干货!隐马尔科夫模型
公式推导
Hmmlearn
GaussianHMM
GMMHMM
MultinomialHMM
股票走势预测
特征准备
建立模型
可视化短线预测
参考资料
HMM
公式推导
在 HMM 中,有两个基本假设:
齐次 Markov 假设(未来只依赖于当前):
观测独立假设:
HMM 要解决三个问题:
Evaluation: ,Forward-Backward 算法
Learning: ,EM 算法(Baum-Welch)
Decoding: ,Vierbi 算法
预测问题:
滤波问题:
Evaluation
根据齐次 Markov 假设:
所以:
又由于:
于是:
我们看到,上面的式子中的求和符号是对所有的观测变量求和,于是复杂度为 。
下面,记 ,所以, 。我们看到:
对 :
利用观测独立假设:
上面利用了齐次 Markov 假设得到了一个递推公式,这个算法叫做前向算法。
还有一种算法叫做后向算法,定义 , :
对于这个 :
于是后向地得到了第一项。
Learning
为了学习得到参数的最优值,在 MLE 中:
我们采用 EM 算法(在这里也叫 Baum Welch 算法),用上标表示迭代:
其中, 是观测变量, 是隐变量序列。于是:
这里利用了 和 无关。将 Evaluation 中的式子代入:
对 :
上面的式子中,对 求和可以将这些参数消掉:
上面的式子还有对 的约束 。定义 Lagrange 函数:
于是:
对上式求和:
所以:
Decoding
Decoding 问题表述为:
我们需要找到一个序列,其概率最大,这个序列就是在参数空间中的一个路径,可以采用动态规划的思想。
定义:
于是:
这个式子就是从上一步到下一步的概率再求最大值。记这个路径为:
Hmmlearn
hmmlearn中有三种隐马尔可夫模型:GaussianHMM、GMMHMM、MultinomialHMM。它们分别代表了观测序列的不同分布类型。
GaussianHMM
适合用于可见层状态是连续类型且假设输出概率符合Gaussian分布的情况
class hmmlearn.hmm.GaussianHMM(n_components=1, covariance_type='diag',min_covar=0.001,
startprob_prior=1.0, transmat_prior=1.0, means_prior=0,
means_weight=0,covars_prior=0.01,covars_weight=1,
algorithm='viterbi',random_state=None, n_iter=10, tol=0.01,
verbose=False, params='stmc', init_params='stmc')
参数:
n_components:整数,指定了隐藏层结点的状态数量。
covariance_type:字符串,输出概率的协方差矩阵类型。可选值:
'spherical':球面协方差矩阵,即矩阵对角线上的元素都相等,且其他元素为零
'diag':对角协方差矩阵,即对角线元素可以是任意值,其他元素为零。
'full':完全矩阵,即任意元素可以是任意值。
'tied':所有状态都是用同一个普通的方差矩阵。
min_covar:浮点数,协方差矩阵中对角线上的最小数值,该值设置得越小模型对数据的拟合就越好,但更容易出现过度拟合。
startprob_prior:数组,形状为(n_components, )。初始状态的先验概率分布。
transmat_prior:数组,形状为(n_components, n_components )。先验的状态转移矩阵。
means_prior,means_weight:先验隐藏层均值矩阵。
covars_prior、covars_weight:先验隐藏层协方差矩阵
algorithm:字符串,指定了Decoder算法。可以为 'viterbi'(维特比算法)或者'map',map比viterbi更快速但非全局最优解。
random_state:随机种子,用于在Baum-Welch算法中初始化模型参数。
n_iter:Baum-Welch算法最大迭代次数。该值越大,训练模型对数据的拟合度越高,但训练耗时越长。
tol:指定迭代收敛阈值。该值越小(必须>=0),训练模型对数据的拟合度越高,但训练耗时越长。
verbose:是否打印Baum-Welch每次迭代的调试信息
params:字符串,在训练过程中更新哪些HMM参数。可以是四个字母中的任意几个组成的字符串。
's':初始概率。
't':转移概率。
'm':均值。
'c':偏差。
init_params:字符串,在训练开始之前使用哪些已有概率矩阵初始化模型。
's':初始概率。
't':转移概率。
'm':均值。
'c':偏差。
属性:
n_features:整数,特征维度。
monitor_:ConvergenceMonitor对象,可用它检查EM算法的收敛性。
transmat_:矩阵,形状为 (n_components, n_components),是状态之间的转移概率矩阵。
startprob_:数组,形状为(n_components, ),是初始状态的概率分布。
