Recovering 6D Object Pose from RGB Indoor Image 阅读笔记
基于多任务损失的二级检测网络的rgb室内图像的6d[2]目标姿态恢复
姿态估计问题就是确定某一三维目标物体的方位指向问题。
摘要:本文提出了一种基于两级标注框识别主干结构的端到端6D类位姿估计方法。我们的网络直接输出6D姿态,不需要多个阶段或额外的后处理,如Perspective-n-Point[1](PnP)。这个两级的CNN结构和损失函数使得多任务联合训练有效。用全卷积层代替全连接层,提高了姿态估计精度。此外,我们使用我们的网络将姿势估计问题转化为分类和回归任务,这些任务称为Pose-cls和Pose-reg。使用SUN RGB-D数据集[3]。
- introduction
传统的6d目标姿态可以用基于三维模型与图像的局部特征匹配PnP方法。但不适合纹理不足的对象。模板匹配或者密集特征学习方法可以纹理不足问题,但对于光照和遮挡比较敏感。密集特征学习方法的特征提取和姿态改良耗时长。
很多基于cnn的方法都是例子级别而不是类级别。对于类别级别的姿态估计,解决类别内部外观的方法必须学习类别中实例的变化。有些类级别方法要么一张图象只有一个目标或者只有一个离散的姿态空间。一种早期的类别级姿态估计方法扩展了可变形零件模型(DPM),以明确地模拟部分外观及其姿态。这被称为DPM-VOC+VP。基于CNN的方法使这种关系将通过层次卷积结构隐式捕获。最近,基于CNN的方法已经被证明优于基于DPM的姿势估计方法。此外,DPM也可以被视为CNN的特定实例。我们的方法对每个图像的多个对象和每个类别的多个实例进行操作。
我们的目标是同时从一张室内图像检测和恢复6d姿态。在本文中,我们提出了一个基于两阶段检测的CNN框架由(resnet)[4]、(rpn)[5]和全卷积网络(FCN)组成。
姿态估计可以视为回归问题也可以视为分类问题,我们提供了两种形式(分类和回归)。我们和Scenemap[6]比较效果,Scenemap提供了基于语义分割体系的2d目标位置。我们展示了一种联合目标检测和姿态估计的端到端体系,不同的训练分支可以共享特征图。
我们的cnn处理三个任务(分类、标注框估计和目标姿态估计),需要一个有效的方法代表6d姿态和有效的损失函数设计方法。Pose-cls用三维向量表示姿态:第一个元素代表x-y平面内旋转角因为室内物体通常对准了重力的方向。后两个元素代表了平移的x,y分量。Pose-reg我们用二维向量表示姿态,这里第一个角度和cls相同,第二个元素代表了平移的z分量。使用z分量,我们可以使用指定的内置摄像机校准矩阵的3D-2D投影公式恢复完整的平移。通过简化旋转和平移分量,我们有效调和了损失函数的超参数。
我们提出并讨论了两种通过将多任务损失转化为分类和回归形式来实现类别级姿态估计的替代方法。他们俩同时从一个RGB图像检测一个物体并预测它的6D姿态,而不需要多个阶段或细化。我们在室内图像数据集上评估了这两种姿态估计方法。
我们通过在端到端结构中中添加resnet和fcn,将边界框识别网络的使用扩展到多个任务,包括检测和姿势估计。这个应用带有FCN和Resnet可以减小参数的数量的同时提高精度。 - Related Works
