教你怎么用Python爬取E站的本子_OverJerry
教你怎么用Python爬取E站的本子
- 申明
- 环境
- 实现
- 1.遍历目录,获得每个页面的url
- 2.获取标题
- 3.获取每张图片的真实地址并下载
- 4.让用户交互变得友好
- 完整代码
- 效果图
申明
1.本文只是Python爬虫技术的教学,绝不提供任何色情信息
2.本文方法都为原创!不存在抄袭!!!
3.类似的文章可以查看从零开始学习Python在e站上下载蕾姆的本子,也提供了类似的思路
环境
Python3,安装BeautifulSoup和lxml
e站默认是不能访问的,有多种方法访问,此处不提供思路
实现
1.遍历目录,获得每个页面的url
先打开网页
url:https://e-hentai.org/g/1141000/433ecfd306/
按F12进入开发者模式
选中图片,发现每张图片都在一个
标签中,且该标签的class都为“gdtm” 所以第一步是用python找出所有class为gdtm的div标签,代码如下:
import requests
import BeautifulSoup
def getWebsite(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Upgrade-Insecure-Requests':'1'}
#长长的请求头
site = requests.get(url,headers = headers)
content = site.text
#保存页面
soup = BeautifulSoup(content, 'lxml')
divs = soup.find_all(class_ = 'gdtm')
#找出class为‘gdtm’的标签
然后发现,真正的链接在href="https://e-hentai.org/s/aaa508bec5/1141000-3"中
就添加代码,在divs中遍历找出href
for div in divs:
picUrl = div.a.get('href')
#在和之间找到'href'的值,即链接
page = page+1
#计算总页数
2.获取标题
这就很简单了,这是标题的HTML
<h1 id="gn">[Mr. BlackCat] 八重樱 调教h1>
title = soup.h1.get_text()
#在标题中获取值
3.获取每张图片的真实地址并下载
先点开其中一张
图片的HTML
<img id="img" src="http://123.114.87.21:30000/h/bd7f11e11554fe33da71c00da6b6431308ae5038-126521-1280-1810-jpg/keystamp=1550140200-2260907238;fileindex=56805136;xres=1280/001.jpg" style="height: 1810px; width: 1280px; max-width: 1210px; max-height: 1711px;" onerror="this.null; nl('29182-430594')">
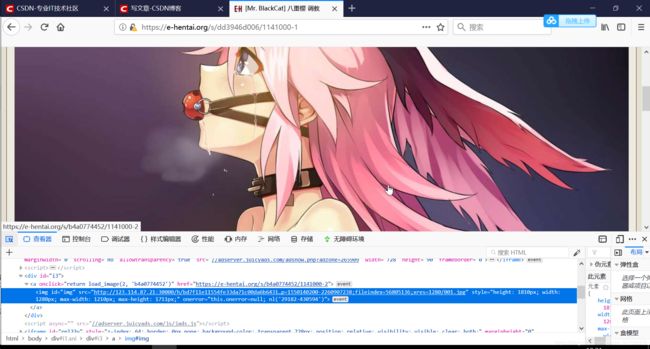 发现,图片的真实地址储存在src中。如此处就为
发现,图片的真实地址储存在src中。如此处就为
http://123.114.87.21:30000/h/bd7f11e11554fe33da71c00da6b6431308ae5038-126521-1280-1810-jpg/keystamp=1550140200-2260907238;fileindex=56805136;xres=1280/001.jpg
且可以直接打开。python思路就是找到页面上的标签,并读取里面src的值
def getPicUrl(url):
#识别页面图片url的方法,变量和之前的有所区分
site_2 = requests.get(url,headers = headers)
content_2 = site_2.text
soup_2 = BeautifulSoup(content_2, 'lxml')
#获得页面
imgs = soup_2.find_all(id="img")
#找到img标签
for img in imgs:
#遍历标签找到src的值并返回
picSrc=img['src']
return picSrc
以下代码实现下载
def saveFile(url,path):
response = requests.get(url,headers=headers)
with open(path, 'wb') as f:
f.write(response.content)
f.flush()
4.让用户交互变得友好
首先,我们要让程序把本子下在一个文件夹中,并对每张都进行命名
代码如下
def menu():
url = input('Please enter the url\n')
#输入url
if (url.find('https://e-hentai.org/g/') != -1):
#判断是不是e站url。因为find命令会字符串返回具体的位置,所以只要不为-1即可
print('--OK,getting information--')
try:
site = requests.get(url,headers = headers)
content = site.text
soup = BeautifulSoup(content, 'lxml')
divs = soup.find_all(class_ = 'gdtm')
title = str(soup.h1.get_text())
#获取标题和页数
page = 0
for div in divs:
page = page+1
except:
print('Wrong!Please try again!!!')
