scrapy入门小案例--爬取电影天堂最新电影下载地址
本文开发环境:ubuntu16.04 + scrapy1.5 + python3.5 + pycharm2017.03
scrapy学习也有段时间了,刚开始也是跟着视屏一点点学习,看着挺简单的,到了动手的时候就不知道如何下手。现在通过一个小案例来总结下如何使用,如果能帮到你那我就很欣慰了。
必备技能:
- python基础 推荐廖雪峰python教程
- 网页基础 W3Cschool
- xpath 推荐W3Cschool Xpath教程
正文
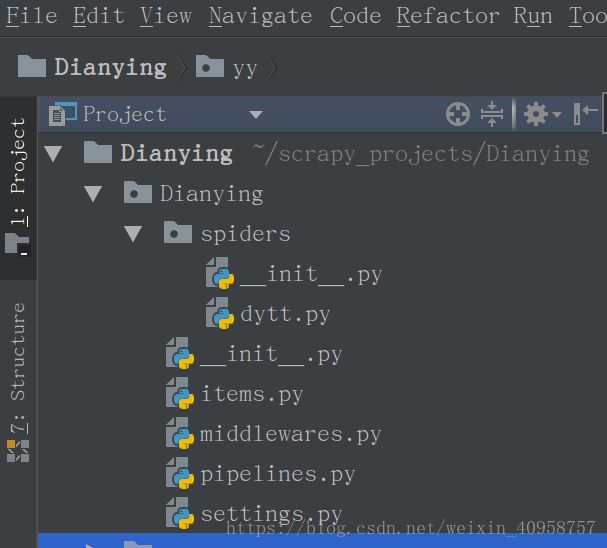
我们来看看电影天堂的网站结构。我们进入最新电影。 是不是都取到了电影名称。哈哈。同理上传日期: 名称和时间都取到了,让我们看看怎么取每部电影的下载地址。进入详情页。打开xpath helper,F12进入调试模式。可以看到有两个下载地址。既然这样,那就全要了。 迅雷: 现在我们已经取到第一页的数据,那如何跟进取到后面所有页的数据呢?一种办法是在第一页取到下一页的链接,然后进入下一页取数据。当然有第二种方法。我们右键查看源代码的时候,鼠标拉到最下边,可以看到: 这里列出了全部页面的链接。只要我们取到value的值,就可以遍历所有的页面了,哈哈,是不是很方便?电影天堂详情页虽然乱七八糟,但一点还是很赞的。 这里注意一下,有些xpath规则在xpath helper里面正常,但到了scrapy就不行。原因就是在浏览器加载页面的时候帮我们优化了,而scrapy取到的是网页源代码。这就是个坑。所以,提取规格的时候要在scrapy shell验证好。 取全部页面链接的xpath规则: 好了,现在我们就可以开始写代码了。 在命令行中: 然后使用scrapy创建默认spider文件: 我的目录结构是这样的: 1. 编写要爬取的内容items.py 2. 编写爬虫文件 我们点击第二页,第三页: 发现规律了吧,实际上就是 和刚进来的页面是一样的。只要在代码里面拼接URL就可以了。 3. 编写pipelines.py 写好pipelines.py后还要在setting.py文件注册一下才能起作用。 如果没有报错,结果: 新建Item_to_xlsx.py文件 写完后,还是要在setting.py文件中注册下,实际上上面的图中已经给出了,只是我把它注释掉了,将它打开就行。注意如果既要保存为json,又要保存excel,就把它后面的数字改一下顺序,数据越小越优先。 来看下成果: 在setting.py文件末尾定义MySQL相关配置项: 新建DBinfo_pipeline.py文件: 好了,写完了,在setting文件中注册下,跑起来: 用navicat看下: 收工。 总结: 还有就是setting.py文件中的配置,设置爬取间隔,设置USER-AGENT,还有设置IP池等,大家慢慢研究了。 over。
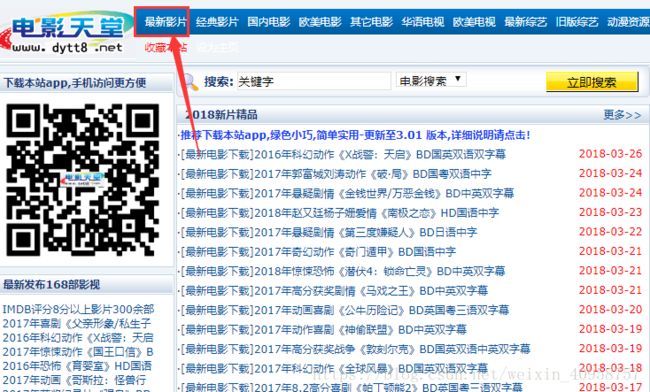
这里可以看到这里有很多电影,我们看到总共有173页。

