实时流式处理平台功能介绍
作者:赵平
导读:在上一篇Wormhole系列文章中,我们介绍了Wormhole的设计思想,并给出了Stream、UMS、Flow、Namespace等相关概念的具体定义,从文章中我们得知,Wormhole作为实时流式处理平台,其设计思想最终是为流上处理数据而服务的。在本文中,我们主要从Wormhole的功能设计入手,重点介绍Wormhole所支持的几个基本功能。
Wormhole支持的功能很多,如下图所示,除了流式数据处理,Wormhole在管理和运维等方面也做的比较完善。下面我们从流式处理、平台管理、数据质量、数据安全以及运维监控五个维度来介绍Wormhole的具体功能。
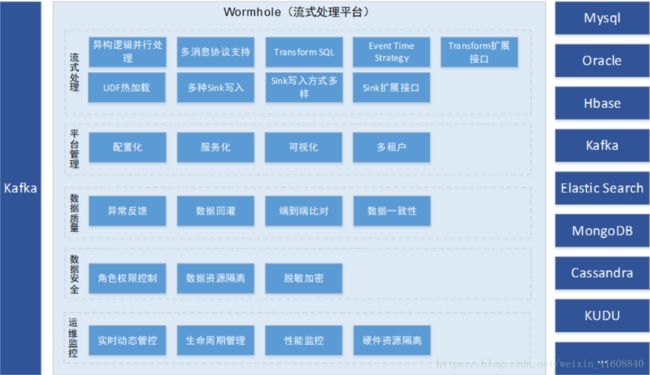
一、流式处理
Wormhole的核心是流式处理,并将流式处理抽象为Flow(流式处理逻辑管道,具体参见:#Wormhole# 流式处理平台设计思想)。Flow的引入,使得一个Spark Streaming上可以跑不同的处理逻辑,也就是多个Flow可以在一个Spark Streaming上同时执行而互不影响。这种异构逻辑的并行处理大大提高了资源利用率,也提高了流式处理的易用性。
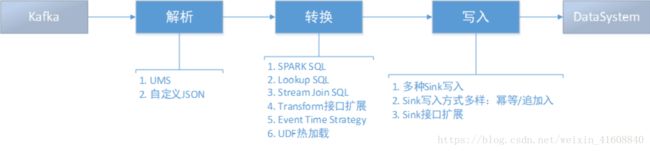
如上图所示,Flow从处理过程角度分为解析、转换、写入三个过程,具体如下:
1、解析
Flow支持多种消息协议,UMS和用户自定义JSON两种消息协议:
UMS
UMS是Flow支持的标准消息协议,在设计思想的文章中有介绍,这里不再介绍。(参见:#Wormhole# 流式处理平台设计思想)自定义JSON
开源后,为了适配用户已有系统的数据格式需求,Flow开始支持用户自定义JSON消息协议,使用也比较方便简单,只要在页面贴一个JSON消息例子,就会自动解析,然后通过点击配置即可完成自定义JSON的Schema的定义。
2、转换
这里的转换主要指对流上指定的Namespace的数据进行处理,处理方式包括Transform SQL(包含Spark SQL、Lookup SQL、Stream Join SQL)和接口扩展等,并且所有操作都可以有多项,即一个Flow中可以有多个Spark SQL,多个Lookup SQL,多个接口扩展等,具体如下:
- Spark SQL
利用Spark天然支持的SQL对数据做一些map操作,用户指需要在页面编写SQL即可实现实时对流上数据的Spark SQL处理。 - Lookup SQL
Lookup SQL是指将流上指定Namespace数据按某个或某几个字段join外部实体数据系统的数据,也就是将流上的数据加列处理,在页面编写SQL即可实现对流上数据的Lookup操作。目前支持多种Lookup SQL数据系统,包括Mysql、Oracle、Postgresql、SQLServer、Cassandra、Mongodb、Phoenix、ElasticSearch、Vertical、KUDU、Redis、Hbase,除了Redis和Hbase写法是类SQL写法之外,其他都支持SQL写法。下面举例介绍SQL的编写:
✔ 单字段关联:
select col1, col2, … from tableName where colA in namespace.X;
✔ 多字段关联:
select col1, col2, … from tableName where (colA,colB) in (namespace.X,namespace.Y);
✔ Redis
因Redis不是结构化存储方式,所以只能模仿SQL写法:
Redis的value是字符串时:select name:type as n1 from default(simple) joinby (key1+’_’+key2);
Redis的value是JSON串时:select name:int,name:string,name:long from default(json) joinby (key1+’_’+key2);
✔ HBase
考虑到HBase的性能,只支持根据Rowkey Lookup:
select h1:string as hx,h3:string from test_lookup(cf1) joinby mod(hash(sub(reverse(md5(id2)),6)),1000)/value(id2+’_’);
mod/hash/sub/reverse/md5都是考虑数据倾斜问题对rowkey的数据进行的处理;
✔ Stream Join SQL
Stream Join SQL是指将流上的两个Namespace的数据做Join操作,即将流上的数据Namespace A去Join流上的数据Namespace B,得到一个宽表。
✔ Transform扩展接口
虽然通过SQL已经可以解决大部分数据处理逻辑需求,但是为了满足一些个性化逻辑的应用,Flow定义了标准的扩展接口,用户实现接口即可编写自定义逻辑,并且可以与Transform SQL在一个Flow里同时使用。
✔ Event Time Strategy
基于事件时间,根据数据状态做的一些策略,目前支持在一段时间后,数据某些字段不符合条件时,可以做一些处理的选择。主要针对的场景是当Lookup时,如果关联的数据不存在(延迟等原因),那么就可以将未Lookup到的数据缓存一段时间,直到超时。
✔ UDF热加载
因Spark SQL支持UDF,Wormhole也支持了UDF,并且支持热加载,即在不停Spark Streaming的情况下,加载UDF的jar包和类,并使用UDF。
3、写入
写入是指将流上处理好的数据写入到指定的数据系统中。
