大数据常见面试题型
1、如何安装配置Apache的一个开源Hadoop,无需细讲?
1)使用root账户登录
2)修改IP
3)修改host主机名
4)配置SSH免密码登录
5)关闭防火墙
6)安装JDK
7)解压hadoop安装包
8)配置hadoop的核心文件hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml
9)配置hadoop环境变量
10)格式化hadoop namenode-format 或hdfs namenode-format
11)启动节点 ./start-all.sh2、列出正常工作的Hadoop集群中需要启动哪些进程,分别有什么作用?
1)NameNode:是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
2)SecondaryNameNode:它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
3)DataNode:它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
4)ResourceManager:(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
5)NodeManager:(TaskTracker)执行任务
6)DFSZKFailoverController:高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为ActiveNN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
7)JournalNode:高可用情况下存放namenode的editlog文件3、HDFS的默认block是存取3份,每份默认BlockSize大小是128M(2.7.3版本以后)
4、JobTracker与NameNode是在同一节点上启动的。
hadoop的集群是基于master/slave模式,namenode和jobtracker属于master,datanode和tasktracker属于slave,master只有一个,而slave有多个。
SecondaryNameNode内存需求和NameNode在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode运行在不同的机器上。
JobTracker对应于NameNode,TaskTracker对应于DataNode。
DataNode和NameNode是针对数据存放来而言的。JobTracker和TaskTracker是对于MapReduce执行而言的。
mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:
jobclient,JobTracker与TaskTracker。
1)JobClient会在用户端通过JobClient类将已经配置参数打包成jar文件的应用存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每一个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行。
2)JobTracker是一master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务。task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。一般情况应该把JobTracker部署在单独的机器上。
3)TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。TaskTracker都需要运行在HDFS的DataNode上。5、NameNode与SecondaryNameNode有什么区别与联系?
区别:
(1)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
(2)SecondaryNameNode主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。
联系:
(1)SecondaryNameNode中保存了一份和namenode一致的镜像文件(fsimage)和编辑日志(edits)。
(2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。6、描述MapReduce中shuffle的工作流程,如何优化shuffle?
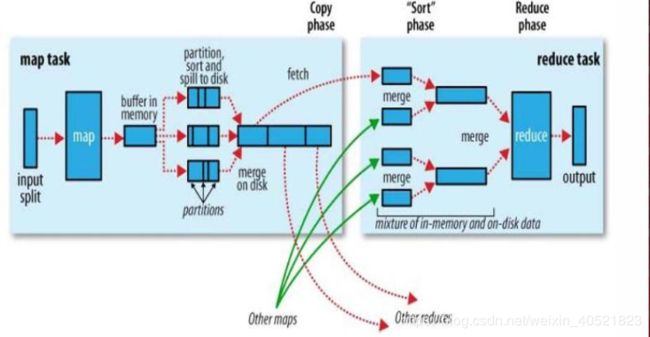
优化shuffle:
分区,排序,溢写,拷贝到对应reduce机器上,增加combiner,压缩溢写的文件。
7、Hadoop的缓存机制?
分布式缓存一个最重要的应用就是在进行join操作的时候,如果一个表很大,另一个表很小,
我们就可以将这个小表进行广播处理,即每个计算节点上都存一份,然后进行map端的连接操作,
经过我的实验验证,这种情况下处理效率大大高于一般的reduce端join,广播处理就运用到了分布
式缓存的技术。
DistributedCache将拷贝缓存的文件到Slave节点在任何Job在节点上执行之前,文件在每个
Job中只会被拷贝一次,缓存的归档文件会被在Slave节点中解压缩。将本地文件复制到HDFS中
去,接着Client会通过addCacheFile()和addCacheArchive()方法告诉DistributedCache在HDFS
中的位置。当文件存放到文地时,JobClient同样获得
DistributedCache来创建符号链接,其形式为文件的URI加fragment标识。当用户需要获得缓
存中所有有效文件的列表时,JobConf的方法getLocalCacheFiles()和getLocalArchives()都返回一
个指向本地文件路径对象数组。8、简述Hadoop1.x与Hadoop2.x的区别?
(1)加入了yarn解决了资源调度的问题。
(2)加入了对zookeeper的支持实现比较可靠的高可用。9、MapReduce运行过慢的原因是什么?
Mapreduce程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘健康、网络
2)I/O操作优化
(1)数据倾斜
(2)map和reduce数设置不合理
(3)reduce等待过久
(4)小文件过多
(5)大量的不可分块的超大文件
(6)spill次数过多
(7)merge次数过多等。10、Hadoop有哪些重大故障,该如何应对?
1)namenode单点故障:通过zookeeper搭建HA高可用,可自动切换namenode。
2)ResourceManager单点故障:可通过配置YARN的HA,并在配置的namenode上手动启动
ResourceManager作为Slave,在Master故障后,Slave会自动切换为Master。
3)reduce阶段内存溢出:是由于单个reduce任务处理的数据量过多,通过增大reducetasks数目、
优化partition规则使数据分布均匀进行解决。
4)datanode内存溢出:是由于创建的线程过多,通过调整linux的maxuserprocesses参数,增大
可用线程数进行解决。
5)集群间时间不同步导致运行异常:通过配置内网ntp时间同步服务器进行解决。11、你认为Hadoop有哪些设计不合理的地方?
