论文地址:基于隐马尔科夫模型的电话语音频带扩展
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/12151866.html
摘要
本文提出了一种从lowpass-bandlimited(低通带限)语音中恢复宽带语音的算法。窄带输入信号被分类为有限数量的语音,关于宽带频谱包络的信息取自预先训练的码本。在码本搜索算法中,采用了一种基于隐马尔可夫模型的统计方法,该方法考虑了带限语音的不同特征,使均方误差准则最小化。新算法只需要一个宽带码本,本质上保证了系统在基带的透明性。增强后的语音比输入语音的带宽大得多,而且没有引入令人讨厌的artifacts(伪影)。
1 引言
在目前的公共电话系统中,传输语音的带宽被限制在300 Hz到3.4 kHz的频率范围内。这导致了典型的电话语音通常是单薄和低沉的。然而,近年来,我们发现人们对语音通信系统的质量要求越来越高,不仅要求高的可懂度,还要求高的主观质量,例如在免提电话或电话会议应用中。这种趋势反映在正在进行的宽带语音编解码器的标准化上。
真正的宽带语音通信需要增强的语音编解码器和提高的比特率,因此需要修改传输链路。因此,出于经济原因,带宽限制在未来不太可能改变。另一种获得更高带宽的方法是仅利用带限语音来推断传输链路接收端语音信号中缺失的低频和高频成分。
这种语音信号的带宽扩展只有基于语音产生过程的模型时才是可行的。宽带源模型的参数可以从带限语音中估计出来。这些参数可以与源模型结合使用来估计和添加缺失的频率。
本文只讨论带宽向更高频率的扩展,即假设输入信号只包含低于3.4 kHz的频率(这个频段将在下文中定义为基带)。通过增加信号分量,它将扩展到频率高达7khz。
2 算法
根据语音产生过程的自回归(AR)模型,将提出的带宽扩展算法分为两个任务,这两个任务在一定程度上是相互独立的:语音信号的频谱包络线的扩展和激励信号的扩展[1]。算法框图如图1所示。
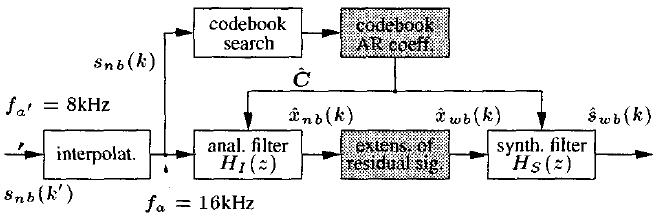
图1 带宽扩展算法的块图和主信号流
如果输入信号$s_{nb}(k')$采样频率为$f_{a'}=8kHz$,则算法的第一步是一个low-pass interpolation(低通插值滤波器)。算法其余部分以$f_a = 16khz$的采样率处理输入信号。然而,信号$s_{nb}(k)$仍然只包含3.4 kHz以下的信号分量。进一步的处理是以20 ms的帧大小逐帧进行的。在下面,帧索引将由变量$m$表示。
使用窄带输入信号和预先训练的码本,计算当前语音帧的宽带谱包络的估计值(参见第3节)。然后从码本中提取描述该谱包络的AR滤波器系数$\hat{C}$,并将其用于FIR滤波器$H_1(z)$中以估计窄带激励信号$\hat{x}_{nb}$。由于对于无声帧,该激励信号的基带可以假定为近似白色,而对于有声帧,该激励信号的基带分别由振幅相等的谐波组成,因此其带宽可以非常简单地扩展(请参见第4节)。最终将扩展的激励信号$\hat{x}_{wb}(k)$馈入全极点合成滤波器$H_S(z)$,从而创建增强的输出信号$\hat{s}_{wb}(k)$。
与以往的语音信号带宽扩展算法(如[1, 2, 3])不同,所提出的算法不需要几个窄码本和宽带码本的组合。它只利用一个单一的宽带码本。因此,用于分析滤波器和合成滤波器的AR系数是相同的,而且这两个滤波器的传递函数是互逆的
$$公式1:H_s(z)=\frac{1}{H_1(z)}$$
由于这一特性,系统基带信号分量的透明性可以得到保证——这足以确保在残余信号扩展期间激励信号的基带不被修改。
3 频谱包络
如前一节所述,语音信号的频谱包络的扩展基于宽带码本。在该码本中,存储了代表典型语音频谱包络的几组AR系数(在下文中,第$i$组AR系数将由$C_i$表示。 码本条目的总数为$I$)。使用足够大的宽语音语音训练数据集和常用的LBG算法[4]对码本进行训练,从而最大程度地减少Itakuro距离测度(请参见[l])。尽管使用宽带语音材料对码本进行训练可以确保在码本中包含正确的代表不同语音的声音,但是这也带来了挑战,即对于输入信号的分类,即对输入信号的分类只有带限信号可用。
码本搜索方法的基础是语音生成过程的隐马尔可夫模型(HMM)。 HMM的恰好一个状态$S_i$被分配给码本的每个条目$C_i$。 进一步假设源的状态仅在输入信号的两个帧之间发生变化。 注意,如果宽带语音可用,则在模型意义上可以计算出真实状态序列。
如果只知道窄带语音,则通过以下步骤执行分类:首先,从窄带语音中提取有限数量的特征。将这些提取的特征与语音产生过程的统计模型进行比较。然后将当前的语音帧划分为训练好的语音或直接估计AR系数。
3.1 特征
对于每个信号帧,从bandlimited(带限)信号中提取一个$N$维特征向量$x(m)$。该向量由8个倒谱系数$c_1...c_8$,归一化帧能量$E_n$和[5]中定义的梯度指数$d_n$组成
$$公式2:
d_{n}=\frac{\sum_{k=2}^{K} \Delta \psi(k)\left|s_{n b}(k)-s_{n b}(k-1)\right|}{\sqrt{\frac{1}{K} \sum_{k=1}^{K} s_{n b}^{2}(k)}}
$$
式中$K$为每帧采样数,变量$\phi(k)$表示梯度$c_{nb}(k)-s_{nb}(k-1)$的标记,即$\psi (k)\in \{-1,1\}$,$\triangle \psi(k)=\frac{1}{2}|\psi(k)-\psi(k-1)|$。
倒谱系数包含窄带信号的频谱包络的形状信息,而其他两个量取决于语音激励的性质。此外,以上十个主要特征随时间的导数都包含在特征向量中,使得该向量$x(m)$的维数为$N = 20$。
3.2 统计模型
对于隐马尔可夫模型的每个可能状态$S_i$,语音产生过程产生的特征$x$表现出不同的统计特性。为了描述这些性质,我们使用了由以下三部分组成的统计模型。
3.2.1 观察概率$p(x|S_i)$
由于特征向量x的维度较高,这些概率密度函数(probability density function,pdf)$p(x|S_i)$由高斯混合模型(GMMS)建模:每个pdf被近似为$L$个高斯pdf的和。
$$公式3:
p\left(\boldsymbol{x} | S_{i}\right) \approx \sum_{l=1}^{L} P_{i l} \mathcal{N}\left(\boldsymbol{x} ; \mu_{i l}, \Sigma_{i l}\right)
$$
在这个方程中,$N(x;\mu_{il},\sum_{il})$表示具有平均矢量$\mu_{il}$和方差矩阵$\sum_{il}$的GMM的第$l$个N维高斯分布。每个高斯分布都由一个系数$P_{il}$加权,$\sum_{l=1}^LP_{il}=1$。
GMMs的训练,即$P_{il}$、$\mu_{il}$和$\sum_{il}$,可以用期望最大化(EM)算法(例如[ 6 ])来进行。这里用LBG算法[4]对训练数据进行聚类来确定。
对于隐马尔可夫模型的每个状态,必须使用完整训练材料的子集来训练一个不同的GMM,对于该GMM,其真实状态等于当前训练的状态。
3.2.2 初始状态概率$\pi_i=P(S_i)$
标量值$\pi_i$描述了HMM驻留在状态$S_i$中而不包含特征向量$x$或先后状态的概率。
该概率可以通过计算训练材料的真实状态序列和评估状态$S_i$的出现次数与训练集中的语音帧总数之间的比率来估计。通过码本存储所得到的概率值,使得实际的带宽扩展算法以后可以通过表查找来访问这些先验状态概率。
3.2.3 转移概率$a_{ij}=P(S_i(m+1)|S_j(m))$
变量$a_{ij}$描述了从状态$S_j$转换到状态$S_i$的概率。作为初始状态概率$\pi_i$,可以将转移概率存储在现在为二维的表中。在训练过程中,在了解了真实状态序列的情况下,将该表中的每个条目估计为从$S_j$到$S_i$的特定转换的发生次数与$S_j$状态的总发生次数之间的比率。
3.3 估计宽带AR系数
码本搜索算法的目标是计算宽带AR系数的估计值$\hat{C}$,使到真实系数C的距离最小。
对于估计规则的推导,将辅助变量$\alpha_i(m)$定义为部分观测序列$X(m)=\{x(0),x(1),...,x(m)\}$和状态$S_i(m)$在m帧时刻
$$公式4:\alpha_i(m)=P(S_i(m),X(m))$$
该辅助变量可以用联合概率$\alpha_i(m-1)$在m-1时刻的递归形式表示,观察概率$p(x(m)|S_i(m))$为
$$公式5:\alpha_i(m)=(\sum_{j=1}^I\alpha_j(m-1)a_{ij})p(x(m)|S_i(m))$$
由于前一个观测向量在第一帧是未知的,所以$\alpha_i(0)$的初始值必须由初始状态概率$\pi_i$计算
$$公式6:\alpha_i(0)\pi_ip(x(0)|S_i)$$
MMSE准则的目标是最小化估计AR系数$\hat{C}$与真实系数$C$之间的均方误差,从而使以下代价函数最小化
$$公式7:
\mathcal{R}_{\mathrm{MSE}}(\hat{\boldsymbol{C}} | \boldsymbol{X})=\iint(\hat{\boldsymbol{C}}-\boldsymbol{C})^{T}(\hat{\boldsymbol{C}}-\boldsymbol{C}) p(\boldsymbol{C} | \boldsymbol{X}) d \boldsymbol{C}
$$
通过对损失函数的导数求根,可以找到这个优化问题的一个解
$$公式8:
\hat{C}_{\text {natst }}=\iint \boldsymbol{C} p(\boldsymbol{C} | \boldsymbol{X}) d \boldsymbol{C}
$$
由于我们没有条件概率$p(C|X)$的显式模型,这个量必须以状态概率的形式间接表示
$$公式9:
\hat{C}_{\text {hass }}=\iint \boldsymbol{C}\left[\sum_{i=1}^{I} p\left(\boldsymbol{C} | S_{i}\right) P\left(S_{i} | \boldsymbol{X}\right)\right] d \boldsymbol{C}
