实验向:Deep Forest 复现与自己数据的实现
花了半天不到的时间看了一下论文,论文地址:https://arxiv.org/abs/1702.08835
本身做图像比较多,机器学习比较少,以下只是我简单粗浅的理解。
摘要
优点:在small-scale数据集上表现良好;可以处理各类数据,结构化数据,文本数据,图像数据等等等。
1. Introduction
所谓gcForest,指的是multi-Grained Cascade Forest,主要分为两部分,即multi-Grained和Cascade部分,具体结构可以参考Figure4。
2. The Proposed Approach
2.1 Cascade Forest Structure
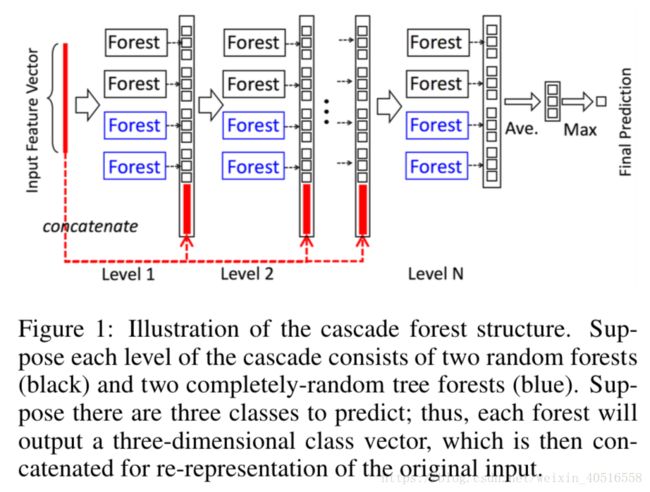
DNN中表征学习一般都是通过对原始特征进行一层一层的加工实现的。受到这一思想的启发,gcForest采用的是级联结构,如图1所示,每一层都接受来自于前一层加工的结果,再把输出结果输入到下一层中去。
从图中可以看出每一个水平都是一系列决策森林的ensemble,除此之外,每一层上为了多样性的考虑,选择了两种不同的森林,分别是completely-random trees和一般的rf,图中有2个completely-random trees和2个一般的rf,每一个completely-random trees或者一般的rf都包含500棵树。completely-random trees和一般的rf区别在于,前者是通过随机选择任意一个特征作为结点的分割,而后者则选择根号(d)个特征作为候选,然后选择其中gini系数最大的作为结点的分割。
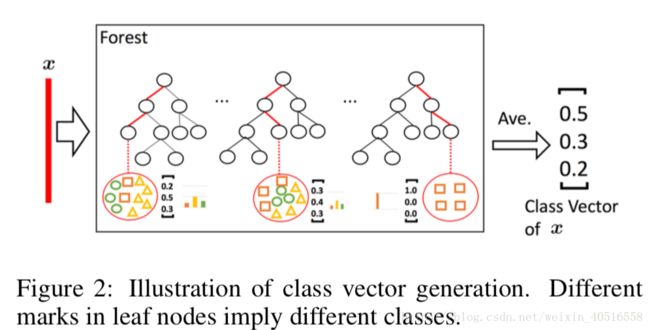
如图2所示,每一个训练样本(此处的训练样本是被sliding window加工后得到的扩充样本)输入到森林中后,进入森林中的每一棵决策树。最后在每一棵决策树的结点上得出一个3维向量,分别代表三个类别的概率。然后再求取每棵树上的平均,最后再求取整个森林上的平均,再将所有301个向量(当sliding window大小为100-dim时)进行concatenate之后输出。因此最后每个森林的输出维度为301x3=903维。
为了缓解过拟合问题,最后产生的class vector都是经过k折交叉验证过的。即,每一个instance都会被当做训练样本使用k-1次,得到k-1个class vector,然后对其求平均产生一个最后的class vector作为提升特征放入到下一level的cascade中去。在扩展一个新的水平的cascade之后,会对整个cascade的表现在验证集上进行评估,gcForest的cascade水平是自适应的,一旦模型表现没有了显著提升,训练过程就会随时停止。
2.2 Multi-Grained Scanning
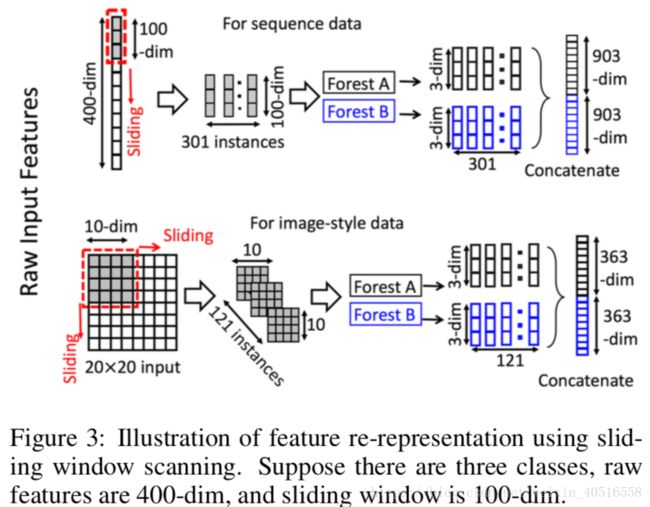
如图3所示,滑动窗口是用来对原始特征进行扫描的。假设原始特征的维数为400-dim,滑窗大小为100-dim。对于序列数据,滑动窗口滑动一次会产生一个100-dim的向量,因此总共会产生301个特征向量。如果原始特征具有空间关系,比如一个20x20大小的图片,那么一个10x10大小的滑窗会产生121个10x10大小的特征向量。提取出来的这些instances随后会被用来训练一个completely-random tree forest和一个random forest。如图3所示,假设类别为3,使用的窗口大小为100-dim;每个森林就会产生301个3-dim的class vectors,最终就会产生一个301x3x2=1806维的特征向量。如果特征向量维数太多,我们可以使用特征取样,对其进
下采样,因为completely-random tree forest和random forest对特征分割都较为不敏感甚至是没有任何关系。
通过使用不同大小的窗宽,我们就实现了Multi-Grained Scanning。

