centos7 Graylog3 最新版安装部署与使用详解
日志管理系统,大家普遍知道的都是ELK的解决方案,但是ELK要实现认证和一些状态监控,需要安装x-pack插件包,但是x-pack是要收费的,当然可以选择破解,但是比较麻烦。而且ELK是一个解决方案,在其中包含很多软件,不单elasticsearch,kibana,logstash,还需要redis或kafaka,收集日志还需要不同的beats,整个结构非常复杂,且占用较多资源,要想完全搞懂需要较长时间。
但是很多时候,公司系统并不大,使用ELK的成本太高,可以使用一些替代方案,除了ELK还有很多日志管理工具,这里就介绍其中的一个很不错的日志方案:Graylog,Graylog是一个可以跟ELK相提并论的日志管理的后起之秀,一个开源的 log 收容器,背后的储存是搭配 mongodb,而搜寻引擎则由 elasticsearch 提供,自身集成web端,不需要单独部署,目前最新为3.0版本。
下面就详细记录一下,graylog3.0的安装与配置和使用。官方文档入口
正文
1. 准备
安装jdk8,安装方案,详见《centos7.2 安装 JDK-1.8》
安装依赖包
$ yum install epel-release -y
$ yum install pwgen -y
2.安装mongodb
$ vim /etc/yum.repos.d/mongodb-org-3.6.repo
----------------------------------------------------------------
[mongodb-org-4.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc
-----------------------------------------------------------------
# 安装
$ yum install -y mongodb-org
# 启动
$ systemctl enable mongod
$ systemctl start mongod
3. 安装elasticsearch
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# graylog3.0 使用的elasticsearch不低于5.6.13版本,我这里用的最新版6.x
$ vim /etc/yum.repos.d/elasticsearch.repo
----------------------------------------------------------------
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
----------------------------------------------------------------
# 安装
$ yum install elasticsearch
# 修改配置,设置JAVA_HOME
vim /etc/sysconfig/elasticsearch
----------------------------------------------------------------
JAVA_HOME=/usr/local/jdk1.8.0_191 # 填上自己的java_home路径
----------------------------------------------------------------
# 启动
$ systemctl enable elasticsearch
$ systemctl start elasticsearch
4.安装Groylog
$ rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-3.0-repository_latest.rpm
$ yum install graylog-server -y修改配置, password_secret和root_password_sha2是必须的,不设置则无法启动,设置方法如下:
# 修改配置
vim /etc/graylog/server/server.conf
---------------------------------------------------------------------------------
# passworde_secret可以通过命令:pwgen -N 1 -s 96 来随机生成,下面就是我随机生成的
password_secret = 6Z06fZHU2DwuOf9X8fhnvphCd3OM7oqwLECRRcejvjpieSvVtwu08yHYHIKDi56bAxRvtCOZ3xKKiBqyt00XYCgVa0oETB0L
# admin用户密码生成命令:echo -n yourpassword | sha256sum
# 生成后,请记住你的 YourPassword
root_password_sha2 = e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
# admin用户邮箱
root_email = "[email protected]"
# 时区
root_timezone = Asia/Shanghai
# elasticsearch 相关配置
elasticsearch_hosts = http://127.0.0.1:9200
elasticsearch_shards =1
elasticsearch_replicas = 0
# mongodb 连接配置,这里直接本机起的mongodb,没有设置验证
mongodb_uri = mongodb://localhost/graylog
# 电子邮件smtp,设置为自己的邮箱smtp服务
transport_email_enabled = true
transport_email_hostname = smtp.exmail.qq.com
transport_email_port = 465
transport_email_use_auth = true
transport_email_use_tls = false
transport_email_use_ssl = true
transport_email_auth_username = [email protected]
transport_email_auth_password = 123456
transport_email_subject_prefix = [graylog]
transport_email_from_email = [email protected]
transport_email_web_interface_url = http://graylog.example.com
# 网络访问相关,重要,graylog3比2.x版本简洁了很多网络配置,只需配置http_bind_address即可。
http_bind_address = 0.0.0.0:9000
# 配置外网地址,我这里用了域名+nginx做反向代理,所以外网地址如下。没有的话就直接就用外网ip+port,如:http://外网ip:9000/
http_publish_uri = http://graylog.example.com/
# http_external_uri = http://graylog.example.com/ 单节点的话,此配置不需要配置,默认使用http_publish_uri
---------------------------------------------------------------------------------
# 启动需要手动设置Java路径
vim /etc/sysconfig/graylog-server
---------------------------------------------------------------------------------
JAVA=/usr/local/jdk1.8.0_191/bin/java
---------------------------------------------------------------------------------
# 启动服务
$ systemctl enable graylog-server
$ systemctl start graylog-server
5. 访问web页面
按照上面配置,直接配置成外网ip地址,那么直接访问 http://外网ip:9000,就可以进入web登陆页面