光有下载连接可不行,我们还要电影的名称和上传时间。
下面看看怎么提取。
先回到第一页,然后CTRL + shift + X打开xpath helper,在电影名称上面右键–检查—copy–copy xpath,粘贴入Query那一栏,单击,看看是不是取到了名称,哈哈。

但是只是取到了一个,我们要这一页的全部名称,而且这么长的xpath表达式看着一点也不优雅。我们我们来修改下。
通过观察,我们所需要的内容是在一个

所以,我们的xpath规则可以写成(名称)
//div[@class='co_content8']/ul/table//a/text()//div[@class='co_content8']/ul/table//tbody//font/text()
FTP://tbody//td[@style="WORD-WRAP: break-word"]//a/@href[0]//tbody//td[@style="WORD-WRAP: break-word"]//a/@href[1]<option value='list_23_1.html' selected>1option>
<option value='list_23_2.html'>2option>
<option value='list_23_3.html'>3option>
那我们怎么取到value的值,一样的。//table//b/a/@hrefscrapy startproject Dianyingscrapy genspider dytt "www.ygdy8.net"
import scrapy
class DianyingItem(scrapy.Item):
# 电影标题
title = scrapy.Field()
# 上传时间
release_date = scrapy.Field()
# 电影详情页
url = scrapy.Field()
# 电影下载链接FTP
download_link = scrapy.Field()
# 迅雷下载链接
thunder_download_link = scrapy.Field()
# -*- coding: utf-8 -*-
import scrapy
# 导入item类
from Dianying.items import DianyingItem
class DyttSpider(scrapy.Spider):
# 爬虫名
name = 'dytt'
# 爬虫爬取的域
allowed_domains = ['www.ygdy8.net']
# 爬取页面链接
start_urls = ['http://www.dytt8.net/html/gndy/dyzz/list_23_1.html']
# 解析函数
def parse(self, response):
# 定义一个列表存放items
items = []
# 取全部标题,转化为列表
title = response.xpath('//table//b/a/text()').extract()
# 取全部上传时间,转化为列表
release_date = response.xpath('//table//font/text()').extract()
# 取全部详情页的链接
url = response.xpath('//table//b/a/@href').extract()
# 遍历列表,将结果存入items
for i in range(0, len(title)):
# 实例化一个item类,然后将结果全部存入items
item = DianyingItem()
item['title'] = title[i]
item['release_date'] = release_date[i]
# 拼接URL,获取所有电影详情的URL,拼成完整的URL来访问地址
item['url'] = 'http://www.dytt8.net' + url[i]
items.append(item)
# 如果parse函数没有解析完成,可以将结果存为字典春给meta变量,交给parse_download_link继续解析
for item in items:
yield scrapy.Request(url=item['url'], meta={'meta': item}, callback=self.parse_download_link)
# 这个是下一页跟进,从第二页开始,因为第一页我们已经爬过了。
next_urls = response.xpath('//select[@name="sldd"]/option/@value').extract()[2:]
for next_url in next_urls:
yield response.follow(next_url, callback=self.parse)
# 这个函数进入详情页获取下载地址
def parse_download_link(self, response):
# 先获取parse函数解析的结果
item = response.meta['meta']
# 取到下载链接,实际上这里有两个
download_link = response.xpath('//tbody//td[@style="WORD-WRAP: break-word"]//a/@href').extract()
# 有些电影是没有下载地址的,所以要判断一下,有的才继续下一步。
if len(download_link) is not None:
# 首先获取到FTP的地址
item['download_link'] = download_link[0]
# 有些是没有迅雷下载地址的,所以要判断一下,没有thunder_download_link就为空,不然会报错。
if len(download_link) == 2:
item['thunder_download_link'] = download_link[1]
else:
item['thunder_download_link'] = ''
# 现在我们已经拿到全部数据了,可以把item返回了。
yield item
我们来看URL链接,刚进来是这样的:http://www.ygdy8.net/html/gndy/dyzz/index.htmlhttp://www.ygdy8.net/html/gndy/dyzz/list_23_2.html
http://www.ygdy8.net/html/gndy/dyzz/list_23_3.html
list_23_xx的xx数字在变,要爬第一页打就是:http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html
现在我们拿到数据了,可以将结果保存为各种形式。
import codecs
# 导入json模块
import json
class DianyingPipeline(object):
# 初始化函数,创建json文件,指定编码格式
def __init__(self):
self.filename = codecs.open('dytt.json', 'w', encoding='utf-8')
# 将item写入,在结尾增加换行符
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.filename.write(content)
# 解析一个存一个,返回item继续跟进
return item
# 爬问后就把文件关了,释放资源
def spider_close(self, spider):
self.filename.close()
当然我们也要把USER-AGENT设置下,还有爬取时间,尊重下网站维护人员,哈哈。

