Centos7.2 搭建ELK-5.6.4日志分析平台(一)
日志作为系统的重要的调试分析文件,是我们开发调试,运维监控,找错等。所以,必须需要建立一个日志分析平台,用于监控分析各个系统的日志。而业内最有知名的日志分析平台,则是ELK系统。是一整套完整的日志分析体系,官方地址为:https://www.elastic.co/cn/products
ELK,是Elasticsearch+Logstash+Kibana三个软件的简称,久而久之则称之为ELK,但是现在随着版本更迭,要完善整个日志分析系统,不单只需要这三个软件,而是多个软件的配合协助,构成一个完整的系统。
系统架构图如下:
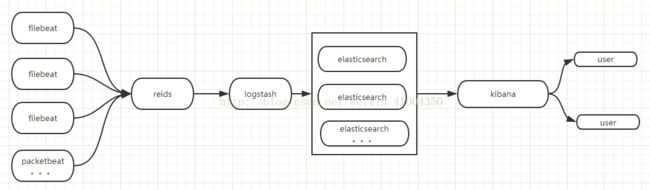
ELK从5.0版本开始,统一版本信息,一套系统对应的版本号一致,以前的旧版本就很乱,各种兼容问题也比较麻烦,现在就简单多了,具体环境如下:
filebeat-5.64: 5.6.4版本,替代以前旧版本的logstash-agent,用于安装在各个主机,收集各个主机上的日志,实时采集内容发到redis队列。现在版本将这个采集器统一合并为beat,其中包含多个不用的软件,类似filebeat是采集日志文件,packetbeat是监控主机流量。。。等等,可以根据需求,安装不同的插件。
redis-4.0.1: 这里用redis做队列, 用做暂缓filebeat传过来的数据,避免因瞬间的传输量的飙升导致logstash的崩溃,类似于一个管道,让logstash能够定量的处理数据,不会受峰值流量的影响。
logstash-5.6.4: logstash是日志采集何过滤的软件,虽然也具备filebeat一样的日志采集功能,但logstash需要运行在java虚拟机上,更重量级,消耗资源。所以不推荐用开做数据采集,只用来做数据过滤,比如将采集的日志,通过各种插件,进行分类,分端,转换成json类的易于分析分类的信息,将其存储在elasticsearch中。
elasticsearch-5.6.4:是一个基于json的数据存储分析软件,可以分布式的拓展部署,存储的数据,用于kibana调用,实现日志的分析,展示。
kibana-5.6.4:日志分析平台的可视化界面,可以在这个界面上对系统进行管理,数据分析,监控等。配合x-pack中的其他插件,可以实现各种拓展功能。
x-pack: x-pack是一个拓展功能集合的插件包,可以实现安全防护,实时监控,生成报告等拓展功能,用的最多的就是安全防护功能,默认的ELK是没有密码认证的,直接就可以登陆的,加载了x-pack后,则可以使用密码认证,证书认证等功能,来实现ELK软件之间的相互认证。
整个ELK系统都是基于java的,5.64版本需要jdk环境1.8以上。这里我的是jdk_1.8_144,操作系统:centos-7.2。jdk环境的配置,这里就不赘述了,参考我之前的博文:centos7.2 安装 JDK-1.8
下面记录一下整个elk日志分析平台的搭建流程。与遇到的一些问题,和注意事项。
1. 下载基础的elk三个软件,elasticsearch,logstash,kibana。下载地址去官网找:https://www.elastic.co/cn/products
logstash下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-6.0.0.tar.gz
elasticsearch下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
kibana下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-linux-x86_64.tar.gz
2. 在你选择安装elk的服务器上,选择一个地方,解压三个软件,我这里是放在/usr/local/下面
$ cd /usr/local/ #进入我放elk的目录
$ mkdir ELK #创建ELK文件夹,用于存放elk软件
$ tar -zxvf /usr/lcoal/ELK/logstash-6.0.0.tar.gz ## 解压各个软件,下同。
$ tar -zxvf /usr/local/ELK/elasticsearch-6.0.0.tar.gz
$ tar -zxvf /usr/local/ELK/kibana-6.0.0-linux-x86_64.tar.gz3. 先安装elasticsearch数据存储器。用于数据存储,可以分布式部署。上一步解压后,直接修改配置文件,则可以启动。这里我用了两台主机坐了一个elasticsearch的集群,如果有需求可以根据需求,增加更多的机器用于存储数据,增加elasticsearch的节点
主机IP分别为:192.168.9.89 192.168.9.90
$ vim /usr/local/ELK/elasticsearch/config/elasticsearch.yml ## 编辑配置文件
# ---------------------------------- Cluster -----------------------------------
cluster.name: ES-cluster ##设置集群名称,集群内的节点都要设置相同,可自定义
# ------------------------------------ Node ------------------------------------
node.name: ES-02 ## 节点名称,自定义,各个节点不可相同
node.master: true ## 是否作为master节点
node.data: true ## 是否作为数据节点
node.ingest: true ## 是否作为ingest节点,ingest节点则可以对数据进行加工,类似logstash的功能,定义一个管道,在索引数据时,通过指定管道进行过滤,再展示出来
# ---------------------------------- Network -----------------------------------
network.host: 192.168.9.90 ## 本机IP
http.port: 9200 ## 端口,默认9200
# --------------------------------- Discovery ----------------------------------
discovery.zen.ping.unicast.hosts: ["192.168.9.89","192.168.9.90"] ## 此集群内所有节点的IP地址,这里没有使用自动发现,而是指定地址发现,因为规模较小
