Python爬虫与正则表达式
Python爬虫与正则表达式
一.Python中通配符的使用
1.表示方式
| 表示 | 意义 |
|---|---|
* |
匹配0到任意字符 |
? |
匹配单个字符 |
. |
当前 |
.. |
当前的上一级 |
[0-9] |
0到9的任意一个数字 |
[a-z] |
a到z的任意一个字母 |
[A-Z] |
A到Z的任意一个字母 |
[a-zA-Z] |
a到z或者A到Z之间的任意一个字母 |
注意:以下内容在Linux Shell中可以识别,但在Python中不能被识别
| 表示 | 意义 |
|---|---|
[[:digit:]] |
匹配一个数字 |
[[:algha:]] |
匹配一个字母 |
[[:upper:]] |
匹配一个大写字母 |
[[:lower:]] |
匹配一个小写字母 |
[[:space:]] |
匹配一个空格 |
2.Python中的使用
glob模块
glob模块可以使用Unix shell风格的通配符匹配符合特定格式的文件和文件夹,跟windows的文件搜索功能差不多。glob模块并非调用一个子shell实现搜索功能,而是在内部调用了os.listdir()和fnmatch.fnmatch()。
(1).glob.glob: 返回所有匹配正则的路径(返回的是一个列表)
print(glob.glob('/etc/*.conf'))
print(glob.glob('/etc/????.conf', recursive=True))
print(glob.glob('/etc/*[0-9]*.conf'))
print(glob.glob('/etc/*[A-Z]*.conf'))
print(glob.glob('/etc/*[0-9A-Z]*.conf'))
![]()
(2).glob.iglob: 返回所有匹配正则的路径(返回的是一个生成器)
print(glob.iglob('/etc/*[0-9A-Z]*.conf'))
![]()
二.正则表达式
python标准库中用于正则表达式的为re模块
re = regular expression 正则表达式
作用: 对于字符串进行处理, 会检查这个字符串内容是否与你写的正则表达式匹配,如果匹配, 拿出匹配的内容;如果不匹配, 忽略不匹配内容。
1.编写正则的规则
即将需要匹配的字符串的样式表示出来,一般为pattern = r'str' (str为需要匹配的字符串)
pattern(模式)
2.findall方法
在表达了所要搜寻的字符串之后,使用findall()方法在指定范围(字符串或前端代码)中寻找。
import re
s = "kiosk/home/kiosk/westosanaconda2/envs/blog/bin/python3.6/home/kiosk/Desktop/villa"
# 1. 编写正则的规则
pattern1 = r'villa'
pattern2 = r'kiosk'
# 2. 通过正则去查找匹配的内容
print(re.findall(pattern1, s))
print(re.findall(pattern2, s))

3.match方法
match()尝试从字符串的起始位置开始匹配
- 如果起始位置没有匹配成功, 返回一个None
- 如果起始位置匹配成功, 返回一个对象
print(re.match(pattern1, s))
matchObj = re.match(pattern2, s)
# 返回match匹配的字符串内容;
print(matchObj.group())

4.search方法
search()会扫描整个字符串, 只返回第一个匹配成功的内容
- 如果能找到, 返回一个对象, 通过group方法获取对应的字符串
match1Obj = re.search(pattern1, s)
print(match1Obj.group())
match2Obj = re.search(pattern2, s)
print(match2Obj.group())

5.split方法
split()方法: 指定多个分隔符进行分割
# split()方法: 指定多个分隔符进行分割;
import re
ip = '172.25.254.250' #与一般的split方法进行比较
print(ip.split('.'))
s = '12+13-15/16'
print(re.split(r'[\+\-\*/]', s))