$$
$$公式10:
=\sum_{i=1}^{I} P\left(S_{i} | \boldsymbol{X}\right) \underbrace{\iint \boldsymbol{C} p\left(\boldsymbol{C} | S_{i}\right) d \boldsymbol{C}}_{\mathcal{E}\left\{\boldsymbol{C} | S_{i}\right\}=\boldsymbol{C}_{i}}
$$
如图所示,在状态$S_i$出现的情况下,方程10右侧的积分得到C的期望值,即对应的码本向量$C_i$。应用贝叶斯规则,代入辅助变量$\alpha_i$,得到如下估计
$$公式11:
\hat{C}_{\text {mats } E}=\frac{\sum_{i=1}^{I} C_{i} \alpha_{i}(m)}{\sum_{i=1}^{I} \alpha_{i}(m)}
$$
由于$p(C|X)$是通过状态概率间接建模的,因此该估计器不能利用条件概率$p(C|S_i)$。可以通过直接建模和利用$p(C|X)$来设计一个更好的MMSE估计器,但这不是一项简单的任务。另外,可以在码本向量$C_i$的训练过程中考虑$p(C|S_i)$的知识。
4 剩余信号
由于窄带激励信号$\hat{x}_{nb}(k)$在base-band(基频)上近似为白色,因此计算宽频带激励信号的公式为
$$公式12:
\hat{x}_{w b}(k)=\left\{\begin{array}{ll}
{2 \hat{x}_{n b}(k)} & {; k=0, \pm 2, \pm 4 \ldots} \\
{0} & {; \text { else }}
\end{array}\right.
$$
这种操作导致了功率谱的折叠。因此,在$\hat{x}_{wb}(k)$中存在3.4到4.6 kHz的频谱间隙。另外,高频区域的谐波结构与低频分量不匹配。然而,在合成滤波器$H_S(z)$后,这些影响几乎听不见。
5 评估
为了评估所提出的算法,训练了几个不同尺寸的码本。在聆听算法的最佳输出时,即在已知true state sequence(真实状态序列)的情况下,发现对于大于I = 64的码本,增强信号与原始宽带语音几乎无法区分。即使是非常小的I = 3条目的codebook,也可以获得可接受的结果。
训练数据由截止频率为3.4 kHz的低通滤波器对宽带语音进行滤波得到。它由几位男女演讲者讲了大约10分钟的语音平衡的干净的话术组成。
在许多非正式的和比较的听力测试中,所描述的算法产生了良好的结果——显著地扩展了带宽。偶尔会出现声音伪影,,主要出现在[s]或[f]等清音摩擦音中,这是由码本搜索算法错误分类造成的。然而,算法中先验知识的使用越多,此类伪影的出现频率就越低。
6 总结
该方法能够将低通带限语音的带宽扩展到最高7kHz的频率范围。结果证明,在低频区域有足够的信息可以成功地估计高频成分的缺失,但是,对于这种估计,除了频谱包络之外,还应该利用窄带语音的更多特征。为此目的,提出的统计模型,是一个适当的工具。
7 参考文献
[1] H. Carl, “Untersuchung verschiedener Methoden der Sprachcodierung und eine Anwendung zur BandbreitenvegroBerung von Schmalband-Sprachsignalen”. Dissertation.Ruhr-Universitat Bochum, 1994
[2] J. Epps, W. H. Holmes, “A New Technique for Wideband Enhancement of Coded Narrowband Speech”. IEEE Workshop on Speech Coding. Porvoo, Finland, 1999
[3] N. Enbom, W. B. Kleijn, “Bandwidth Expansion of Speech Based on Vector Quantization of the Me1 Frequency Cepstral Coefficients”. IEEE Workshop on Speech Coding, Porvoo,Finland, 1999
[4] Y. Linde, A. Buzo, R. M. Gray, “An Algorithm for Vector Quantizer Design”. IEEE Trans. on Communications, January 1980
[5] J. Paulus, “Codierung breitbandiger Sprachsignale bei niedriger Datenrate”. Dissertation, RWTH Aachen, 1997
[6] S. V. Vaseghi, “Advanced Signal Processing and Digital Noise Reduction”. Wiley, Teubner, 1996