Bi-LSTM
https://blog.csdn.net/vivian_ll/article/details/88974691
https://blog.csdn.net/jerr__y/article/details/70471066
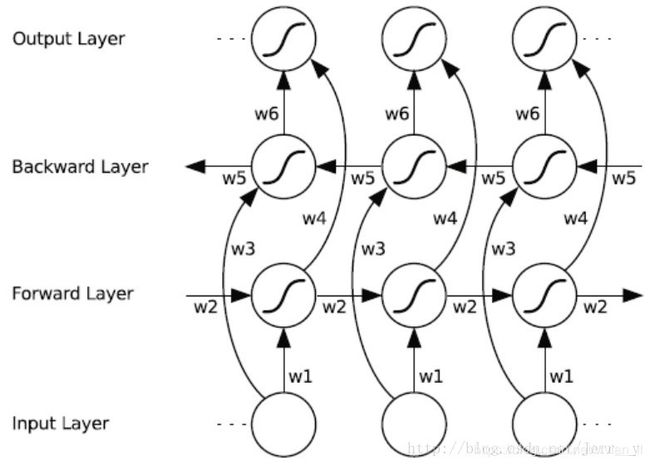
Bi-LSTM大致的思路是这样的,看图中最下方的输入层,假设一个样本(句子)有10个 timestep (字)的输入 x1,x2,…,x10x1,x2,…,x10。 现在有两个相互分离的 LSTMCell:
对于前向 fw_cell ,样本按照x1,x2,…,x10x1,x2,…,x10 的顺序输入 cell 中,得到第一组状态输出 {h1,h2,…,h10h1,h2,…,h10} ;
对于反向 bw_cell ,样本按照 x10,x9,…,x1x10,x9,…,x1 的反序输入 cell 中,得到第二组状态输出 {h10,h9,…,h1h10,h9,…,h1 };
得到的两组状态输出的每个元素是一个长度为 hidden_size 的向量(一般情况下,h1h1和h1h1长度相等)。现在按照下面的形式把两组状态变量拼起来{[h1h1,h1h1], [h2h2,h2h2], … , [h10h10,h10h10]}。
最后对于每个 timestep 的输入 xtxt, 都得到一个长度为 2*hidden_size 的状态输出 HtHt= [htht,htht]。然后呢,后面处理方式和单向 LSTM 一样。
def bi_lstm(X_inputs):
“”“build the bi-LSTMs network. Return the y_pred”""
*** 0.char embedding,请自行理解 embedding 的原理!!做 NLP 的朋友必须理解这个
embedding = tf.get_variable(“embedding”, [vocab_size, embedding_size], dtype=tf.float32)
X_inputs.shape = [batchsize, timestep_size] -> inputs.shape = [batchsize, timestep_size, embedding_size]
inputs = tf.nn.embedding_lookup(embedding, X_inputs)
** 1.LSTM 层 ***
lstm_fw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)
lstm_bw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)
** 2.dropout **
lstm_fw_cell = rnn.DropoutWrapper(cell=lstm_fw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
lstm_bw_cell = rnn.DropoutWrapper(cell=lstm_bw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
** 3.多层 LSTM ***
cell_fw = rnn.MultiRNNCell([lstm_fw_cell]*layer_num, state_is_tuple=True)
cell_bw = rnn.MultiRNNCell([lstm_bw_cell]*layer_num, state_is_tuple=True)
** 4.初始状态 **
initial_state_fw = cell_fw.zero_state(batch_size, tf.float32)
initial_state_bw = cell_bw.zero_state(batch_size, tf.float32)
