# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,我们需要使用动态网页抓取技术。
# Ajax: Asynchronous Javascript And XML,异步JvvaScript和 XML; 在不重新加载整个网页的情况下对网页的某部分进行更新,节省流量,速度快。
# 加大了 爬虫的难度。为解决这个问题,可以采用两种技术: 1)通过浏览器审查元素解析真实网页的地址。2)使用 Selenium模拟浏览器的方法。
# 1--通过浏览器审查元素解析真实网页的地址:
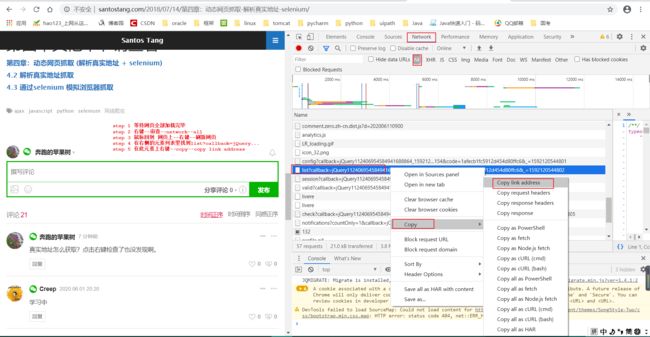
真实网址:
第一页:
https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802
第二页:
https://api-zero.livere.com/v1/comments/list?callback=jQuery112408983696804040213_1592128123614&limit=10&offset=2&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128123621
重新刷新第二页:
https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset=2&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133
第一页和第二页最明显的区别在于 offset (虽然有其他地方也不一样,但不影响,只有 offset起决定作用),所以可以通过控制 offset来翻页。
请求头:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362
# 根据上面信息,我们将代码设计为:
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
print (r.text)

# 只获取第一页评论:
# 解析得到的字符串r.text(即 json字符串)可以使用json库来完成解析:
import json
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list=json_data_dict['results']['parents']
for comment_dict in comments_list:
print(comment_dict['content'])
# 真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 获取两页评论:
import json
import requests
def get_comments(page_num):
global comments_list
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
url='https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset='\
+page_num+\
'&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133'
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的 ');'括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list.extend(json_data_dict['results']['parents']) # 列表
if __name__=='__main__':
comments_list=[]
for page_num in range(1,3):
get_comments(str(page_num))
for comment_dict in comments_list:
print(comment_dict['content'])
真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 还不够哦
# 如果这样违反了你的规定,请原谅,我也是没有办法,只能帮你把水灌上
# 不然好多代码我没有办法去按照你书上的内容操作。很郁闷
# 主人可能忘记爬虫的跟帖必须要翻过两页才能测试啊
# 是不是要10页才翻篇
# 我要追加多少评论才够两页呢
# 为什么我能看到评论呢??
# 学习
# 不是
# 我是第一个来的吗?
# 回顾:
# 1)--代码在 IDE里的换行:
a='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\
ggggg'
print(a) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
b='aaaaaaaaaaaaaaaaaaaaabbbbbbccc'\
+\
'ggggg'
print(b) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
# 2)--在输出里换行,换行符是字符串本身的一部分:
c='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\nggggg'
print(c)
# aaaaaaaaaaaaaaaaaaaaabbbbbbccc
# ggggg
i=True
if\
i==True:
print('haha')