discovery.zen.minimum_master_nodes: 1 ##设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点,默认为1,推荐设置为集群master节点数/2 +1 。有一定的防止脑裂的功能。
按上述配置配置完成所有节点后,启动elasticsearch还是会报错,最常见的报错有如下几种原由,根据日志报错信息可以很容易分辨原由:
1.文件最大打开数没有65536,解决办法:修改系统最大文件打开数
vim /etc/security/limits.conf ##添加如下两行,保存后重新登陆用户及生效
* soft nofile 65536
* hard nofile 655362.vm.mx_map_count 太小,没有262144
vim /etc/sysctl.conf # 添加下面一行
vm.max_map_count = 262144
systcl -p ## 加载配置3. 内存不足,elasticsearch默认是使用2G内存,在jvm的配置里可以自定义配置,在上述配置中我没有配置锁定内存,但如果有需要配置锁定内存,则很可能会报错锁定内存不足,解决办法,修改最大锁定内存。
vim /etc/security/limits.conf ## 添加下面一行,保存退出,重新登陆生效
work - memlock unlimitedOK,一一解决了这些问题后,就可以正常启动elasticsearch了,分别启动各个节点,查看日志,显示成功启动,选举出master即可。启动命令:
/usr/local/ELK/elasticsearch/bin/elasticsearch《centos7 Supervisor的安装与配置,管理elk进程。》
启动之后,可以通过访问IP的9200端口判断elasticsearch是否启动成功,访问返回elasticsearch节点信息则为成功启动。
通过访问http://192.168.9.90:9200/_cluster/health?pretty 网址来查看集群状态,成功的话,则会出现集群的名称,节点数量。集群状态可分为绿色,黄色,红色。绿色则为正常运行。
二。elasticsearch之后,则安装logastash和kibana,先后无所谓,我这里先安装kibana
解压kibana到ELK内,编辑配置文件
vim /usr/local/ELK/kibana-5.6.4-linux-x86_64/config/kibana.yml
server.port: 5601 ## kibana默认端口
server.host: "192.168.9.90" ## 服务的host,直接填本机IP即可。
elasticsearch.url: "http://192.168.9.89:9200" ## elasticsearch的连接地址,集群时,连接其中一台节点即可。启动kiban即可,启动命令:
/usr/local/ELK/kibana-5.6.4-linux-x86_64/bin/kibana依然不是后台进程,用supervisor进行管理。启动后,则可以访问本机IP的5601端口,出现kibana的界面则安装成功。(另外,记得开放端口)
第一次访问,会要求创建索引,但是因为并没有数据,所以没办法创建,这是正常的,目前暂不用进去,只要能看到界面则OK了,日后完整搭建后,会再提到。
三。logstash的安装
解压logstash到ELK内,编辑配置文件
vim /usr/local/ELK/logstash-5.6.4/config/logstash.yml
http.host: "0.0.0.0" ##修改host为0.0.0.0,这样别的电脑就可以连接整个logstash,不然只能本机连接。要启动logstash,还需要一个配置文件,来配置logstash过滤解析日志信息的规则,这个规则的配置文件则是需要自行定义,logstash对于这个规则的插件有很多,常用的有grok,kv,geoip等,这个配置文件需要有一个入口,和一个出口,中间是过滤器,一共三大部分。入口的化,根据我们的架构,是通过redis,将日志信息输入到logstash,所以入口配置为redis即可,而出口则是后面的elasticsearch数据存储器,所以出口也固定了,所以需要根据实际情况自定义的主要就是中间的过滤器filter。
下面贴出一个配置例子:
input { ## input为输入口
redis {
data_type => "list" ## 队列输入,默认输入类型为list
db => 10 ## 指定redis库
key => "redis-pipeline" ## redis是key-value式的内存数据库,指定key即是指定队列的标识key的大概意思
host => "192.168.9.79" ## 下面是连接信息,如果有密码则需要添加password这一项
port => "6379"
threads => 5 ## 线程数
}
}
filter { ## 过滤器filter
grok { ## grok插件,可以通过正则匹配,将日志的message进行格式化转换。
match => ["message","%{YEAR:YEAR}-%{MONTHNUM:MONTH}-%{MONTHDAY:DAY} %{HOUR:HOUR}:%{MINUTE:MIN}:%{SECOND:SEC},(?([0-9]*)) %{LOGLEVEL:loglevel} \[(?(.*))\] - (?(.*))"]
}
}
output { ## 输出elasticsearch
elasticsearch {
hosts => ["192.168.9.89:9200","192.168.9.90:9200"] ## 输出的elasticsearch的数据节点IP
index => "logstash-test" ## 索引值
#user => "elastic" ## elasticsearch 的用户密码,需要安装x-pack才会有,这里先不用
#password => "changeme"
}
}
好的,配置好自定义过滤转换规则后,并将其保存在 ELK/conf/all.conf ,开启logstash,启动命令:
/usr/local/ELK/logstash-5.6.4/bin/logstash -f /usr/local/ELK/conf/all.conf同上,logstash依然是使用supervisor进行管理,请参考《 centos7 Supervisor的安装与配置,管理elk进程。》
OK,到此,elk三个软件的部署搭建完成。
下一篇,讲解如何搭建filebeat对日志文件进行监控,实时采集。和如何利用grok进行数据过滤,转化成想要的格式存储再elasticsearch里,用于展示。