爬虫第四课:猫眼电影
- 首先要导入我们需要使用的库
导入库是因为库里有我们需要用的函数,这些函数能帮我们实现某些功能。
![]()
使用 import 导入我们需要用的库,写法如图1所示,由图1可以看出导入了requests库和re库,第一个库是用来向服务器发送请求获得响应的,第二个库是正则表达式用来提取数据的。
- 你要提取什么数据?
假如我们要获得猫眼电影榜单top100的电影信息,网址为https://maoyan.com/board/4?,那么我们首先要到这个网页中大体浏览一下。

可以看到每一页有十个电影,一共有10页,也就是说我们想要的信息在十个网页上,那么我们就需要这十个网页的url。我们先看如何提取一个网页的信息,最后在讲如何提取这十个网页的数据。
了解大体情况后,就打开网页源代码(右击选择查看网页源代码),看一看我们需要的信息(比如电影的名字)在源代码页的哪个位置。

通过control+F会出现一个搜索框,如图3所示,在搜索框内输入你想要的内容,输入就可以快速看到信息的位置。
3.发送请求,获得响应。
我们已经有url,可以通过浏览器向服务器发送请求了。但实际是我们并不是通过浏览器向服务器发送请求的,而是通过爬虫。如果服务器识别出来请求时爬虫发出来的,那么我们就会被屏蔽掉,获得不了任何响应。所以我们要把我们写的爬虫包装成浏览器。
那我们如何在向服务器发送请求的时候,不被识别为爬虫。要想不被识别为爬虫,那就需要先伪装成浏览器,这需要在发送请求的时候加上headers参数。
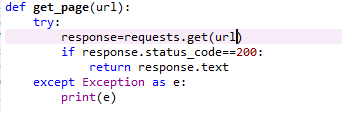
上图是一个没有伪装成浏览器样子的函数。

上图的内容就是将爬虫伪装成浏览器,并向服务器发送请求。下面解释每一行代码:
第一行是向服务器发送请求并获得相应的函数,将该函数定义为get_page(url),这个函数需要的参数就是url。Try和except是防止发生意外程序中断,保证程序的持续运行。Headers就是我们伪装成浏览器所需要的参数,是字典形式,每次爬虫都需要取所爬取的网站去复制一下,获得方法:打开检查页,点击network,按f5刷新,此时左侧会更新出很多网页,然后谁便点击一个,让后点击headers,将页面往下拉,找到request headers,复制里面的user-agent。如图6所示

如果请求成功,那么将返回网页源代码的内容。
这两行的意思是,如果上面代码运行失败,那么就将失败的原因打印出来。
所以向服务器发送请求并获取源代码的代码如下:
url='https://maoyan.com/board/4?'
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
def get_page(url):
try:
response=requests.get(url,headers=headers)
response.raise_for_status()
response.encoding=response.apparent_encoding
return response.text #这就是我们写这个函数所需要的结果,网页原代码。
except Exception as e:
print(e)
- 提取数据
下面是定义一个提取数据的函数,这个函数如下图所示,它所需要的函数就是上一个函数返回的结果,网页源代码。
def get_info(page):
items=re.findall('board-index .*?>(\d+).*?class="name"><.*?>(.*?).*?.*?'+
'主演:(.*?) .*?
.*?(.*?)
.*?'+
'(.*?)(\d+)
',page,re.S)
for item in items:
data={}
data['rank']=item[0]
data['title']=item[1]
actors=re.sub('\n','',item[2])
data['actors']=actors
data['date']=item[3]
data['score']=str(item[4])+str(item[5])
yield data
将正则表达式提取出来的数据赋值给items,items是个列表,列表里的每个元素是个元组。每个元组里都包含各个电影的名称、演员、上映时间等信息。一次性写这么长的正则表达式比较困难,容易失败,且找不到原因。可以先把电影的名称提取出来,如果成功了,再继续加长正则表达式,提取出每个电影的其他信息,一步一步,就可以吧所有电影的信息提来了。然后在把数据写成字典的形式,方便后面保存到Excel。
先提取电影的排名信息
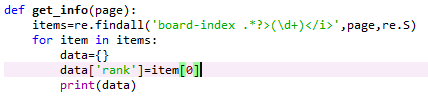
提取结果