图4总结了gcForest完整的流程。假设输出原始特征为400-dim,使用三种窗宽进行多粒度扫描。对于m个训练样本,窗宽大小为100-dim的情况下,会产生301xm个100-dim的训练样本。随后这些数据将会被用来训练一个completely-random tree forest和一个random forest。对三个类别进行预测,就会生成一个1806-dim的特征向量。经过上述转化后的训练集将会被用来训练cascade forest的1st-grade。
类似地,窗宽大小为200和300的将会针对每一个训练样本分别产生1206-dim和606-dim的特征向量。转化后的特征向量,同前一层生成的提升特征进行连接后,会分别用来训练cascade forests的2nd-grade和3rd-grade。这一过程将会重复直到验证集效果手链。换句话说,最终模型实际上是一个cascade of cascade forests,其中每个cascade的的每一水平是由多个grades的cascade forests组成,每一个grade对应着一种扫描细粒度。对于更加困难的任务,可以在算力允许的情况下尝试更多细粒度。
给定一个测试样例,它会经过多细粒度扫描过程得到它对应的转变后的特征表征,然后经过cascade直到达到最后一个水平。那么如果获得最后的预测结果呢?我们通过对最后一个水平上的4个3-dim的class vectors进行加总,然后选出最大值。
表1展示了DNN和gcForest的一些超参数,gcForest中给出的是作者在实验中的一些默认值。

3. Experiments
3.1 Configuration
以下将gcForest和DNN以及其他几个流行的学习算法进行对比。发现gcForest不仅可以达到同DNN相同的效果,而且对于不同种的任务调参也变得更为简单。在所有实验中gcForest都是用的是同一种cascade结构,每一水平都包含4棵completely-random tree和4棵random forest,每一个都包含500棵树。class vector的生成使用了3折交叉验证。cascade的水平是自动决定的。细节方面,作者将训练集分为两部分,即growing set和estimating set。然后用growing set对cascade进行生长,用estimating set来估计表现情况。如果生长一个新的水平没有提升表现,那cascade的生长就终止,我们就得到了估计的水平数。在这之后,cascade又会基于growing set和estimating set上进行再训练。所有的实验中训练数据的80%作为growing set,60%作为estimating set。在多粒度扫描,选用了三种大小的滑动窗口。如果我们有d个原始特征,那选择使用ceil(d/16)、ceil(d/8)和ceil(d/4)大小的滑窗。
在DNN方面,作者选择了ReLU作为激活函数,交叉熵函数作为损失函数,adadelta作为优化方法,隐藏层的dropout rate根据训练数据规模,选择0.25或0.5。
github仓库地址:https://github.com/kingfengji/gcForest
用conda创建好虚拟环境,按照requirements配置好需要的依赖即可
最简单的调包实现方式,即建模、拟合、预测,完了- -
from gcforest.gcforest import GCForest
gc = GCForest(config) # should be a dict
X_train_enc = gc.fit_transform(X_train, y_train)
y_pred = gc.predict(X_test)目前lib中支持了几种分类器,分别是随机森林、XGB、ExtraTrees、 LR以及SGD,除此之外,可以自己手动在lib/gcforest/estimators/__init__.py添加分类器。具体分类器需要先在sklearn_estimators.py定义类。