# 下面两部分是等价的
# **************************************************************
# ** 把 inputs 处理成 rnn.static_bidirectional_rnn 的要求形式
# ** 文档说明
# inputs: A length T list of inputs, each a tensor of shape
# [batch_size, input_size], or a nested tuple of such elements.
# *************************************************************
# Unstack to get a list of 'n_steps' tensors of shape (batch_size, n_input)
# inputs.shape = [batchsize, timestep_size, embedding_size] -> timestep_size tensor, each_tensor.shape = [batchsize, embedding_size]
# inputs = tf.unstack(inputs, timestep_size, 1)
# ** 5.bi-lstm 计算(tf封装) 一般采用下面 static_bidirectional_rnn 函数调用。
# 但是为了理解计算的细节,所以把后面的这段代码进行展开自己实现了一遍。
try:
outputs, _, _ = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs,
initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32)
except Exception: # Old TensorFlow version only returns outputs not states
outputs = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs,
initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32)
output = tf.reshape(tf.concat(outputs, 1), [-1, hidden_size * 2])
# ***********************************************************
# ***********************************************************
# ** 5. bi-lstm 计算(展开)
with tf.variable_scope('bidirectional_rnn'):
# *** 下面,两个网络是分别计算 output 和 state
# Forward direction
outputs_fw = list()
state_fw = initial_state_fw
with tf.variable_scope('fw'):
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(output_fw, state_fw) = cell_fw(inputs[:, timestep, :], state_fw)
outputs_fw.append(output_fw)
# backward direction
outputs_bw = list()
state_bw = initial_state_bw
with tf.variable_scope('bw') as bw_scope:
inputs = tf.reverse(inputs, [1])
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(output_bw, state_bw) = cell_bw(inputs[:, timestep, :], state_bw)
outputs_bw.append(output_bw)
# *** 然后把 output_bw 在 timestep 维度进行翻转
# outputs_bw.shape = [timestep_size, batch_size, hidden_size]
outputs_bw = tf.reverse(outputs_bw, [0])
# 把两个oupputs 拼成 [timestep_size, batch_size, hidden_size*2]
output = tf.concat([outputs_fw, outputs_bw], 2)
# output.shape 必须和 y_input.shape=[batch_size,timestep_size] 对齐
output = tf.transpose(output, perm=[1,0,2])
output = tf.reshape(output, [-1, hidden_size*2])
# ***********************************************************
softmax_w = weight_variable([hidden_size * 2, class_num])
softmax_b = bias_variable([class_num])
logits = tf.matmul(output, softmax_w) + softmax_b
return logits
两个 LSTM (cell_fw, cell_bw)的计算是各自独立的,只是最后输出的时候把二者的状态向量结合起来。
2、这里我们要构造一个 2 层的 Bi-LSTM 网络,实现的时候我们首先需要声明 LSTM Cell 的列表,然后调用 stack_bidirectional_rnn() 方法即可:
cell_fw = [lstm_cell(FLAGS.num_units, keep_prob) for _ in range(FLAGS.num_layer)]
cell_bw = [lstm_cell(FLAGS.num_units, keep_prob) for _ in range(FLAGS.num_layer)]
inputs = tf.unstack(inputs, FLAGS.time_step, axis=1) # 矩阵分解,time_step即序列本身的长度,即句子最大长度max_length=32
output, _, _ = tf.contrib.rnn.stack_bidirectional_rnn(cell_fw, cell_bw, inputs=inputs, dtype=tf.float32) # 创建一个双向循环神经网络。堆叠2个双向rnn层
这个方法内部是首先对每一层的 LSTM 进行正反向计算,然后对输出隐层进行 concat,然后输入下一层再进行计算,这里值得注意的地方是,我们不能把 LSTM Cell 提前组合成 MultiRNNCell 再调用 bidirectional_dynamic_rnn() 进行计算,这样相当于只有最后一层才进行 concat,是错误的。
现在我们得到的 output 就是 Bi-LSTM 的最后输出结果了。
接下来我们需要对输出结果进行一下 stack() 操作转化为一个 Tensor,然后将其 reshape() 一下,转化为 [-1, num_units * 2] 的 shape:
output = tf.stack(output, axis=1)
output = tf.reshape(output, [-1, FLAGS.num_units * 2])
这样我们再经过一层全连接网络将维度进行转换:
Output Layer 全连接
with tf.variable_scope(‘outputs’):
w = weight([FLAGS.num_units * 2, FLAGS.category_num])
b = bias([FLAGS.category_num])
y = tf.matmul(output, w) + b # 矩阵相乘
y_predict = tf.cast(tf.argmax(y, axis=1), tf.int32) # cast张量数据类型转换,argmax针对传入函数的axis参数,去选取array中相对应轴元素值大的索引
print(‘Output Y’, y_predict)
tensorflow2.0:
class BiRNN(Model):
# Set layers.
def init(self):
super(BiRNN, self).init()
# Define 2 LSTM layers for forward and backward sequences.
lstm_fw = layers.LSTM(units=num_units)
lstm_bw = layers.LSTM(units=num_units, go_backwards=True)
# BiRNN layer.
self.bi_lstm = layers.Bidirectional(lstm_fw, backward_layer=lstm_bw)
# Output layer (num_classes).
self.out = layers.Dense(num_classes)
# Set forward pass.
def call(self, x, is_training=False):
x = self.bi_lstm(x)
x = self.out(x)
if not is_training:
# tf cross entropy expect logits without softmax, so only
# apply softmax when not training.
x = tf.nn.softmax(x)
return x