6.sub方法
sub()方法:指定内容进行替换
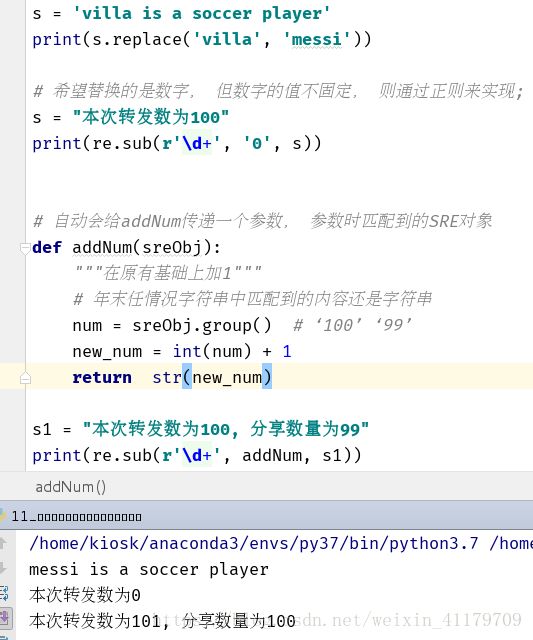
s = 'villa is a soccer player'
print(s.replace('villa', 'messi'))
# 希望替换的是数字, 但数字的值不固定, 则通过正则来实现;
s = "本次转发数为100"
print(re.sub(r'\d+', '0', s))
# 自动会给addNum传递一个参数, 参数时匹配到的SRE对象
def addNum(sreObj):
"""在原有基础上加1"""
# 年末任情况字符串中匹配到的内容还是字符串
num = sreObj.group() # ‘100’ ‘99’
new_num = int(num) + 1
return str(new_num)
s1 = "本次转发数为100, 分享数量为99"
print(re.sub(r'\d+', addNum, s1))
7.正则表达式特殊字符类
| 特殊序列符号 | 意义 |
|---|---|
| \A | 只在字符串开始进行匹配 |
| \Z | 只在字符串结尾进行匹配 |
| \b | 匹配位于开始或结尾的空字符串 |
| \B | 匹配不位于开始或结尾的空字符串 |
| \d | 相当于[0-9] |
| \D | 相当于[^0-9] |
| \s | 匹配任意空白字符:[\t\n\r\r\v] |
| \S | 匹配任意非空白字符:[^\t\n\r\r\v] |
| \w | 匹配任意数字和字母:[a-zA-Z0-9] |
| \W | 匹配任意非数字和字母 |
import re
# 字符类:
print(re.findall(r'[^0-9]', 'villa123villa'))
print(re.findall(r'[0-9]', 'villa123villa'))
# 特殊字符类 .
print(re.findall(r'.', 'villa\n'))
# 特殊字符类\d
print(re.findall(r'\d', '当前文章阅读量为8'))
# 等待学习匹配次数的规则
print(re.findall(r'\d', '当前文章阅读量为8000'))
# 特殊字符类\D
print(re.findall(r'\D', '当前文章阅读量为8'))
# 等待学习匹配次数的规则
print(re.findall(r'\D', '当前文章阅读量为8000'))
# 特殊字符类\s, \S
print(re.findall(r'\s', '\n当前\r文章阅\t读量为8'))
# 等待学习匹配次数的规则
print(re.findall(r'\S', '\n当前\r文章阅\t读量为8'))
# 特殊字符类\w, \W
print(re.findall(r'\w', '12当前villa文章阅_读量为8&'))
# 等待学习匹配次数的规则
print(re.findall(r'\W', '12当前villa文章阅_读量为8&'))
效果如下:

8.指定字符出现指定次数
| 表示 | 意义 |
|---|---|
: |
代表前一个字符出现0次或者无限次 d* 、 .* |
+ |
代表前一个字符出现一次或者无限次 d+ |
? |
代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用 d? |
{m } |
前一个字符出现m次 |
{m,} |
前一个字符至少出现m次 * == {0,} + ==={1,} |
{m,n} |
前一个字符出现m次到n次? === {0,1} |
import re
print(re.findall(r'd*', ''))
print(re.findall(r'd*', 'ddd'))
print(re.findall(r'd*', 'dwww'))
print(re.findall(r'.*', 'westos'))
print(re.findall(r'd+', ''))
print(re.findall(r'd+', 'ddd'))
print(re.findall(r'd+', 'dwww'))
print(re.findall(r'd+', 'westos'))
print(re.findall(r'188-?', '188 6543'))
print(re.findall(r'188-?', '188-6543'))
print(re.findall(r'188-?', '148-6543'))
pattern = r'\d{3}[\s-]?\d{4}[\s-]?\d{4}'
print(re.findall(pattern,'188 6754 7645'))
print(re.findall(pattern,'18867547645'))
print(re.findall(pattern,'188-6754-7645'))