means_:一个数组,形状为(n_components,n_features ),每个状态的均值参数。
covars_:数组,每个状态的方差参数,其形状取决于方差类型:
'spherical':形状为(n_components, ) 。
'diag':形状为(n_components,n_features ) 。
'full':形状为(n_components, n_features, n_features) 。
'tied':形状为(n_features,n_features ) 。
方法:
decode(X, lengths=None, algorithm=None):已知观测序列X寻找最可能的状态序列。
logprob:浮点数,代表产生的状态序列的对数似然函数。
state_sequence:一个数组,形状为(n_samples, ),代表状态序列。
X:array-like,形状为 (n_samples, n_features)。指定了观测的样本。
lengths:array-like,形状为 (n_sequences, )。指定了观测样本中,每个观测序列的长度,其累加值必须等于n_samples 。
algorithm:字符串,指定解码算法。必须是'viterbi'(维特比)或者'map'。
参数:
返回值:
fit(X, lengths=None):根据观测序列 X,来训练模型参数。
在训练之前会执行初始化的步骤。如果你想避开这一步,那么可以在构造函数中通过提供init_params关键字参数来避免。
参数:X,lengths 参考 decode() 方法。
返回值:self对象。
predict(X, lengths=None):已知观测序列X,寻找最可能的状态序列。
参数:X,lengths 参考 decode() 方法。
返回值:数组,形状为(n_samples, ),代表状态序列。
predict_proba(X, lengths=None):计算每个状态的后验概率。
参数:X,lengths 参考 decode() 方法。
返回值:数组,代表每个状态的后验概率。
sample(n_samples=1, random_state=None):从当前模型中生成随机样本。
X:观测序列,长度为n_samples 。
state_sequence:状态序列,长度为n_samples 。
n_samples:生成样本的数量。
random_state:指定随机数。如果为None,则使用构造函数中的random_state。
参数:
返回值:
score(X, lengths=None):计算预测结果的对数似然函数。
参数:X,lengths 参考 decode() 方法。
返回值:预测结果的对数似然函数。
GMMHMM
混合高斯分布的隐马尔可夫模型,适合用于隐藏层状态是连续类型且假设输出概率符合GMM 分布(Gaussian Mixture Model,混合高斯分布)的情况
原型
hmmlearn.hmm.GMMHMM(n_components=1,n_mix=1,startprob_prior=1.0,transmat_prior=1.0,
covariance_type='diag', covars_prior=0.01, algorithm='viterbi',
random_state=None,n_iter=10,tol=0.01, verbose=False,
params='stmcw',init_params='stmcw')
大部分参数与GaussianHMM中的含义一样,不再重复说明,不同点有如下两个:
n_mix:整数,指定了混合高斯分布中高斯分布的数量,如果n_min等于1,则GMMHMM退化为GaussianHMM。
means_prior,means_weight,covars_prior,covars_weight:这四个参数虽然名称与GaussianHMM一致,但其维数随着n_mix的设置而不同。
属性:
n_features:整数,特征维度。
monitor_:ConvergenceMonitor对象,可用它检查EM算法的收敛性。
transmat_:矩阵,形状为 (n_components, n_components),是状态之间的转移概率矩阵。
startprob_:数组,形状为(n_components, ),是初始状态的概率分布。
gmms_:列表,指定了每个状态的混合高斯分布的分模型。
方法:参考hmmlearn.hmm.GaussianHMM 。
MultinomialHMM
多项式分布的隐马尔可夫模型,适合用于可见层状态是离散类型的情况。
原型为:
class hmmlearn.hmm.MultinomialHMM(n_components=1, startprob_prior=1.0, transmat_prior=1.0,
algorithm='viterbi', random_state=None, n_iter=10,tol=0.01,
verbose=False, params='ste', init_params='ste')
参数:整数,参考hmmlearn.hmm.GaussianHMM。