我们大概回顾一下6d姿态估计的方法,大致可以分为基于关键点的(keypoint-based),基于模板的(template-based),基于特征学习(feature learning)的和基于cnn的。
Keypoint-based methods:
稀疏的关键点可以从图像的ROI中提取出来并且和3d模型的相关点进行匹配,来进行6d姿态复原。对遮挡和杂波场景鲁棒。基于关键点的方法的局限性在于其固有的目标对象稀疏表示,即关键点的质量直接影响姿态估计的精度。因此,这些方法需要在对象上使用丰富的纹理来计算稀疏的关键点。
Template-based methods:
近年来很多研究基于纹理不足的对象。对于纹理不足的对象,最传统的方法是使用对象模板。尽管基于模板的方法能够有效地检测纹理较少的对象,但它们在姿势变化方面存在一定的缺陷。要处理姿势变化,需要大量模板,这是非常耗时的。此外,基于模板的方法不能有效地处理照明或遮挡,因为光线不足和遮挡会降低模板的相似性得分。
Feature learning methods:
许多研究已经超越了通过学习来使用稀疏关键点,而是回归每个像素的密集对象坐标,以建立二维-三维对应关系,从而从密集对应关系中恢复目标对象的姿态。此外,类似的研究通常遵循一条耗时的多阶段结构。从二维-三维对应关系中恢复6D姿态后,通常需要进一步细化以获得最终姿态。然而,对于对称对象,对象坐标回归并不能有效地进行。
CNN-based methods:
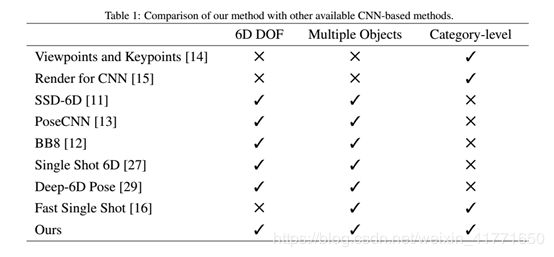
Viewpoints and Keypoints [7] and Render for CNN [8] 将三维姿态估计转化为分类任务,特别是通过离散姿态空间。受这一理念的启发,SSD-6D[9]将SSD检测框架扩展到3D旋转估计。它将三维旋转空间分解为离散的视点和平面内旋转。PoseCNN[10]联合分割对象并估计旋转以及分割对象与相机之间的距离。但是,要定位对象,posecnn语义分割需要一个fcn。此外,POSECNN不能处理包含对象的多个实例的图像输入。
另一类基于CNN的方法通过从更局部的角度指定一组固定关键点的位置来描述目标对象的姿势。BB8提出了一种用于目标姿态估计任务的耗时多阶段结构。BB8首先使用CNN定位对象,然后使用另一个CNN预测对象周围关键点(即三维边界框的角)的二维投影。使用附加的PNP算法恢复6D姿态。BB8不是端到端因为它结合了多个分离的CNN。最近的一项研究采用了类似的方法。作者扩展了一个Yolo对象检测网络来预测不同对象周围的三维边界框角的二维投影。在另一项研究中,研究人员使用额外的姿势输出,根据SSD网络预测姿势。然而,他们的方法只处理具有离散视图空间的三维旋转分量。
相比于上述方法,Deep-6DPose结合了检测、分割和恢复6d姿态。Deep-6DPose [11]是一个端到端的深度学习结构,它将姿态参数解耦为平移和旋转,从而通过李代数表示来回归旋转。该方法预测了Z分量,需要进行后处理才能恢复完整的平移。然而,该方法的CNN体系结构由六个完全连接的层组成,这些层需要过多的内存占用。此外,多任务损失函数有四个项,必须谨慎平衡。Scenemap自顶向下的视图以图像作为输入来预测粗糙的场景。使用fcn估计位置和目标类别,然而它不处理旋转估计并且难以处理含有多个实例对象输入的图像。DeepContext为scenemap提供了一个3D扩展;但是,它关注场景模板中的整体场景理解,需要一个根据深度图像计算的三维点云。