menu()
else:
print('The comic name is '+title+',it has '+str(page)+' page,start downloading!!!')
if os.path.exists('D:/comic/'+title):
#默认保存在D:/comic/"本子的名字"的文件夹下,判断是否已经存在该目录
getWebsite(url)
#刚才编写的获取每页url的方法,将返回值直接带入getPicUrl(),getPicUrl()又将返回值传给saveFile()下载
else:
os.mkdir('D:/comic/'+title)
#创建目录
getWebsite(url)
#同上
else:
print('Oh,it is not an e-hentai comic url,please enter again\n')
menu()
完整代码
import requests
import os
import multiprocessing
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Upgrade-Insecure-Requests':'1'}
def saveFile(url,path):
response = requests.get(url,headers=headers)
with open(path, 'wb') as f:
f.write(response.content)
f.flush()
def getWebsite(url):
site = requests.get(url,headers = headers)
content = site.text
soup = BeautifulSoup(content, 'lxml')
divs = soup.find_all(class_ = 'gdtm')
title = soup.h1.get_text()
page = 0
i = 0
for div in divs:
picUrl = div.a.get('href')
page = page+1
print('Saving file '+title+str(page)+'.jpg')
try:
saveFile(getPicUrl(picUrl),'D:/comic/'+title+'/'+title+str(page)+'.jpg')
except:
print('Can not download '+title+str(page)+'.jpg')
else:
print('Succeed')
i = i+1
print('Finished downloading '+str(page)+' files,'+str(i)+' of them are successful')
menu()
def getPicUrl(url):
site_2 = requests.get(url,headers = headers)
content_2 = site_2.text
soup_2 = BeautifulSoup(content_2, 'lxml')
imgs = soup_2.find_all(id="img")
for img in imgs:
picSrc=img['src']
return picSrc
def menu():
url = input('Please enter the url\n')
if (url.find('https://e-hentai.org/g/') != -1):
print('--OK,getting information--')
try:
site = requests.get(url,headers = headers)
content = site.text
soup = BeautifulSoup(content, 'lxml')
divs = soup.find_all(class_ = 'gdtm')
title = str(soup.h1.get_text())
page = 0
for div in divs:
page = page+1
except:
print('Wrong!Please try again!!!')
menu()
else:
print('The comic name is '+title+',it has '+str(page)+' page,start downloading!!!')
if os.path.exists('D:/comic/'+title):
getWebsite(url)
else:
os.mkdir('D:/comic/'+title)
getWebsite(url)
else:
print('Oh,it is not an e-hentai comic url,please enter again\n')
menu()
menu()
效果图
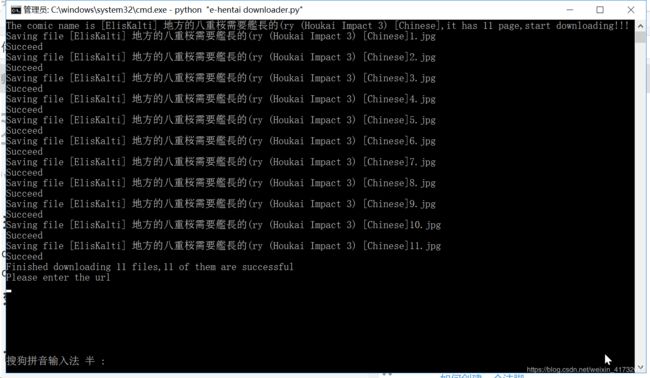
 尽情下载吧!下载速度还是有些偏慢,毕竟服务器在国外
尽情下载吧!下载速度还是有些偏慢,毕竟服务器在国外
不敢多说,已经被河蟹了两次了
技术上的问题欢迎找我,其他的一律屏蔽!!!
The End~~~