【论文+代码阅读】PointPillars
Brief
这篇文章整的来说是在前人的工作上做的,所以更偏向于改进。就个人感觉,目前3D方面使用2D卷积有两种形式:
- 类似mv那种,使用对3D的投影得到其2维的图像,再使用2D CNN,这样做无疑是会出现信息损失的,另外呢,先把3D点云分割成若干个体素小块,再把点个数当做二维像素值,再使用2D CNN结构,这又只使用了密度信息,没有局部几何信息。都是不太好的。
- 第二种呢就是先对点的局部提取点特征(这都要归功于pointnet),然后在利用卷积进行处理;这里呢需要说的是voxelnet是第一篇提取局部特征后去做检测的,但是使用了3D voxel检测,后续再把深度信息和通道结合成一个维度,采用二维的RPN。这里最大的鸡肋就是这个3D CNN,后续有一篇sensors上的文章只改了这个3D CNN变成了 稀疏3D卷积的形式;这一篇PointPillars则是在这两篇文章的基础上做的,直接把3DCNN取消了,采用二维CNN接手后面的操作,虽然创新点不算特别亮眼,不过也着实巧妙。
文章依旧存在的问题
- 个人觉得问题之一在过分依赖前面的特征提取,因为这是one-stage的方式,和二阶段比只有一次的回归,二阶段例如今年的PointRCNN在后续的RCNN阶段还继续对局部特征进行了整合,这里就是不会这样子操作的。
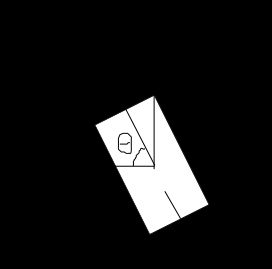
- 划分平面有点没明白,文章中所表示的是在 x − y x-y x−y平面上划分小方格子,确是俯视图,在KITTI数据集中的轴不是如下所示吗?这个图也是本文作者代码中自带的。这个
frout怕也应该是front吧。哭惹。暂且当做俯视图下的平面划分,这样会存在的问题是会对沿着z轴变化的问题不敏感。已经想到一个点去结合这个了嘻嘻。
大体结构

是不是特别简单,比voxelnet还要清晰明了,清清楚楚的三部分结构,一个很朴实好用的结构。所以除了后续的结构上使用了2D的卷积本文的最大创新点如下:
如何把3D特征转化为2D图片呢?
(1)分柱子。把俯视图分成 H × W H \times W H×W个小方格子,再沿着z轴向上拉就成了柱体。
(2)提特征。每个柱体中的点作为一个集合,采用和voxel一样的方式提取特征,最后采用最大池化为 [ T , 1 , C ] [T,1,C] [T,1,C]
(3)转化为二维。因为 T = H × W T=H\times W T=H×W,所以我们最后可以变化成 [ H , W , C ] [H,W,C] [H,W,C],这是啥,这不就是2D卷积的东西了吗。
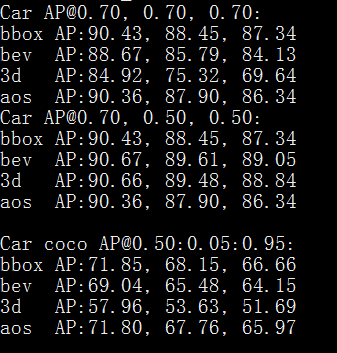
最后的效果是什么呢,是速度又快,效果还不错。如下图:
不过也验证了我刚才所说的存在的问题。
实现细节:
数据增广
首先作者对所有的gt都采集下来生成一个table,然后对每一个需要训练的point cloud都会随机选取15个gt放置到这个 里边去。每一个框都会随机旋转 [ − π / 20 , π / 20 ] [-\pi/20,\pi/20] [−π/20,π/20]
代码
这里是 code,下面我将结合code里面的README文件一步一步把代码跑起来。
我所使用的环境是:
服务器环境:也就是没有root权限,无法使用sudo apt-get安装很多软件。也包括作者所说的conda。后续我会介绍如何安装这个
无权限下手动安装anaconda
首先去官网上下载Linux版本的anconda文件。这里直接采用wget指令:
wget https://repo.continuum.io/archive/Anaconda3-2019.07-Linux-x86_64.sh
然后直接用bash进行安装就行了。
bash Anaconda3-2019.07-Linux-x86_64.sh
后面可能会让你输入很多yes,输入就可以了。最后需要安装vscode,你选择no就行了。
然后关闭终端重新打开,就如出现出下的base环境。