属性:
n_features:一个整数,特征维度。
monitor_:一个ConvergenceMonitor对象,可用它检查EM算法的收敛性。
transmat_:一个矩阵,形状为 (n_components, n_components),是状态之间的转移概率矩阵。
startprob_:一个数组,形状为(n_components, ),是初始状态的概率分布。
emissionprob_:一个数组,形状为(n_components, n_features),每个状态的发射概率。
方法:参考hmmlearn.hmm.GaussianHMM 。
# MultinomialHMM案例
import numpy as np
from hmmlearn import hmm
# 发射概率
emission_probability = np.array([
[0.4,0.3,0.3], # 晴:打球,读书,访友
[0.2,0.3,0.5], # 阴:打球,读书,访友
[0.1,0.8,0.1] # 雨:打球,读书,访友
])
# 转移概率
transition_probability = np.array([
[0.7,0.2,0.1],# 晴 阴 雨
[0.3,0.5,0.2],# 阴
[0.3,0.4,0.3] # 雨
])
# 定义隐藏层各状态的初始概率 晴、阴、雨
start_probability = np.array([0.5,0.3,0.2])
# 建模
model = hmm.MultinomialHMM(n_components=3) # 3种可见层状态
model.startprob_ = start_probability
model.transmat_ = transition_probability
model.emissionprob_ = emission_probability
# 0为打球,1为读书,2为访友
observe_chain = np.array([0,2,1,1,1,1,1,1,2,2,2,2,2,2,2,2,1,0]).reshape(-1,1)
# 0为晴,1为阴,2为雨
model.predict(observe_chain)
array([0, 0, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0])
股票走势预测
本案例从雅虎金融网站获取真实的历史交易数据,训练并分析历史走势,尝试寻找出历史走势规律以预测未来。下面通过用HMM模型来预测走势规律
HMM 时间轴:由于数据模型是日交易信息,所以本模型的时间轴以日为单位,即每一天是一个HMM状态结点。
可见层特征:选取数据文件中的两个重要数据作为可见层特征,即收盘涨跌值、交易量。因为这些属性为连续值,所以选用Gaussian模型。收盘涨跌值特征并未在数据模型中直接体现,它要通过计算前后两天收盘价的差值获得
隐藏层状态:定义三种状态,对应于涨、平、跌。
预测方式:通过查看隐藏层转换矩阵的转换概率,根据最后一个结点的隐藏状态预测未来一天的涨跌可能。
隐藏层的涨跌状态只受当天及之前表示层特征的影响,所以其本身并不能决定下一天的走势。而要预测下一天的隐藏层状态,需要结合转换概率矩阵进行分析。
from datetime import datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.dates import DayLocator
from hmmlearn.hmm import GaussianHMM
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
data = pd.read_csv("sample_stock.csv")
print(data.shape)
data.head()
(1258, 7)
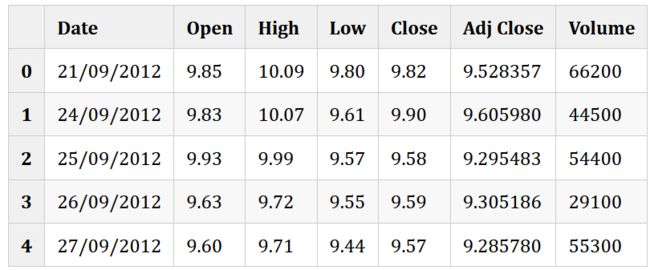
原始数据是以日为单位的某股票基础交易数据,各属性列表示:
日期
开盘价
当日最高价
当日最低价
收盘价
调整收盘
当日交易量
# 日期格式转换
data['Date'] = pd.to_datetime(data['Date'], format = "%d/%m/%Y", errors = 'coerce')
data.info()
data.head()
RangeIndex: 1258 entries, 0 to 1257
Data columns (total 7 columns):
Date 1258 non-null datetime64[ns]
Open 1258 non-null float64
High 1258 non-null float64
Low 1258 non-null float64
Close 1258 non-null float64
Adj Close 1258 non-null float64
Volume 1258 non-null int64
dtypes: datetime64[ns](1), float64(5), int64(1)
memory usage: 68.9 KB
特征准备
日期和交易量去除第一天的数据,因为第一天会被用来计算第二天的涨跌值特征,所以马尔可夫链实际是从第二天开始训练的。
dates = data['Date'].values[1:]
close_v = data['Close'].values
volume = data['Volume'].values[1:]
# 计算数组中前后两个值差额
diff = np.diff(close_v)
close_v = close_v[1:]
X = np.column_stack([diff,volume])
X.shape
(1257, 2)
建立模型
n_components 参数指定了使用3个隐藏层状态
covariance_type定义了协方差矩阵类型为对角线类型,即每个特征的高斯分布有自己的方差参数,相互之间没有影响
n_iter参数定义了Baum-Welch的最大迭代次数
model = GaussianHMM(n_components=3, covariance_type="diag",n_iter=1000)
model.fit(X)
GaussianHMM(algorithm='viterbi', covariance_type='diag', covars_prior=0.01,
covars_weight=1, init_params='stmc', means_prior=0, means_weight=0,
min_covar=0.001, n_components=3, n_iter=1000, params='stmc',
random_state=None, startprob_prior=1.0, tol=0.01,
transmat_prior=1.0, verbose=False)
print("Means and vars of each hidden state")
means_ = []
vars_ = []
for i in range(model.n_components):
means_.append(model.means_[i][0])
vars_.append(np.diag(model.covars_[i])[0])
print("第{0}号隐藏状态".format(i))
print("mean = ", model.means_[i])
print("var = ", np.diag(model.covars_[i]))
print()
Means and vars of each hidden state
第0号隐藏状态
mean = [-6.63217241e-03 5.88893426e+04]
var = [4.84610308e-02 4.85498280e+08]
第1号隐藏状态
mean = [-7.25238348e-02 4.22133974e+05]
var = [1.10870852e+00 1.09613199e+11]
第2号隐藏状态
mean = [4.41582696e-02 1.42342273e+05]
var = [1.42504830e-01 3.27804399e+09]
因为可见层输入采用了两个输入特征(涨跌幅、成交量),所以每个结点有两个元素,分别代表该状态的涨跌幅均值、成交量均值。
由于系统的目标预测涨跌幅,所以这里只关心第一个特征的均值,有如下结论:
状态0的均值是-6.63217241e-03,约为−0.00663,认为该状态是“平”。
状态1的均值是4.41582696e-02,约为0.044(涨4分钱),得知该状态是“涨”。
状态2的均值是-7.25238348e-02,约为−0.072(跌7分钱),得知该状态是“跌”。
由涨跌幅特征的方差,可以得到的信息为:
状态“平”的方差为4.84610308e-02,是三个状态中方差最小的,也就是说该状态的预测非常可信。
状态“涨”的方差为1.42504830e-01,可信度居中。
状态“跌”的方差为1.10870852e+00,是三个状态中方差最大的,即该状态的变化范围较大,并非很可信。
print("Transition matrix")
print(model.transmat_)
Transition matrix
[[0.82001546 0.01739021 0.16259432]
[0.03793618 0.22931597 0.73274785]
[0.23556112 0.04332874 0.72111014]]
第一行最大的数值是0.82001546,因此“平”倾向于保持自己的状态,即第二天仍旧为“平”。
第二行最大的数值是0.72111014,得知“涨”后第二天倾向于变为“涨”。
根据第三行状态,“跌”后第二天仍旧倾向于“涨”。
根据以上转换概率,可以看出该股票的长线态势是非常看好的。
可视化短线预测
X = X[-26:]
dates = dates[-26:]
close_v = close_v[-26:]
hidden_states = model.predict(X)
hidden_states
