【论文笔记】SelfORE: Self-supervised Relational Feature Learning for Open Relation
SelfORE: Self-supervised Relational Feature Learning for Open Relation
导读:
4月6号挂在arXiv上,要投哪个会不用我多说了8。
阅读原因:
方向match,挂出来了总得引他。
Abstract
OpenRE是开放场景下的关系抽取,目前的工作主要是用一些启发式的方法去训练监督分类器,或者设定一些假设上使用无监督的方法。本文提出一种自监督的OpenRE,使用预训练语言模型抽取弱监督,自监督的信号,用于自适应聚类,并且在自监督过程中增加上下文特征用于关系分类,三个数据集上的实验证明了SelfORE的有效性和鲁棒性。
Introduction
第一段介绍了RE是什么
第二段介绍了标注数据繁琐,Distant Supervision的提出和作用(这段的意义应该是为强调自监督的有效性做一个铺垫)
第三段说明了OpenRE的作用,Yao 认为OpenRE是完全无监督的,Simom在无监督条件下训练了关系抽取表达式,但仍然需要预先抽取一定数量的关系。(这段的意义是描述了现有的一些OpenRE的问题,需要预先准备一些 prototype的relation坐scheme
第四段,引出了自己的论文:
为了进一步减轻手工标注
获取高质量的监督
提出一种自监督框架:
- 从数据中自己获取监督
- 提升特征表征
- 进一步提高监督质量
以上三步是一个迭代式的过程。
提出的模型主要有三个模块:
- Contextualized Relation Encoder
- Adaptive Clustering
- Relation Classification
简单来说需要的模块:
- 一个encoder(深度学习方法,是个人那都是要的)
- 一个聚类(OpenRE,是个人那还是要的)
- 关系分类器,不算特别新颖,具体还要往下看看是怎么一个分类形式。
看到这里感觉有点Neural Snowball + Open RE那味
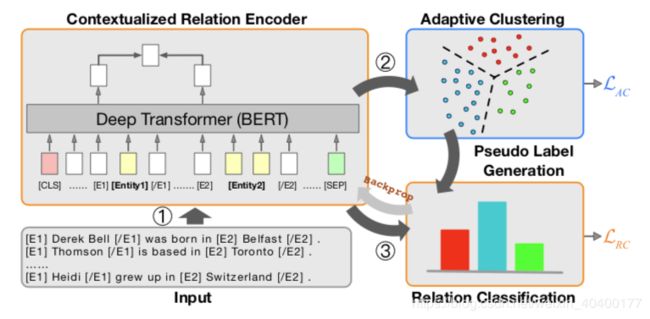
如图1,
首先1用BERT坐entity pair去encode句子和entity,生成feature representation
然后2通过representation进行聚类。聚类的结果会生成假标签,
最后3让关系分类器模块去进行分类,输入当然应该是BERT生成的特征表征了,标签就是2中生成的假标签。
分类器的误差会帮助Encoder部分进行训练,这样会导致生成的representation更优秀,然后优化聚类结果,聚类结果重新再此再次生成假标签,再优化。达到一个iterative的过程。
笔者:假不假标签无所谓,能区分出他们之间的类别就行,毕竟OpenRE本身就没有标签的。但是聚类的结果作为类别,那么聚类的效果如何保证呢?聚类出来的结果完全按照语义空间中的相似度的话,那么这样的结果再作为label,不会起到一个非常有效的监督吧,因为本身就是通过BERT产生的特征,然后利用特征的距离度量出他们属于哪些类别。个人感觉这样没有一个很强的有效的监督性,如果是我,应该会在聚类那个地方做一些处理,让其对后续的结果产生影响,这样才能有效的起到训练的作用。
目前还没有发现让人觉得特别合理的地方。下面的解释应该会让我眼前一亮。
Contribution:
- 开发SelfORE
- 使用预训练语言模型去调整representation(其实讲的还是SelfORE的内容
- 结果不错
Proposed Model
BERT就不讲了,自适应聚类这一块,不像以往的传统聚类会赋值一个hard label
(hard label就是多类别中,仅属于某一个单类别
即使预测为label1 概率0.7,label2概率0.3
按照hard label,则其属于label1。
但是按照soft label,他应该是多个label单独计算概率:
例如label1 概率0.7, label2 概率0.65 所以这个instance就属于 label1也属于label2概率超过0.5就赋值上去。)