我们的方法对多个目标进行类别级检测和姿态估计。输出姿态有六个自由度。我们的CNN架构是两个阶段而不是单次的。两级CNN比单点CNN更精确,尤其是在小型对象和多个对象上。这是因为在单次目标检测中,确定单元的大小和位于同一单元中的对象的数量是一个挑战。此外,多个对象导致遮挡;这会影响这些基于对象的三维边界框角与其二维投影之间的对应关系的单次检测方法的准确性,当对应关系由于遮挡退化PnP可能效果更差。另外,我们的方法不需要多级或者多重假设校验就可以预测目标6d姿态。某些单次6D姿势方法必须改进或必须使用PNP来恢复对象的姿势。
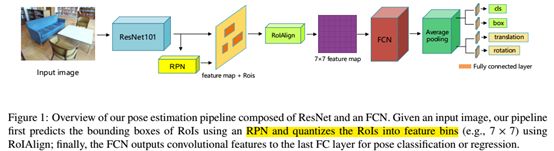
3.Method
3.1 overview
目标姿态预测更有挑战性因为为了估计目标姿态,目标必须正确检测。因此,我们的贡献是一种架构,它可以在不需要后处理(如基于边缘轮廓的精化)的情况下快速、准确地预测一次拍摄的姿态。为了完成我们的任务,我们将两级检测主干扩展为联合检测和姿态估计网络。
3.2 learning in a pose estimation pipeline
(1)端到端架构:
我们的方法(如图1所示)使用几个CNN结构来解决我们的三个子任务,即同时对对象进行类、姿势和边界框估计[14]。给定一个RGB图像,我们的架构首先使用一个RPN提取提议的区域;然后,它回归在x-y平面内旋转角Θ和平移的z分量。为了提高准确性并且减少参数的规模,我们用ResNet-101代替VGG-16并且采用了全卷积层代替全连接层。得益于显著提升的深度,ResNet-101可以提高准确率并且更快收敛。理论上,全连接层也可以看作是覆盖整个输入区域的内核的卷积。理论上,完全连接的层也可以看作是覆盖整个输入区域的内核的卷积。一个完全卷积表示需要较少的参数,不太容易被过度拟合,被Mask RCNN[12]使用和验证。
(2)分类和回归:
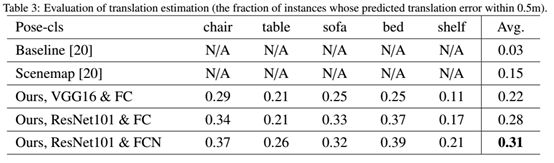
我们的架构可以通过修改损失函数将问题转为分类或者回归任务。如表3阐述,我们比较了我们的pose-cls和现有的方法,比如Scenemap。我们还测试了我们的pose-reg,并对resnet和fcn进行了消融[20]研究。此外,我们比较了pose-CLS和pose-Reg;这方面的更多细节在后面的章节中提供。关键的观察是基于回归的姿态估计比基于分类的姿态估计更准确。
(3):多任务损失
为了共同训练一个多任务网络,我们定义了我们的训练目标,它由三个损失的加权和组成:类别损失Lcls,标注框损失Lbox和姿势损失Lpose。定义如下:
![]()
Lcls(p; u) = -log(pu)是两类间的log损失。对于每一个ROI,我们用Lcls产生一个离散的概率分布,c+1个类别,p=(p0,…,pc)。对于标注框回归,我们用损失


