。
- list2 -- 比较的列表。
返回值:
- 如果比较的元素是同类型的,则比较其值,返回结果。
- 如果两个元素不是同一种类型,则检查它们是否是数字。
如果是数字,执行必要的数字强制类型转换,然后比较。
如果有一方的元素是数字,则另一方的元素"大"(数字是"最小的")
否则,通过类型名字的字母顺序进行比较。
- 如果有一个列表首先到达末尾,则另一个长一点的列表"大"。
- 如果我们用尽了两个列表的元素而且所有元素都是相等的,那么结果就是个平局,就是说返回一个 0。
示例:
list1, list2 = [123, 'xyz'], [456, 'abc']
print cmp(list1, list2);
print cmp(list2, list1);
list3 = list2 + [786];
print cmp(list2, list3)结果:
-1
1
-145.3.2 operator 模块
Python 3.X 的版本中已经没有 cmp 函数,如果你需要实现比较功能,需要引入 operator 模块,适合任何对象,包含的方法有:
operator.lt(a, b)
operator.le(a, b)
operator.eq(a, b)
operator.ne(a, b)
operator.ge(a, b)
operator.gt(a, b)
operator.__lt__(a, b)
operator.__le__(a, b)
operator.__eq__(a, b)
operator.__ne__(a, b)
operator.__ge__(a, b)
operator.__gt__(a, b)这几个函数就是用来替换之前的cmp(),之前使用cmp,以后就换上面这些函数。
lt(a, b) 相当于 a < b
le(a,b) 相当于 a <= b
eq(a,b) 相当于 a == b
ne(a,b) 相当于 a != b
gt(a,b) 相当于 a > b
ge(a, b)相当于 a>= b
示例:
>>> import operator
>>> operator.eq('hello', 'name');
False
>>> operator.eq('hello', 'hello');
True46 Python 运算符
详见:https://www.runoob.com/python/python-operators.html
46.1 位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print "1 - c 的值为:", c
c = a | b; # 61 = 0011 1101
print "2 - c 的值为:", c
c = a ^ b; # 49 = 0011 0001
print "3 - c 的值为:", c
c = ~a; # -61 = 1100 0011
print "4 - c 的值为:", c
c = a << 2; # 240 = 1111 0000
print "5 - c 的值为:", c
c = a >> 2; # 15 = 0000 1111
print "6 - c 的值为:", c以上实例输出结果:
1 - c 的值为: 12
2 - c 的值为: 61
3 - c 的值为: 49
4 - c 的值为: -61
5 - c 的值为: 240
6 - c 的值为: 1546.2 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 10
b = 20
if a and b :
print "1 - 变量 a 和 b 都为 true"
else:
print "1 - 变量 a 和 b 有一个不为 true"
if a or b :
print "2 - 变量 a 和 b 都为 true,或其中一个变量为 true"
else:
print "2 - 变量 a 和 b 都不为 true"
# 修改变量 a 的值
a = 0
if a and b :
print "3 - 变量 a 和 b 都为 true"
else:
print "3 - 变量 a 和 b 有一个不为 true"
if a or b :
print "4 - 变量 a 和 b 都为 true,或其中一个变量为 true"
else:
print "4 - 变量 a 和 b 都不为 true"
if not( a and b ):
print "5 - 变量 a 和 b 都为 false,或其中一个变量为 false"
else:
print "5 - 变量 a 和 b 都为 true"结果:
1 - 变量 a 和 b 都为 true
2 - 变量 a 和 b 都为 true,或其中一个变量为 true
3 - 变量 a 和 b 有一个不为 true
4 - 变量 a 和 b 都为 true,或其中一个变量为 true
5 - 变量 a 和 b 都为 false,或其中一个变量为 false46.3 身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True46.4 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
46.5 集合的运算符
- a-b:a和b为两个set,返回存在于a中但不存在于b中的元素集合。
- a|b: a和b为两个set,返回结果为两个集合的不重复并集。
- a & b: a和b为两个set,返回结果取a和b的交集。
- a^b: a和b为两个set,返回结果为只存在于其中一个集合中的元素集合。
a = set('abcd')
b = set('cde')
print(a,b,a-b,a|b,a&b,a^b, sep = '\n')
# 结果
{'a', 'b', 'c', 'd'}
{'c', 'd', 'e'}
{'a', 'b'}
{'a', 'b', 'c', 'd', 'e'}
{'c', 'd'}
{'a', 'b', 'e'}47 isinstance() 和type()
47.1 isinstance()
描述:
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
语法:
以下是 isinstance() 方法的语法:
isinstance(object, classinfo)参数:
- object -- 实例对象。
- classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。
返回值:
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。。
实例:
以下展示了使用 isinstance 函数的实例:
a = 2
isinstance (a,int)
Out[3]: True
isinstance (a,str)
Out[4]: False
isinstance (a,(str,int,list))
Out[5]: True47.2 type() 与 isinstance()区别
isinstance() 与 type() 区别:
- type() 不会认为子类是一种父类类型,不考虑继承关系。
- isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False48 lowercase
# python 2
from string import lowercase
from random import choice, randint
print lowercase
# abcdefghijklmnopqrstuvwxyz
shorter = randint(4,7)
em = ''
for i in range(shorter):
em += choice(lowercase)
print em
# fugexg
# python3
from string import ascii_lowercase
from random import choice, randint
print (ascii_lowercase)
# abcdefghijklmnopqrstuvwxyz
shorter = randint(4,7)
em = ''
for i in range(shorter):
em += choice(ascii_lowercase)
print (em)
# fugexg
49 time.ctime()
描述:
Python time ctime() 函数把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。 如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于 asctime(localtime(secs))。
语法:
ctime()方法语法:
time.ctime([ sec ])参数:
- sec -- 要转换为字符串时间的秒数。
返回值:
该函数没有任何返回值。
实例:
以下实例展示了 ctime() 函数的使用方法:
import time
print("time.time() : %s" % time.time())
# time.time() : 1566369343.3552957
print("time.ctime() : %s" % time.ctime())
# time.ctime() : Wed Aug 21 14:35:48 201950 Python3中的最大整数和最大浮点数
50.1 最大整数
Python中可以通过sys模块来得到int的最大值。python2通过 sys.maxint 获得最大值,python3 通过 sys.maxsize 获得最大值。
# python 2
from sys import maxint
print maxint
# 2147483647
from sys import maxsize
print maxsize
# 9223372036854775807
2**31-1
# 2147483647L# python 3
from sys import maxsize
print(maxsize)
# 922337203685477580750.2 最大浮点数
python2与python3结果相同。
方法一:使用sys模块
import sys
sys.float_info
# sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1)
sys.float_info.max
# 1.7976931348623157e+308
方法二:使用float函数
infinity = float("inf")
infinity
# inf
infinity / 10000
# inf