如果前面没有base,那么就采用conda指令激活它:
conda activate base
搭建虚拟环境和下载必要的包
这里正如作者代码中的一样,我们在base环境下一次输入下面的命令进行安装:
conda create -n pointpillars python=3.7 anaconda
source activate pointpillars
conda install shapely pybind11 protobuf scikit-image numba pillow
conda install pytorch torchvision -c pytorch
conda install google-sparsehash -c bioconda
这里需要一提的是,一开始我在python的虚拟环境中运行,始终无法解决google-sparsehash的问题,后面虽然通过编译解决了这个问题,但还是会出现诸如nvcc的divice找不到的问题。所以直接安装conda就可以不用考虑这些问题。
下面在安装一些python包
pip install --upgrade pip
pip install fire tensorboardX
git下载代码
下面这一步就是上面的代码文件,
git clone https://github.com/nutonomy/second.pytorch.git
本代码需要一个稀疏卷积的依赖,所以需要下载如下文件:
git clone [email protected]:facebookresearch/SparseConvNet.git
这里很有可能大家没有登录,无法下载,那么可以去Windows上下载下来再传到服务器上,路径是放在second.pytorchr文件下就可以了。
后续进行cuda文件扩展:
cd SparseConvNet/
bash build.sh
执行完后,就会出现很多个Python可以调用的文件了。
Setup cuda
这一步是把numba的环境变量添加给bashrc
export NUMBAPRO_CUDA_DRIVER=/usr/lib/x86_64-linux-gnu/libcuda.so
export NUMBAPRO_NVVM=/usr/local/cuda/nvvm/lib64/libnvvm.so
export NUMBAPRO_LIBDEVICE=/usr/local/cuda/nvvm/libdevice
把源文件添加到PYTHONPATN
export PYTHONPATH=你的路径
这一步主要是为了后续程序运行可以找得到对应的包文件。
准备数据
需要的数据是KITTI数据集。需要的包如下所示:

这四个文件去KITTI官网数据集下载下来。然后解压后,按照下面的形式组织(需要自己添加一个空的文件夹velodyne_reduced)
└── KITTI_DATASET_ROOT
├── training <-- 7481 train data
| ├── image_2 <-- for visualization
| ├── calib
| ├── label_2
| ├── velodyne
| └── velodyne_reduced <-- empty directory
└── testing <-- 7580 test data
├── image_2 <-- for visualization
├── calib
├── velodyne
└── velodyne_reduced <-- empty directory
这里的KITTI_DATASET_ROOT=/data/sets/kitti_second/也就是你的路径
一切准备就绪了就可以开始运行了
首先是 Create kitti infos:
python create_data.py create_kitti_info_file --data_path=KITTI_DATASET_ROOT
记得要修改KITTI_DATASET_ROOT=你的路径
然后是 Create reduced point cloud:
python create_data.py create_reduced_point_cloud --data_path=KITTI_DATASET_ROOT
这一步会把多余的点出去,因为kitti数据集中的点云的数量比它二维图像要多很多点;出去的数据会保存在刚刚建立的那两个空文件夹velodyne_reduced中。
其次是Create groundtruth-database infos:
python create_data.py create_groundtruth_database --data_path=KITTI_DATASET_ROOT
最后一点就是修改配置文件中的所有的文件路径。这些文件是如下文件:
second.pytorch\second\configs\pointpillars 文件夹下的四个配置文件
second.pytorch\second\configs\pointpillars\ped_cycle 文件夹下的四个配置文件
修改的内容是:
train_input_reader: {
...
database_sampler {
database_info_path: "/path/to/kitti_dbinfos_train.pkl"
...
}
kitti_info_path: "/path/to/kitti_infos_train.pkl"
kitti_root_path: "KITTI_DATASET_ROOT"
}
...
eval_input_reader: {
...
kitti_info_path: "/path/to/kitti_infos_val.pkl"
kitti_root_path: "KITTI_DATASET_ROOT"
}
每个文件中的KITTI_DATASET_ROOT和/path/to/kitti_infos_val.pkl和/path/to/kitti_dbinfos_train.pkl和/path/to/kitti_infos_train.pkl的路径都改成在Create groundtruth-database infos时生成的文件路径,也就是你最开始解压数据集的那个路径。
Train
准备了这么多,终于到了训练的环节了。
cd ~/second.pytorch/second
python ./pytorch/train.py train --config_path=./configs/pointpillars/car/xyres_16.proto --model_dir=/path/to/model_dir
需要把/path/to/model_dir改成你想要保存模型的路径。后续就是漫长的训练,不过在训练的inference阶段,我出现了一个小bug:也就是一个需要bool型但是代码却是一个byte的错,需要做如下的修改,如果没有报错就不用修改了。
在second.pytorch\second\pytorch\models文件夹下的voxelnet.py的911行:
opp_labels = (box_preds[..., -1] > 0) ^ dir_labels.byte()
改为:
opp_labels = (box_preds[..., -1] > 0) ^ dir_labels.bool()
接下来就是漫长的等待。

训练完后:

后续再跟,还存在代码解读和测试。
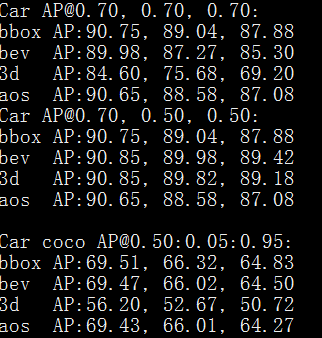
自己的修改
自己加了一个稍微的attention的机制,但是效果如下: