线性回归案例及两阶段模型的综合应用分析(重要)
线性回归的原理
应用于当Y值是连续变量的场合
公式
y=X*Beta
模型估计
– 最小二乘估计:
原理:残差(预测值-实际值)平方和最小
SST=SSR+SSE
R^2=回归平方和/总离差平方和
=1-残差平方和/总离差平方和

期望Y变量符合正态分布;X变量间不存在多重共线性;残差符合标准正态分布

-
了解数据
数据结构
Y变量定义
X变量类型
花费金额分布 -
分数据
INS:训练集(用来建模)
OOS:验证集(检验模型):验证过拟合或欠拟合,以及稳定性
OOT:测试集(有时间窗口的数据集)——与训练样本相互独立;主要验证模型稳定性及过拟合、欠拟合,但是考虑了不同时间段的时间窗 -
探索数据
分类型、数值型
X内部表现(分类型看不同类别的频率,数值型看它的均值)
X与Y关系(1. 看X与Y的商业定义;2. 看X与Y相关程度;)
缺失值(缺失值和缺失率)
4.数据分布
数值型(极端值大小,均值中位数)
数据分布特征
极端值

Profiling核心思想是什么?
线性回归里,由于Y是连续型变量,故Profiling与逻辑回归里的Profiling略有不同。首先,同样是先进行分组,之后求分组后的平均值,最后计算分组后的平均值与总体的平均值求比例
分类型(离散型)和数值型(连续型)区别和联系?
分类型是计算响应率与总体响应率的比例,而数值型是计算分组后的平均值与总体平均值的比例
逻辑回归和线性回归的Profiling结果是否一样?
结果是一样的
Profile图
Index=AVG Revenue/Overall AVG Revenue
-
清洗数据
缺失值处理
极端值处理
变量类型转化(分类型:哑变量;连续型变量:平方,开方或log运算)
创建新变量 -
查相关性
X与X之间关系(1. X与X字面意思;2. 统计学里相关性)
X与Y之间关系(1. X与Y字面意思;2. X与Y相关性低的也能剔除)
变量初步筛选 -
创建模型
初步筛选后的变量
step-wise
P值,标准化误差
X贡献率/VIF -
模型评估
X变量的商业意义
X与Y之间关系
P值/T检验
X贡献率
R^2
Lift图
验证集
测试集
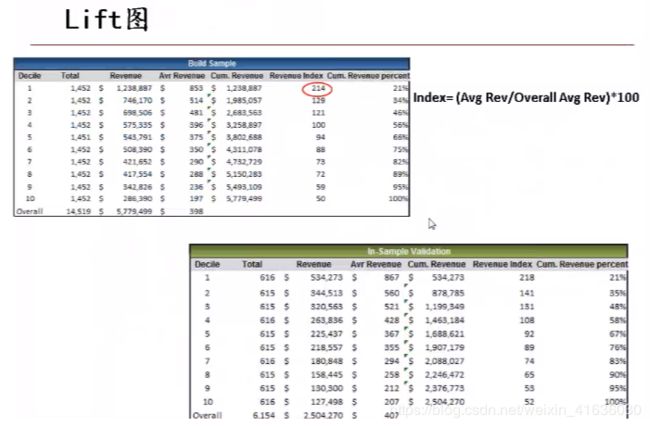

Lift图的用处是什么?
Lift图是用在模型建好后进行模型评估的
Lift图制作
Lift图是根据预测值(比如消费金额的多少从高到低)先分组,计算每组的购买率,之后把每组的购买率分别除以它的总购买率
index=(Avg Rev/Overall Avg Rev)*100
Lift图和Profile表虽然都是使用INDEX来进行评估,但是他们还是有一些区别
- Profile表往往发生在模型进行预测前,而LIFT图则是发生在模型产生预测值后进行模型评估时
- Profile表往往是根据单个自变量里不同类别所对应的实际Y值进行分类,比如说Y值如果是响应率,对于分类型自变量性别,就是划分为 男/女/未知 三类中每类Y值的实际个数除以总体的Y值实际个数乘以100求得不同类别的INDEX,如果最大的INDEX和最小的INDEX相差很大(120-80之间),那么可以选择将该自变量放进模型当中;而LIFT图则主要是对模型进行评估,查看模型预测后的值与实际值相比的提升度,它是发生在模型产生了结果之后,在有了预测Y值,之后根据Y值预测结果从高到低等样本划分区间,再计算在每个区间内的Y值实际个数除以总体Y值的实际个数乘以100计算每个区间的INDEX,可以看到它最终的LIFT图也应该是从高到低划分的
- Profile表里所划分的区间是根据单个自变量来的,而LIFT图里所划分的区间是根据Y预测值从高到低划分的,最终结果都是希望LIFT图最大值与最小值的差异越大,说明模型的分类效果越好
VIF(方差膨胀因子)
含义
解释变量之间存在多重共线性时的方差与不存在多重共线性时的方差之比
例子
如有一个方程Y=1.2+0.3X1+0.2X2+0.3*X3,看X1的VIF值,则以X1为因变量,X2和X3为自变量建立模型M,计算出此模型下的R2,则X1的VIF值为VIF=1/(1-R2)