array([0, 0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2])
means_
[-0.0066321724101716766, -0.07252383481726057, 0.044158269609221555]
vars_
[0.048461030777305854, 1.1087085156561962, 0.1425048299475001]
model.transmat_
array([[0.82001546, 0.01739021, 0.16259432],
[0.03793618, 0.22931597, 0.73274785],
[0.23556112, 0.04332874, 0.72111014]])
# 计算当前状态后一天的预测均值
predict_means = []
predict_vars = []
for idx, hid in enumerate(range(model.n_components)):
comp = np.argmax(model.transmat_[idx]) # 最可能的第二天状态
predict_means.append(means_[comp])
predict_vars.append(vars_[comp])
print('predict_means',predict_means)
print('predict_vars',predict_vars)
predict_means [-0.0066321724101716766, 0.044158269609221555, 0.044158269609221555]
predict_vars [0.048461030777305854, 0.1425048299475001, 0.1425048299475001]
# 画图
fig, axs = plt.subplots(model.n_components + 1, sharex=True, sharey=True,figsize=(10,10))
for i, ax in enumerate(axs[:-1]):
ax.set_title("{0}th hidden state".format(i))
# Use fancy indexing to plot data in each state.
mask = hidden_states == i
yesterday_mask = np.concatenate(([False], mask[:-1]))
if len(dates[mask]) <= 0:
continue
if predict_means[i] > 0.01:
# 上涨预测
ax.plot_date(dates[mask], close_v[mask], "^", c="#FF0000")
elif predict_means[i] < -0.01:
# 下跌预测
ax.plot_date(dates[mask], close_v[mask], "v", c="#00FF00")
else:
# 平
ax.plot_date(dates[mask], close_v[mask], "+", c="#000000")
# locate specified days of the day
ax.xaxis.set_minor_locator(DayLocator())
ax.grid(True)
ax.legend(["Mean: %0.3f\nvar: %0.3f" % (predict_means[i], predict_vars[i])],
loc='center left',
bbox_to_anchor=(1, 0.5))
# 打印真实走势,用作对比
axs[-1].plot_date(dates, close_v, "-", c='#000000')
axs[-1].grid(True)
box = axs[-1].get_position()
axs[-1].set_position([box.x0, box.y0, box.width * 0.8, box.height])
ax.xaxis.set_minor_locator(DayLocator())
# 调整格式
fig.autofmt_xdate()
plt.subplots_adjust(left=None, bottom=None, right=0.75, top=None,
wspace=None, hspace=0.43)
plt.show()

由图可知,这个月中大部分隐藏状态是“平”或者“涨”,其中“涨”的数量更多,由最下方真实走势图可见当月结果确实为上涨。最后一天的结点落在了“2th hidden state”中,其预测状态为上涨(均值为0.044,方差为0.143)。
参考资料
从机器学习到深度学习
hmmlearn文档
统计学习方法
END
最后说个题外话,相信大家都知道视频号了,随着灰度范围扩大,越来越多的小伙伴都开通了视频号。小詹也开通了一个视频号,会分享互联网那些事、读书心得与副业经验,欢迎扫码关注,和小詹一起向上生长!「没有开通发布权限的尽量多互动,提升活跃度可以更快开通哦」