这里是一个鲁棒的L1损失[13],比L2损失不易受极端值影响。每个训练的ROI都标注有真实值u和标注框v。Lbox是在真实的边界框和预测边界框上标注的,当u≥1时, [u≥1]输出1,否则输出0。背景类被标记为u=0。第三个损失Lpose有两个选项:Lpose-reg(平滑的L1回归损失)或者Lpose-cls(softmax损失)。超参数α_1平衡不同损失的比重。归一化标注框为零均值和单位方差。因此分类损失和标注框损失是同分布的(why)。Lbox和Lpose只对正样本有效,背景这两项为0。对于pose-reg,姿态分支为每个ROI输出两个数字,代表平移的Z分量和沿Z轴的旋转角度θ(如上所述,室内对象通常与重力方向或Z轴对齐)。另外,姿态回归损失定义如下:

对于Pose-cls,输出三个值,x-y平面旋转角Θ和平移的x,y分量。另外损失函数如下:

pθ是旋转角类别的softmax输出,px,py是平移分量类别的softmax输出。ROIAlign[15]
3.3 Training and inference
(1)Training:
基于PyTorch,RPN使用三种不同面积比例,9种anchor。这种设计使得网络能够检测小目标。
上面等式(1)(4)的α_1,α_2,α_3设置为1,2,1。如表811所示,我们观察到大于2或者小于1的值都会导致不好的表现。我们使用动量为0.9,权重衰减为0.0001(L2正则化)的随机梯度下降训练我们的网络。用GTX080Ti的GPU迭代150000次。每个batch有256张图片。前50000次的学习率设置为0.001,然后,在剩余的迭代中,学习率降低了10%。前2000个ROI(正负比例1:3)按顺序送入网络计算多任务损失。一个ROI被视为正样本如果它的IOU至少为0.5,否则为负样本。Lpose只由正ROI计算。
测试阶段,我们对输入图片进行一次前向传播。我们使用RPN产生ROI并采取非极大值抑制[16]于cls分数(即0.7)和iou门限(即0.5)。
(2):From a 2D regressed pose to a complete 6d pose:
给定预测的θ,我们可以恢复相应的旋转矩阵,因为旋转轴与Z轴对齐。为了恢复完整的转换,我们依赖于预测的Z分量(即∆Z)并恢复X和Y分量(即∆X和∆Y)。假设针孔相机,我们可以根据以下投影方程恢复∆x和∆y:
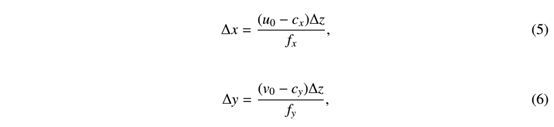
其中,fx和fy表示相机的焦距,(cx,cy)T(转置)是主点[17],u0,v0是ROI的边界框中心。
4.Experiments and Analysis
4.1.Metrics
对于旋转,我们使用Xiang等人提出的平均视点精度(AVP)度量[18]来评估我们的结果。对于平移,我们展示了所有误差的中位数(mederr)。
4.2.Datasets
我们直接在Sun RGB-D数据集上训练我们的网络,该数据集由10335个带有三维对象边界框注释的RGB-D图像组成。每幅图像中平均有14.2个物体。总共有47个场景类别和大约800个对象类别,如图2所示。这些RGB-D图像主要是从家庭环境中捕捉到的。我们从睡眠区、办公室和休息区手动选择图像,因为它们代表了通常在室内观察到的图像。在SUN RGB-D中提供的图像数量相对较大的环境。我们将重点放在在五个常见的对象类别上,即椅子、桌子、沙发、床和架子,并选择8363个包含来自数据集的这些物体的RGB-D图像。我们将这些图像分为一个训练集(90%)和一个测试集(10%),此外,我们在训练集上应用了水平翻转的平均预处理和数据增强。在下面的实验中,我们评估了端到端的测试集姿态估计体系结构。注意我们只使用RGB通道作为输入,深度通道(每个像素比特数)仅用于3D注释。

4.3.Results
在本节中,我们提供了两个主要任务的实验结果:二维目标检测和三维姿态估计。我们验证了我们的网络在多个对象和每个类别的多个实例上有效地执行。
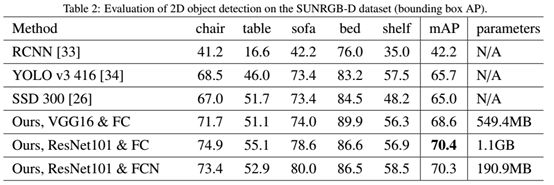
目标检测表现:结果如表2所示。我们的方法基于两级的检测架构并且比一级的方法比如YOLO和SSD表现好。我们观察到,resnet提高了检测精度,一个fcn需要的参数比fc层少。我们在图3中可视化了目标检测结果。

Pose-cls架构表现:我们定量比较了我们的方法与基于单帧深度估计baseline方法和scenemap。我们的pose-cls架构以类似scenemap的方式输出对象的二维位置和方向,scenemap描述对象的位置。为了评估我们的pose-cls架构,我们将二维平移空间离散为分辨率为0.5平方米、尺寸为[-2:5m;2:5m]×[-2:5m;2:5m]的二维网格,并将此任务定义为100类分类问题。此外,我们将360°旋转范围划分为36个块,并将此任务转化为分类问题(图4)。我们对pose-cls采用了一种类别不可知论的方式,它在所有对象类别中共享pose的输出。使用N_c类物体产生N_θ姿态。类别不可知的方式可以加速计算并且相比指定类别的方法不容易过拟合。根据表3,我们的pose-cls网络为平移提供了更准确的结果。更多关于baseline和scenemap的细节见[19]。为了证明旋转准确性,我们在表4提供了我们的结果。因为baseline和scenemap不能处理物体的旋转,我们不与他们比较。我们与单次姿态估计SSD比较,这证明了我们的模型表现更好。在图5中,我们提供了我们的方法在数据集上的示例结果。除了正确样例,我们同样报告了离正确值一个单元偏差的表现(即,一个单元格偏差仍视为正确)请注意,虽然我们的方法并不总是确定完美的位置,但它对于推断整体场景结构仍然有效。
我们对resnet和fcn的影响进行了消融研究,结果见表3和表4。我们观察到resnet和fcn提高了精确度。我们假设这是因为resnet很深,并且解决了消失梯度问题,并且因为fcn参数较少,需要的训练数据较少。