三.正则表达式案例
1.匹配邮箱
首先写出所需要邮箱的正则表达式:pattern = r'[A-z]\w{5,11}@qq\.com'
ps:字符串中添加一些字符串干扰
import re
pattern = r'[A-z]\w{5,11}@qq\.com'
s = """
各种格式的邮箱入下所示:
[email protected]
2. [email protected]
[email protected]
[email protected]
3. [email protected]
4. [email protected]
[email protected]
5. [email protected]
6. [email protected]
7. [email protected]
8. [email protected]
9. [email protected]
具体释义入下:
1.163邮箱
提供以@163.com为后缀的免费邮箱,3G空间,支持超大20兆附件,280兆网盘。精准过滤超过98%的垃圾邮件。
2.新浪邮箱
提供以@sina.com为后缀的免费邮箱,容量2G,最大附件15M,支持POP3。
3.雅虎邮箱
提供形如@yahoo.com.cn的免费电子邮箱,容量3.5G,最大附件20m,支持21种文字。
4.搜狐邮箱
提供以@sohu.com结尾的免费邮箱服务,提供4G超大空间,支持单个超大10M附件。强大的反垃圾邮件系统为您过滤近98%的垃圾邮件。
5.QQ邮箱
提供以@qq.com为后缀的免费邮箱,容量无限大,最大附件50M,支持POP3,提供安全模式,内置WebQQ、阅读空间等。
"""
dataLi = re.findall(pattern, s)
with open('email.txt', 'w') as f:
for email in dataLi:
f.write(email + '\n')
结果如下:

2.匹配IP地址
pattern = r'[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}'
import re
pattern = r'[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}'
print(re.findall(pattern, '172.25.0.2'))
print(re.findall(pattern, '172.25.1.2'))
print(re.findall(pattern, '172.25.1.278'))
# | 代表或者的意思
pattern1 = r'^(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)$'
# print(re.findall(pattern1, '172.25.1.278'))
# print(re.findall(pattern1, '172.25.1.178'))
Obj = re.match(pattern1, '172.25.1.178')
if Obj:
print("查找到匹配的内容:", Obj.group())
else:
print('No Found')
Obj = re.match(pattern1, '172.25.1.278')
if Obj:
print("查找到匹配的内容:", Obj.group())
else:
print('No Found')

四.初入爬虫
爬虫简述:
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
1.爬取贴吧中某一帖子的所有邮箱
第一步通过爬虫获取该网址的内容
使用urlopen打开指定页面
再使用.read()读取页面内容
最后decode(‘utf-8’)使用utf-8的解码方式使页面内容解码为unicode
第二步通过网页内容, 使用正则表达式获得符合正则的所有邮箱
import re
def getPageContent(url):
"""
获取网页源代码
:param url: 指定url内容
:return: 返回页面的内容(str格式)
"""
with urlopen(url) as html:
return html.read().decode('utf-8')
def parser_page(content):
"""
根据内容获取所有的贴吧总页数;
:param content: 网页内容
:return: 贴吧总页数
"""
pattern = r'(\d+)'
data = re.findall(pattern, content)
return data[0]
def parser_all_page(pageCount):
"""
根据贴吧页数, 构造不同的url地址;并找出所有的邮箱
:param pageCount:
:return:
"""
emails = []
for page in range(int(pageCount)):
url = 'http://tieba.baidu.com/p/xxxxxxxxxxxxpn=%d' %(page+1) # 此处网站省略
print("正在爬取:%s" %(url))
content = getPageContent(url)
# pattern = r'\w[-\w.+]*@[A-Za-z0-9][-A-Za-z0-9]+\.+[A-Za-z]{2,14}'
pattern = r'[a-zA-Z0-9][-\w.+]*@[A-Za-z0-9][-A-Za-z0-9]+\.+[A-Za-z]{2,14}'
findEmail = re.findall(pattern, content)
print(findEmail)
emails.append(findEmail)
return emails
def main():
url = 'http://tieba.baidu.com/p/xxxxx'
content = getPageContent(url)
pageCount = parser_page(content)
emails = parser_all_page(pageCount)
print(emails)
with open('tiebaEmail.txt', 'w') as f:
for tieba in chain(*emails):
f.write(tieba + '\n')
main()