![]()

好了,现在可以跑起我们的爬虫了,命令行输入:scrapy crawl dytt
4000多行,哈哈。
保存excel要安装一个python库:sudo pip install OpenPyxl
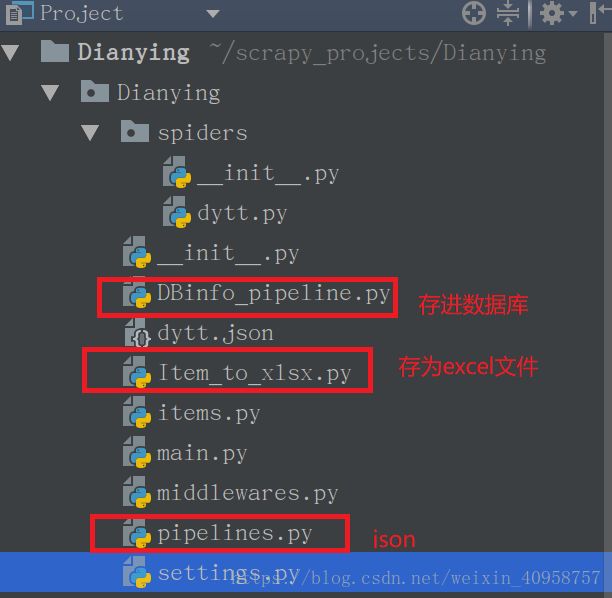
代码如下:#!/usr/bin/python
# -*- coding: utf-8 -*-
# 导入模块
from openpyxl import Workbook
class Item_to_xlsx(object):
def __init__(self):
# 先实例化一个class对象
self.wb = Workbook()
# 激活工作表
self.ws = self.wb.active
# 添加一行数据,就是excel表的第一行,标记这一列的作用
self.ws.append(['名称', '收入时间', '地址详情', '下载链接', '迅雷下载链接'])
# 下面就是把数据写入表中啦
def process_item(self, item, spider):
line = [item['title'], item['release_date'], item['url'], item['download_link'], item['thunder_download_link']]
self.ws.append(line)
self.wb.save('/home/lucky/dytt.xlsx')
跑起来:scrapy crawl dytt

也是4000多行,首行也有了我们定义的名字。哈哈。
首先得保证你的系统已经安装了MySQL,还要安装python相关库:sudo pip install pymysql# 端口
MYSQL_HOST = 'localhost'
# 数据库名称,根据自己的情况定义
MYSQL_DBNAME = 'xxx'
# 用户,根据自己的情况定义
MYSQL_USER = 'xxx'
# 密码,根据自己的情况定义
MYSQL_PASSWD = 'xxx'#!/usr/bin/python
# -*- coding: utf-8 -*-
# 导入模块
import pymysql
# 导入setting文件
from Dianying import settings
class DBinfo_pipeline(object):
# 获取seting文件的设置,并连接数据库
def __init__(self):
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True
)
self.cursor = self.connect.cursor()
# 下面就是和数据库插入有关的命令了,如果不熟悉,建议学习下mysql
def process_item(self, item, spider):
try:
self.cursor.execute(
'''insert into dytt_info(title, release_date, url, download_link, thunder_download_link)
value(%s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE download_link=VALUES(download_link), thunder_download_link=VALUES(thunder_download_link)''',
(item['title'],
item['release_date'],
item['url'],
item['download_link'],
item['thunder_download_link']))
self.connect.commit()
except Exception as error:
print(error)
return itemscrapy crawl dytt

scrapy是python网络爬虫框架。
使用它首先确定要爬取的内容,然后用xpath helper匹配出xpath规则,其实不只xpath,还可以用css选择器,beautiful soul等提取页面内容,这里就只用xpath,希望能够起到抛砖引玉的作用。
接下来就是数据的保存了,可以保存为各种格式。scrapy已经为我们提供好了,别打我,我只是想让你多学一点,哈哈。# json格式,默认为Unicode编码
scrapy crawl dytt -o dytt.json
# json lines格式,默认为Unicode编码
scrapy crawl dytt -o dytt.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl dytt -o dytt.csv
# xml格式
scrapy crawl dytt -o dytt.xml
所谓师傅带进门,修行靠个人。希望这篇文章对你有帮助。