Pose-reg架构表现:在pose-reg中,我们为每个类别使用单独的输出层,即nc×nθ输出,因为特定于类别的方法对回归更有效,这也是基于掩模R-CNN验证的。平移复原的MedErr见表5. 我们的pose-reg网络比deepcontext[21]在平移估计方面有10%的优势。我们还对DeepContext进行了旋转比较,尽管这种比较存在偏差。请注意,DeepContext使用三维点云和预定义的三维场景模板进行旋转估计,而我们的方法仅使用二维RGB信息。表6说明我们的网络性能高于最先进的方法。

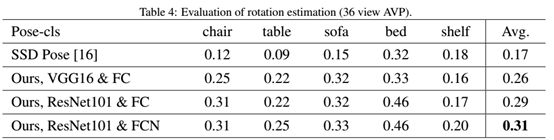
我们分别研究了pose-reg中核心部件的作用。值得注意的是,使用vgg进行的姿势估计比使用resnet进行的准确率要高,如表6所示。我们假设这是因为带有fc的resnet有更多的参数,需要更多的数据进行训练。从表5和表6可以看出,fcn对于获得更高精度水平很重要。我们认为这是因为FCN减小了参数的大小,比全连接层更不容易过度拟合。
比较:如表7所示,pose-reg显著优于pose-cls,表现超出约为6%。表7说明了POSE CLS和POSE Reg对桌子的精确度均低于其他类别;这主要是因为桌子可能由于所涉及的对称性而具有不明确的姿势。因此,处理旋转对称物体的姿态估计方法具有挑战性。
超参数评估:在表8~11中,我们在五种物体类别上比较了不同的α_1,α_2,α_3,表8~11说明当α1、α2和α3小于1或大于2时,我们的结果受到影响。当超参数值达到10时,我们观察到方程(1)的梯度发生了爆炸。
5.Conclusion and Discussion
在这项研究中,我们提出了一种端到端可训练的方法来共同检测,最重要的是,从一个RGB图像中恢复多个对象实例的6D姿态。我们的主干是一个两级检测管道,用resnet替换vgg,用fcn替换fc。Resnet通过提供指数数量的网络的隐式集成来提高精度。此外,FCN还减小了参数的大小,并且对过拟合具有鲁棒性。我们端到端的架构提供类别级别的姿势估计,并与其他最先进的方法进行比较有优越性。我们还比较了pose-CLS和pose-Reg并观察到回归管道比分类管道提供更准确的结果。这可能是因为有效的分类结果需要在离散的姿势空间上进行适当的采样。此外,回归网络(即pose-reg)对旋转和平移的标量进行回归,而不进行任何采样。一个可能的未来研究将是改善我们的管道,处理对称和高度遮挡的物体。
处理具有对称轴的物体的问题仍然是开放的,并已由[22]部分解决。一些基于CNN的旋转不变目标检测方法有可能解决这个问题。此外,高遮挡物体检测可能可以通过使用自动编码器和对抗性学习解决。

[1]:PnP问题是求解3D-2D点对运动的方法。他描述了当知道n个三维空间点坐标及其二维投影位置时,如何估计相机的位姿。我们可以想象,在一幅图像中,最少只要知道三个点的空间坐标即3D坐标,就可以用于估计相机的运动以及相机的姿态。(详细方法以后再看)
[2]:6d,rotation(roll翻滚角,pitch俯仰角,yaw偏航角) 手机定义的坐标系统:X轴是水平且指向右边,Y轴是垂直且指向前方,Z轴指向屏幕的正面正上方。
当手机左右摇摆时(绕 y 轴旋转),得到变化的 滚转角Φ(roll),范围为 (-90 to 90)
当手机前后摇摆时(绕 x 轴旋转),得到变化的 俯仰角θ(pitch),范围为 (-180 to 180)
当手机横屏转换成竖屏或竖屏转换成横屏时(绕 z 轴旋转),即得到变化的 偏航角ψ(yaw)。