两阶段模型的综合应用
对于高价值的目标客户挖掘项目,可以综合运用逻辑回归的响应预测模型和线性回归的购买金额预测模型
两阶段案例讲解
- 分别生成逻辑回归模型和线性回归模型,并读入数据
- 用建好的逻辑回归模型和线性回归模型分别进行预测打分
- 将预测出的响应率*花费金额,并分别验证其表现
- 制作响应率和花费金额的交叉表
两种应用
响应率和花费金额相乘
交叉表
两阶段案例讲解
第一步:随机取样本,采用通用建模流程,分别生成逻辑回归模型和线性回归模型
第二步:用建好的逻辑回归模型和线性回归模型分别进行预测打分(就是predict)
第三步:预测出响应率和花费金额,并分别验证其表现
第四步:将预测出的响应率和花费金额进行降序排列,分10组,制作响应率和花费金额交叉表
在用线性回归前,查看因变量Y是否服从正态分布,实际就是查看残差是否服从正态分布**
逻辑回归查看抽样的样本是否随机方法
查看各组响应率是否平均分布
线性回归查看抽样的样本是否随机方法
计算抽样样本的均值与总体均值比较
profile图
分组计算INDEX,目的是选取Index差异大的变量
连续型自变量在做profile图进行分组时,有两种分法,一种是按照每个区间有相等的行数划分,另一种是按照区间长度相等进行划分;由于缺失值无法进行划分,所以缺失值自成一类
通常的连续型自变量分组是按照缺失值一组,其他非缺失值进一步按照每个区间相等行数来进行划分分组
之后通过percentile来求取各分位点进行判断,用1%及99%分位点替代极值以及用均值或者中位数来处理缺失值
注意:这是针对一个变量的处理,当变量有很多时,需要通过循环来构建profile图
查看变量间的相关性
在做检验的时候,可以把p值比作熵,熵的含义是概率越小,信息越大;同样,p值的概率越小,那么它所代表的自变量信息越多,越能解释Y因变量的意义
lift表
对于线性回归在做lift表时,将数据代入模型进行预测,再将Y变量的预测值按照等行数分成10组,对应地有它们实际的Y值,之后再根据每组的平均值与总体平均值的比较计算INDEX。
两阶段模型案例
- 分别构建逻辑回归模型和线性回归模型
- 预测数据集需含有逻辑回归和线性回归的所有变量
- 将该数据集分别在逻辑回归模型和线性回归模型进行预测得到了逻辑回归预测结果与线性回归预测结果
- 处理方式:
#1. 按逻辑回归结果与线性回归结果乘积再进行分组,分完组后再计算实际响应人数及其index
#2. 构建交叉表,用逻辑回归结果分十份,再用线性回归结果分十份,再用逻辑回归和线性回归的两个分组构成行和列的交叉表,里面的数值表示人数的频率
注意:实际建模中一般放入8-12个变量
变量选取:
第一步:粗糙的根据缺失值过高或者根据解释变量与被解释变量不相关的变量(通过构建自变量与自变量以及自变量与因变量相关系数表)进行剔除
第二步:对于两个相关性过高的自变量,取其一,分别依次代入模型进行尝试
第三步:根据p值来选择,去除掉p值过高的变量
第四步:每一步都查看profile表,来根据profile表里分组后index差异很高的才选入模型当中
注意:之所以选择profile表里index差异过大的目的是为了区分变量所影响的群体,而如果组内群体差异很小,那么即使变量显著,放入模型中也无法起到区分的目的