输入用户密码登陆

6. 安装Graylog Sidecar(Graylog Collector Sidecar)
Graylog Sidecar是一个轻量级配置管理系统,适用于不同的日志收集器,也称为后端。Graylog节点充当包含日志收集器配置的集中式集线器。在支持的消息生成设备/主机上,Sidecar可以作为服务(Windows主机)或守护程序(Linux主机)运行。进行在不同机器上进行日志的采集并发送到graylog server
在graylog3.0版本以前,称为Graylog Collector Sidecar,在3.0中改为了Graylog Sidecar,在官方文档中有详细安装指导:官方文档入口。这里也参考进行安装。版本对照表如下,首先去github上下载相应的rpm安装包。官方GITHUB下载地址
| Sidecar version | Graylog server version |
|---|---|
| 1.0.x | 3.0.x |
| 0.1.x | 2.2.x,2.3.x,2.4.x,2.5.x,3.0.x |
| 0.0.9 | 2.1.x |
# 安装
$ rpm -i graylog-sidecar-1.0.0-1.x86_64.rpm
# 修改配置
$ vim /etc/graylog/sidecar/sidecar.yml
----------------------------------------------------------------------------
server_url: "hhttp://graylog.example.com/api/" # api的外网地址
# api token 必要的,不然启动不了,token需要在web界面上进行手动创建
server_api_token: "1jq26cssvc6rj4qac4bt9oeeh0p4vt5u5kal9jocl1g9mdi4og3n"
node_name: "graylog-server-localhost" # 自定义节点名称
update_interval: 10
send_status: true
----------------------------------------------------------------------------
# 安装系统服务
$ graylog-sidecar -service install
$ systemctl start graylog-sidecar
手动创建server_api_token。如图:


ok,到此就可以启动graylog-sidecar了。启动后,在web界面上就可以看到一个节点了,然后下面记录怎么手动配置这个节点的日志采集。首先需要创建一个beats的input,因为我要要用filebeat进行日志采集。

然后就需要定义sidecar的filebeat配置,用这个配置来启动filebeat进行日志采集,并输入到上面定义的beats input。但是graylog3.0中,graylog sidecar的linux版本不包含filebeat(3.0版本之前是默认包含filebeat的),需要自己手动下载安装filebeat,安装非常简单,通过官方下载页面,直接下载rpm包进行安装就行: 官方下载地址
PS:我这里是演示的用filebeat进行日志采集,如果用nxlog进行采集,同样的需要安装nxlog程序。
# 安装,目前最新版6.6.0
rpm -i filebeat-6.6.0-x86_64.rpmok,就这样就ok啦,然后下面在web界面上进行配置


这里我以采集本机上graylog-server的日志为例子,自定义变量中定义beats input服务的ip和端口,使得sidecar采集器能将数据输入指定input,并可以在所有配置中直接复用。

配置创建完成后,需要将配置与指定sidecar进行联系,然后sidecar就能以执行配置启动filebeat进行日志采集。如图:


然后就能在web界面上,看到采集到的graylog-server的日志

OK,到此,就演示了安装graylog-server和graylog-sidecar的全部过程。根据具体的实际情况,安装sidecar并设置配置就可以。
7. 配置报警设置
首先,在安装graylog-server是需要想我上面那样,配置email的smtp的配置。然后才能使用邮件进行告警通知。
然后第一步,需要设置告警通知,如图,配置时sender一定要与你smtp配置中配置的邮箱相同,不然无法成功发送邮件。



配置好后,Test成功收到邮件即OK。
下面配置触发事件条件,这里我进行测试,定义了一个简单的条件,5分钟后,日志数量超过1条就报警,然后就会触发通知的配置发送报警邮件。实际情况中,具体的报警触发配置就需要自己根据实际情况进行设置。

8.整个Springboot等Java项目的日志输入到graylog中
下面演示如何将JAVA项目的日志输入到graylog中,常见的JAVA项目不管是不是分布式都会使用日志工具,常见的有log4j,logback,这里我以logback作为演示。只需要在项目中映入相关插件依赖然后在logback.xml中配置就能实现自己由服务将日志传输到graylog,就不需要使用filebeat进行日志文件的读取再输入到graylog了。这里推荐一个插件,官方github地址:logstash-gelf
下面开始,先在graylog web界面上定义一个 gelf input:

然后,在JAVA项目中,添加maven依赖最新版本1.13.0:
biz.paluch.logging
logstash-gelf
1.13.0
然后修改项目logback.xml文件配置,添加如下appender,并启用:
udp:172.18.73.131
12201
1.1
test-java-module # 这里可以定义为服务名等
true
true
true
yyyy-MM-dd HH:mm:ss,SSS
8192
mdcField1,mdcField2
mdc.*,(mdc|MDC)fields
true
除来上面的配置外,还可以手动添加静态字段,详细可以看插件的GITHUB官网。
OK,启动服务,就能在graylog web上看到输入的日志了:

ok,到此就可以收到日志数据了,在实际工作中,服务日志会非常多,这么多的日志,如果不进行存储限制,那么不久就会占满磁盘,查询变慢等等,而且过久的历史日志对于实际工作中的有效性也会很低,graylog则自身集成了日志数据限制的配置,可以通过如下进行设置:

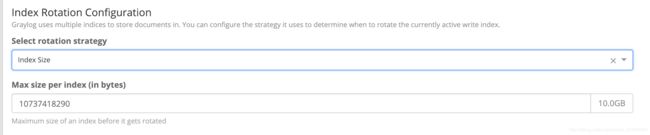
这里提供了三种方式进行限制,1,限定日志数据量,数据量达到是便会自动删除最旧的历史数据,以维持数据量恒定 2.限定大小,指定数据文件总容量大小 3. 限定时间,删除超时的日志数据。 可根据自己的实际情况进行设置。
9. Graylog进阶使用
上面介绍的都是graylog的基础使用和配置,在配置了之后,已经可以实现对日志的采集,日志的监控报警。下面就简单演示一下如何创建仪表盘,在过程中熟悉一下graylog中的搜索,流,索引,管道,装饰器等等。
在有了日志数据后,在web界面的search中,就可以搜索到日志数据了,如图

途中就是search界面,最上面可以选择时间端,默认是最近5分钟,第二行是搜索的语法,这个语法很简单,最常用的如,搜索level为3的日志,就是 level:3,就这么简单,多条匹配规则可以通过AND,OR(连接词必须大写)进行连接。要搜索包含abc的日志,就直接输入 abc 就行了。整体来说相对于elk要简单很多。具体的完整用法,参考官方文档:搜索
然后我们要定义仪表盘,首先需要创建一个仪表盘,只需要输入标题和说明就行:

创建完仪表盘后你会发现,没发直接在仪表盘中添加部件,也就是添加数据图形等。仪表盘中的部件只能通过在search页面中通过生产徒刑后点击 add to dashboard 来添加到仪表盘中,添加后可以进行修改删除。详细的可以参考官网文档:仪表盘
先看一下我简单添加的仪表盘,

这里演示一下:在search页面中,选择字段,字段下面会有4个选项,可以生产4个不同的图形分析,如图:

其中,最后一个是地图map分析,这个需要额外添加地图信息插件等。这里暂时不说。其他三个都是可以直接出来分析徒刑的。比如我想要知道环境-微服务的总数,因为上面整合springboot的时候,配置中将facility地段自定义为 环境-微服务,如test-device 。所以我直接点击facility下的Statistics,就会生产如下表格:

如图,Cardinality就是环境-微服务不同的数量,也就是接收到日志的环境-微服务总数。点击add to dashboard就能添加到仪表盘,添加之前需要特别注意一点: 时间段,搜索的时间段会影响图形的数据量,添加到仪表盘后会作为默认的时间段来展示数据。当然也可以在添加后,再修改部件属性中修改时间等。

这里就演示这一个部件的添加,其他的可以自行不断尝试,然后有一个需要单独说一下,扩展一下大家思路,比如我想知道时间段内error日志的数量,error日志所属的环境-服务的排序,以此来分析error日志。就需要配合搜索和时间来进行,比如,我们可以搜索1天内,日志界别为ERROR的数据Severity:ERROR ,然后以这些数据生成图形就可以实现了,如:

OK,仪表盘就讲到这里了,下面讲一下Streams(流),Indices(索引)。
我们知道elasticsearch是以索引来存储数据的,启动graylog后,会自动生产一个默认的索引,索引地段值就为graylog,如下图。上面我们还在其中配置过数据存储限制,可以通过时间,大小,数量来进行存储限制。

为什么要说这个了,就是在实际生产情况中,日志来源并不是单一的,除了java应用服务日志,可能还有nginx访问日志,系统日志等等。这种时候就会产生重要性的问题,比如,生产环境的nginx访问日志,要保存1年。而测试环境的应用服务日志,只需要保存7天就可以了这种不同情况的需求,为了能更好的区分不同类型的日志,我们就可以创建不同的索引,来储存不同类型的日志。比如创建test环境,prod环境的索引来区分环境,创建nginx,web-app等来区分nginx和应用web服务等。如图创建prod环境日志:

索引创建后,需要创建stream(流)来讲收到的日志进行匹配,将匹配的日志存入新的索引。以此来形成区分,系统默认存在all message流来存入default index set中,在创建流的时候,可以定义匹配到的数据,在存入新的索引时,是否删除默认存入的索引数据,以保存数据只存一份,不然会存在多份相同日志数据。创建stream,如图,创建时选择此stream匹配的日志存入的索引。

创建后,配置stream的匹配规则,匹配支持正则表达式,Type中选match regular expression(正则表达式),如下图。

如图所示,规则之间可以选择是 "且" 还是 "或" 。 就是多条规则是都匹配才成功,还是只需要匹配其中一条就成功。规则添加成功后,点击 i'm done 。然后点击 Start Stream启动Stream就可以了。
这样就可以将日志数据进行分类保存了。好的。进阶的使用先说到这。至于日志Grok数据提取,和管道处理,后面有空再更新
结束
ok,Graylog3.0的安装与详细的使用演示到这里就差不多了,别的细节和没说到的,具体的还是参考官方文档,以官方文档为准。然后,谢谢大家耐心看到最后。