自适应聚类使用软赋值,鼓励高概率的赋值并且与类别数量无关。
(笔者:我不太明白他说的软赋值有没有什么特殊的地方,但是按照与类别数量无关这句话来看,应该是我上面解释的soft label赋值的方法。
2.1 Encoder
这块还是BERT,暂时略过不表,在token的标注上做了一些非常常规的处理
2.2 Adaptive Clustering 自适应聚类
在这一处讲述的和之前是一样的。
具体内容包括:
-
- 将representation映射为一个新的表征(具体代码表现应该就是用一些全连接)
-
- 学习一堆的聚类中心(注意这里是学习出来的)
(笔者:这个idea挺有道理的,之前我去思考这个的时候,是觉得这个中心为其中句子向量的某种加权和,其实用个attn去做更好,因为某些句子更标准之类的。)
- 学习一堆的聚类中心(注意这里是学习出来的)
上述的表征和聚类中心的向量维度相同,上述全连接的初始化是用是预训练auto encoder的参数笔者:预训练是自己去训练的
AE的训练方式是使用的最小化重建loss,AE学习的就是分布,因此会对其映射产生一定的有效性。(但是如何保证AE的输入就是满足某些分布呢,应该与bert连接起来吧?)
聚类的核心就是标准的K-means算法
使用自由度为1的学生t分布去进行相似度的度量。
具体公式为:
q n k = ( 1 + ∣ ∣ z n − μ k ∣ ∣ 2 / α ) − α + 1 2 ∑ k ′ ( 1 + ∣ ∣ z n − μ k ′ ∣ ∣ 2 / α ) − α + 1 2 q_{nk} = \frac{(1+||\textbf{z}_{n} - \mu_k||^2/\alpha)^{-\frac{\alpha+1}{2}}}{\sum_{k'}(1+||\textbf{z}_{n} - \mu_{k'}||^2/\alpha)^{-\frac{\alpha+1}{2}}} qnk=∑k′(1+∣∣zn−μk′∣∣2/α)−2α+1(1+∣∣zn−μk∣∣2/α)−2α+1
其中 μ k \mu_k μk为聚类中心, z n \textbf{z}_{n} zn 为经过mapping的representation。
计算二者的距离平方,以其所为参数通过学生t分布。
笔者:公式下方的距离,难道不是与中心数量,聚类数量有关的吗 q n k q_{nk} qnk可以理解为第 n n n个sample属于第 k k k个聚类的概率。这是soft的
实验中自由度 α \alpha α设定为1.
通过频率normalize每个cluster作为分布的目标。
p n k = q n k 2 / f k ∑ k ′ q n k ′ 2 / f k ′ p_{nk} = \frac{q_{nk}^2/f_k}{\sum_{k'}q_{n{k'}}^2/f_{k'}} pnk=∑k′qnk′2/fk′qnk2/fk
上述的两个 p p p和 q q q分布,可以用于计算自适应聚类的loss,也就是 L A C L_{AC} LAC为KL散度的loss
笔者:这边看上去非常的nb,其实和2016年ICML Unsupervised Deep Embedding for Clustering Analysis 这篇文章中DEC的特点也是一样的。值得注意的是代码也是从那边抄的,nb
然后将最大概率的cluster,赋值一个样例为这个cluster的假label。
2.3 关系分类
使用假label作为关系分类,cross entropy,没什么新颖的
loss记为 L R C L_{RC} LRC
2.4 循环迭代优化
更新完了 L R C L_{RC} LRC, 用更新好了的encoder,再去编码relation,循环的优化。停止的条件是:假label和分类预测的差距小于10
笔者:这挺正常的,甚至我觉得这个条件可能还会导致过拟合,上一轮分类的结果导致的假标签居然和此时的一模一样,只要label数据随便标错一个顺序,都会导致误差巨大无比的
实验
做了NYT+FB, T-REx SPO, T-REx DS数据集上的信息。