- 多种Sink写入
目前支持主流的关系型数据库和NoSQL系统,包括Mysql、Oracle、HBase、Kafka、ElasticSearch、MongoDB、Cassandra、KUDU。 - Sink写入方式多样
可以根据用户配置确定数据的写入方式,目前支持追加和幂等写入。追加是指将所有数据insert到数据系统中,不区分数据状态;幂等是指Wormhole接收到的数据包括insert/update/delete状态,但能够保证与源数据一致状态的写入到数据系统中(如果Kafka中数据能保证顺序则支持强一致性,否则支持最终一致性)。 - Sink接口扩展
Wormhole虽然已经支持了主流的存储系统,但为了更好的兼容性,Flow定义了标准的写入接口,用户可以根据自己的需求实现写入逻辑。
二、平台管理
Wormhole提供了一个可视化操作的web系统—Rider,用来对各项配置和流程进行统一管理。同时也可以对外提供Restful方式操作Wormhole Stream和Wormhole Flow。并且通过Rider来管理和配置多租户等,具体功能可以参考我们的《Wormhole用户手册》。
https://edp963.github.io/wormhole/
三、数据质量
互联网公司中存在着大量数据,并且数据依然以很快的速度增长。其中,金融数据的质量异常重要,这一点与互联网其他数据有很大的不同。Wormhole在这方面做了很多工作。
1、数据一致性
Wormhole可以保证数据的最终一致性,这一点主要是通过幂等、数据备份和回灌等方式来保证。
2、异常反馈
当在计算过程中,如果出现异常,则Wormhole就会把相关的Flow、起止offset、event time等信息反馈给监控系统,然后可以手动对错误进行处理。
3、端到端比对
为了验证数据的一致性,实现了一个端到端实时比对的插件,在Flow进行中即可数据比对,并且不影响Flow执行。
4、数据回灌
Wormhole提供了数据备份的能力,将数据以文本形式写入到HDFS上。同时Wormhole也支持将备份的数据按一定条件(起止时间等)将数据回灌到对应的topic中,然后让Wormhole再消费一次。比如有异常反馈时,可以手动的将对应数据重新回灌到对应topic中,然后Wormhole可以幂等的将数据写入到各个数据系统,保证数据最终一致性。
四、数据安全
金融数据是非常敏感的,那么平台化就要保证数据的安全,在这方面,Wormhole通过权限控制、数据隔离和脱敏加密等方式保证了数据安全:
1、权限控制
Wormhole定义了三种类型用户,分别为管理员用户(admin)、普通用户(user)和第三方系统用户(app)。admin用户负责管理数据资源的连接地址,UDF jar包,其他用户等信息。user用户负责管理流式执行引擎和业务逻辑。app用户代表通过第三方系统与wormhole集成的用户,具有部分user用户的能力。通过权限的控制,实现了功能的约束,进而保证数据安全。
2、数据隔离
所有数据都是通过Namespace定义的,user用户可以使用哪些数据(Namespace)资源是由admin分配的,user用户登录到系统后,只能使用admin用户为其授权的数据(Namespace),也就实现了数据隔离。
3、脱敏加密
金融数据的一些信息需要进行加密才能对其他项目提供,那就可以在流上直接处理,通过UDF对某些字段进行加密、加盐等等,保证使用方看到的数据是脱敏的,进而保证敏感信息不外泄。
五、运维监控
1、实时动态管理
实时动态管理包括两方面,一方面是可以对Flow的相关配置进行实时管理,并且实时生效,这一点主要是使用了Zookeeper的能力;另一方面主要是针对Spark不支持的一些功能进行了扩展,包括不停Spark Streaming时,动态加载与注册UDF、和动态管理接入的Topic。
2、生命周期管理
Wormhole的Stream和Flow分别设计了一套有限状态机,也就是为两者分配了生命周期,保证操作的正确性。
3、性能监控
通过每个batch的每个Flow处理情况的Feedback信息,可以对每个batch的延迟情况、吞吐量、数据量等实时监控。
4、硬件资源隔离
主要从两个层次实现,一个是每个项目可以使用多少资源(CPU/内存)都是分配的,超过时无法启动新的Stream;另一个是每个Spark Streaming应用的资源是指定的,并且由Yarn分配,就是说Spark Streaming应用本身已经是资源隔离的。
流式处理支持异构逻辑的并行处理,提高了资源利用率;可视化操作的web系统统一管理各项配置和流程;数据质量通过“异常反馈”、“数据回灌”等方式得到了极大保障;数据安全也因“权限控制”、“数据隔离”、“脱敏加密”等方式得以实现。在介绍Wormhole的功能篇中,我们了解了Wormhole所支持的几个重要功能。那么Wormhole的设计细节具体是怎样来实现的呢?在Wormhole系列的第三篇文章中,我们会讲解其设计细节中的几个关键点,敬请大家期待~
如想了解更多,您还可以:
1.到Github浏览更多平台信息
DBus地址
https://github.com/BriData/DBus
Davinci地址
https://github.com/edp963/davinci
Wormhole地址
https://github.com/edp963/wormhole
Moonbox地址
https://github.com/edp963/moonbox
2.加入微信群,和技术大神们点对点交流
请先添加小助手:edpstack
(烦请告知小助手您的信息来源哦~如:“微信公众号”、“知乎专栏”、“CSDN”、“今日头条”等等~)
3.关注微信公众号“敏捷大数据”,获得第一手文章~