1)不支持文件的并发写入和对文件内容的随机修改。
2)不支持低延迟、高吞吐的数据访问。
3)存取大量小文件,会占用namenode大量内存,小文件的寻道时间超过读取时间。
4)hadoop环境搭建比较复杂。
5)数据无法实时处理。
6)mapreduce的shuffle阶段IO太多。
7)编写mapreduce难度较高,实现复杂逻辑时,代码量太大。12、zookeeper集群中服务器间是如何进行通信?
Leader服务器会和每一个Follower/Observer服务器都建立TCP连接,同时为每个F/O都创建
一个叫做LearnerHandler的实体。LearnerHandler主要负责Leader和F/O之间的网络通讯,包括
数据同步,请求转发和Proposal提议的投票等。Leader服务器保存了所有F/O的LearnerHandler。13、Hive的特点是什么?与关系型数据库的区别?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析,但是Hive不支持实时查询。
Hive与SQL的区别:
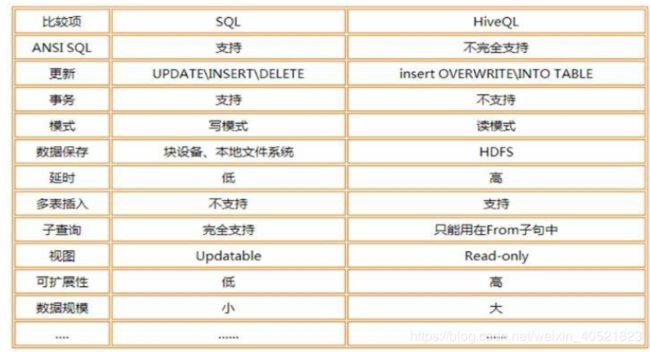
14、HBase的特点是什么?
1)大:一个表可以有数十亿行,上百万列;
2)无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
3)面向列:面向列(族)的存储和权限控制,列(族)独立检索;
4)稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
5)数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
6)数据类型单一:Hbase中的数据都是字符串,没有类型。15、HBase与Hive的区别是什么?
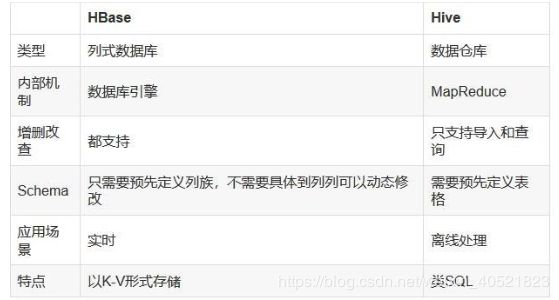
总结:
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。
16、HBase的使用场景是什么?
(1)半结构化或非结构化数据
(2)记录非常稀疏
(3)多版本数据
(4)超大数据量17、Kafka相比其他传统消息队列MQ有何优势?
(1)高性能:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作,Kafka性能远超过传统的ActiveMQ、RabbitMQ等,而且Kafka支持Batch操作;
(2)可扩展:Kafka集群可以透明的扩展,增加新的服务器进集群;
(3)容错性:Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将通知生产者和消费者从而使用其他的Broker;18、如何配置Spark的HA?
1)配置zookeeper
2)修改spark_env.sh文件,spark的master参数不在指定,添加如下代码到各个master节点
exportSPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dsparkdeploy.zookeeper.url=zk01:2181,zk02:2181,zk03:2181
-Dspark.deploy.zookeeper.dir=/spark"
3)将spark_env.sh分发到各个节点
4)找到一个master节点,执行./start-all.sh,会在这里启动主master,其他的master备节点,启动
master命令:./sbin/start-master.sh
5)提交程序的时候指定master的时候要指定三台master,例如
./spark-shell--masterspark://master01:7077,master02:7077,master03:707719、spark中worker的主要工作是什么?
主要功能:管理当前节点内存,CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务,worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务。
需要注意的是:
1)worker会不会汇报当前信息给master,worker心跳给master主要只有workid,它不会发送资源信息以心跳的方式给mater,master分配的时候就知道work,只有出现故障的时候才会发送资源。
2)worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。20、spark为什么比MapReduce快?
1)基于内存计算,减少低效的磁盘交互;
2)高效的调度算法,基于DAG;
3)容错机制Linage,精华部分就是DAG和Lingae21、spark有哪些组件?
1)master:管理集群和节点,不参与计算。
2)worker:计算节点,进程本身不参与计算,和master汇报。
3)Driver:运行程序的main方法,创建sparkcontext对象。
4)sparkcontext:控制整个application的生命周期,包括dagsheduler和taskscheduler等组件。
5)client:用户提交程序的入口。