3D translation(x,y,z)
[3]: 虽然rgb-d传感器已经为一些视觉任务(如3D重建)带来了重大突破,但我们还没有实现类似的高层次场景理解的性能跳跃。可能其中一个主要原因是缺乏一个合理尺寸的基准,其中包括用于训练的3D注释和用于评估的3D度量。在本文中,我们提出了一个RGB-D基准套件,以促进所有主要场景理解任务的最新水平。我们的数据集由四个不同的传感器捕获,包含10000个rgb-d图像,其比例与帕斯卡VOC相似。整个数据集都有密集的注释,包括146617个二维多边形和58657个具有精确对象方向的三维边界框,以及三维房间布局和场景类别。这个数据集使我们能够为场景理解任务训练数据密集型算法,使用直接而有意义的3D度量评估它们,避免和小的测试集过拟合,并研究交叉传感器偏差。
[4]:ResNet
https://blog.csdn.net/lanran2/article/details/79057994
[5]:RPN
https://blog.csdn.net/hunterlew/article/details/71075925
https://blog.csdn.net/weixin_41771650/article/details/85952259
[6]: Scenemap
M. Hueting, V. Patraucean, M. Ovsjanikov, N. J. Mitra, Scene structure inference through scene map estimation,VMV.
[7]: Viewpoints and Keypoints
S. Tulsiani, J. Malik, Viewpoints and keypoints, in: CVPR, 2015.
[8]: Render for CNN
H. Su, C. R. Qi, Y. Li, L. J. Guibas, Render for cnn: View-point estimation in images using cnns trained with rendered 3d model views, in: ICCV, 2015.
[9]: SSD-6D
W. Kehl, F. Manhardt, F. Tombari, S. Ilic, N. Navab, Ssd-6d: making rgb-based 3d detection and 6d pose estimation great again, in: ICCV, 2017.
[10]: PoseCNN
Y. Xiang, T. Schmidt, V. Narayanan, D. Fox, Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes, in: RSS, 2018.
[11]: T. Do, M. Cai, T. Pham, I. D. Reid, Deep-6dpose: Recovering 6d object pose from a single RGB image, in: arXiv,arXiv:1802.10367, 2018.
[12]:Mask RCNN
K. He, G. Gkioxari, P. D. r, R. B. Girshick, Mask r-cnn, in: ICCV, 2017.
[13]: L1,L2范数
正则化惩罚(regularization penalty)
L2正则化就是在代价函数后面再加上一个正则化项:

C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整。到目前为止,我们只是解释了L2正则化项有让w“变小”的效果,但是还没解释为什么w“变小”可以防止overfitting?一个所谓“显而易见”的解释就是:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
在原始的代价函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n

[14]:boundingbox regression:
注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这个也是G-CNN: an Iterative Grid Based Object Detector多次迭代实现目标准确定位的关键。
https://blog.csdn.net/zijin0802034/article/details/77685438/
[15]:ROIAlign
https://baijiahao.baidu.com/s?id=1616632836625777924&wfr=spider&for=pc
https://blog.csdn.net/u011918382/article/details/79455407
https://blog.csdn.net/ccblogger/article/details/72918354 (双线性插值和最近邻插值)
[16]:NMS
https://blog.csdn.net/HappyRocking/article/details/79970627
[17]:焦点和主点

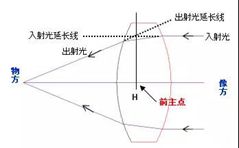
镜片入射光延长线与从镜片折射的出射光的反向延长线交点,对光轴做垂线时与光轴的交点,即被称为主点(Principle Point),简单来说就是主平面与光轴的交点H和H’,H称为前主点,H’为后主点。前主点H --从像方射入光线而获得的主点。后主点H’–从物方射入光线而获得的主点。
[18]:AVP
Y. Xiang, R. Mottaghi, S. Savarese, Beyond pascal: A benchmark for 3d object detection in the wild, in: IEEE Winter Conference on Applications of Computer Vision (WACV), 2014.
[19]:baseline and scenemap
M. Hueting, V. Patraucean, M. Ovsjanikov, N. J. Mitra, Scene structure inference through scene map estimation,VMV
[20]:消融研究
模型简化测试。 看看取消掉一些模块后性能有没有影响。 根据奥卡姆剃刀法则,简单和复杂的方法能达到一样的效果,那么简单的方法更可靠。 实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。 比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study
[21]:DeepContext
Y. Zhang, M. Bai, P. Kohli, S. Izadi, J. Xiao, Deepcontext: Context-encoding neural pathways for 3d holistic scene understanding, in: ICCV, 2017.
[22]:处理遮挡物体:
M. Rad, V. Lepetit, Bb8: A scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth, in: ICCV, 2017.