(此处数据省略)
2.爬取贴吧中某一帖子的所有图片
import re
from urllib.request import urlopen
def get_content(url):
"""
获取网页内容
:param url:
:return:
"""
with urlopen(url) as html:
return html.read()
def parser_get_img_url(content):
"""
解析贴吧内容, 获取所有风景图片的url
:param content:
:return:
"""
pattern = r'![]() '
imgUrl = re.findall(pattern, content.decode('utf-8').replace('\n', ' '))
return imgUrl
def main():
url = 'http://tieba.baidu.com/p/5437043553'
content = get_content(url)
imgLi = parser_get_img_url(content)
for index,imgurl in enumerate(imgLi):
# 根据图片的url获取每个图片的内容;
content = get_content(imgurl)
with open('img/%s.jpg' %(index+1), 'wb') as f:
f.write(content)
print("第%s个图片下载成功...." %(index+1))
main()
'
imgUrl = re.findall(pattern, content.decode('utf-8').replace('\n', ' '))
return imgUrl
def main():
url = 'http://tieba.baidu.com/p/5437043553'
content = get_content(url)
imgLi = parser_get_img_url(content)
for index,imgurl in enumerate(imgLi):
# 根据图片的url获取每个图片的内容;
content = get_content(imgurl)
with open('img/%s.jpg' %(index+1), 'wb') as f:
f.write(content)
print("第%s个图片下载成功...." %(index+1))
main()


3.保存cookie信息
cookie:某些网站为了辨别用户身份, 只有登陆之后才能访问某个页面;
进行一个会话跟踪, 将用户的相关信息包括用户名等保存到本地终端
# 1. 如何将Cookie保存到变量中, 或者文件中;
# 1). 声明一个CookieJar ---> FileCookieJar --> MozillaCookie
cookie = cookiejar.CookieJar()
# 2). 利用urllib.request的HTTPCookieProcessor创建一个cookie处理器
handler = HTTPCookieProcessor(cookie)
# 3). 通过CookieHandler创建opener
# 默认使用的openr就是urlopen;
opener = request.build_opener(handler)
# 4). 打开url页面
response = opener.open('http://www.baidu.com')
# 5). 打印该页面的cookie信息
print(cookie)
for item in cookie:
print(item)
# 2. 如何将Cookie以指定格式保存到文件中
# 1). 设置保存cookie的文件名
cookieFilename = 'cookie.txt'
# 2). 声明一个MozillaCookie,用来保存cookie并且可以写入文进阿
cookie = cookiejar.MozillaCookieJar(filename=cookieFilename)
# 3). 利用urllib.request的HTTPCookieProcessor创建一个cookie处理器
handler = HTTPCookieProcessor(cookie)
# 4). 通过CookieHandler创建opener
# 默认使用的openr就是urlopen;
opener = request.build_opener(handler)
# 5). 打开url页面
#response = opener.open('http://www.baidu.com')
# 6). 打印cookie,
print(cookie)
print(type(cookie))
# ignore_discard, 即使cookie信息将要被丢弃。 也要把它保存到文件中;
# ignore_expires, 如果在文件中的cookie已经存在, 就覆盖原文件写入;
cookie.save(ignore_discard=True, ignore_expires=True)

保存到文件中效果如下图时示:

从文件中获取cookie并访问
# 1). 指定cookie文件存在的位置
cookieFilename = 'cookie.txt'
# 2).声明一个MozillaCookie,用来保存cookie并且可以写入文件, 用来读取文件中的cookie信息
cookie = cookiejar.MozillaCookieJar()
# 3). 从文件中读取cookie内容
cookie.load(filename=cookieFilename)
# 4). 利用urllib.request的HTTPCookieProcessor创建一个cookie处理器
handler = HTTPCookieProcessor(cookie)
# 5). 通过CookieHandler创建opener
# 默认使用的openr就是urlopen;
opener = request.build_opener(handler)
# 6). 打开url页面
response = opener.open('http://www.baidu.com')
#7). 打印信息
print(response.read().decode('utf-8'))