在加长正则表达式,提取电影名称信息

提取结果

就如上图所示,一步一步完善正则表达式,直到提取出所有的结果。
这些信息不再一页上,而一共在十页上。所以需要发现每一页的规律,然后构造出来每一页的url。
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
。。。
第十页:https://maoyan.com/board/4?offset=90’
看到规律了没?
第n页网址:https://maoyan.com/board/4?offset=(n-1)*10
所以就用代码构造出所有的url
urls=['https://maoyan.com/board/4?offset={}'.format(i*10) for i in range(10)]
- 主程序
主程序就是将所有的函数调用起来,将结果保存到一个列表里。
DATA=[]
for url in urls:
page=get_page(url)
datas=get_info(page)
for data in datas:
DATA.append(data) #将所有的数据添加到DATA里
运行结果:
保存到Excel
保存到Excel需要调用xlwt库,具体代码如下:
首先需要建立一个空列表,将所有的数据添加到里面去。在之前的提取数据那个函数的时候,将print(data),改写成yield data。
将所有的数据添加到一个列表之后就可以保存数据了,具体代码如下:
import xlwt
f=xlwt.Workbook(encoding='utf-8')
sheet01=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet01.write(0,0,'rank') #第一行第一列
sheet01.write(0,1,'title')
sheet01.write(0,2,'actors')
sheet01.write(0,3,'date')
sheet01.write(0,4,'score')
#写内容
for i in range(len(DATA)):
sheet01.write(i+1,0,DATA[i]['rank'])
sheet01.write(i+1,1,DATA[i]['title'])
sheet01.write(i+1,2,DATA[i]['actors'])
sheet01.write(i+1,3,DATA[i]['date'])
sheet01.write(i+1,4,DATA[i]['score'])
print('p',end='')
f.save('E:\\猫眼电影.xls')
具体每行代码就不需要解释了,根据自己的数据的属性做响应的调整。
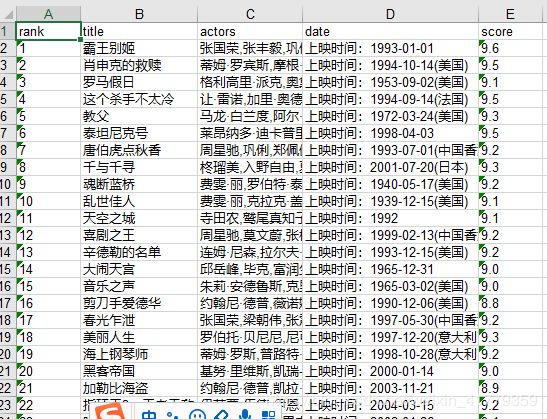
保存到Excel如下图所示:
所有代码:
import requests
import re
import xlwt
url='https://maoyan.com/board/4?'
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
def get_page(url):
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
else:
print('获取网页失败')
except Exception as e:
print(e)
def get_info(page):
items=re.findall('board-index .*?>(\d+).*?class="name"><.*?>(.*?).*?.*?'+
'主演:(.*?) .*?
.*?(.*?)
.*?'+
'(.*?)(\d+)
',page,re.S)
for item in items:
data={}
data['rank']=item[0]
data['title']=item[1]
actors=re.sub('\n','',item[2])
data['actors']=actors
data['date']=item[3]
data['score']=str(item[4])+str(item[5])
yield data
urls=['https://maoyan.com/board/4?offset={}'.format(i*10) for i in range(10)]
DATA=[]
for url in urls:
page=get_page(url)
datas=get_info(page)
for data in datas:
DATA.append(data) #将所有的数据添加到DATA里
f=xlwt.Workbook(encoding='utf-8')
sheet01=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet01.write(0,0,'rank') #第一行第一列
sheet01.write(0,1,'title')
sheet01.write(0,2,'actors')
sheet01.write(0,3,'date')
sheet01.write(0,4,'score')
#写内容
for i in range(len(DATA)):
sheet01.write(i+1,0,DATA[i]['rank'])
sheet01.write(i+1,1,DATA[i]['title'])
sheet01.write(i+1,2,DATA[i]['actors'])
sheet01.write(i+1,3,DATA[i]['date'])
sheet01.write(i+1,4,DATA[i]['score'])
print('p',end='')
f.save('E:\\猫眼电影.xls')