利用Python进行简单爬虫(爬取豆瓣《湮灭》短评)
写在最前
(最新更新时间:20190516)
许多初学者想学习爬虫,但是不知道如何上手。其实在百度或者必应搜索用Python进行网页爬虫,会有很多大神的爬取方式与相应的结果。其实很多数据并不是本身就有的,而是需要通过网络爬虫进行爬取获得(例如想要对高分电影或者高分图书进行分析;对一年中某些商品的购买数量的变化情况进行分析等)。所以对网页进行爬虫,是数据分析中一个非常重要的技能。
网络上最多的也是最容易的,其实就是爬取豆瓣的评论与相应的评分信息。正巧本周看了电影《湮灭》,自己感觉,就单纯从科幻、伏笔与悬念的角度而言,不考虑一些硬性逻辑,是一部不可多得的神作。在国外这部电影是高分神片,而在国内,豆瓣对其两极分化非常严重,所以这次就尝试进行对《湮灭》的豆瓣短评以及评分进行爬取,后续还会对爬取的结果用R进行分析。
爬虫的语句或多或少都借助了网上一些前辈经验与代码,特别感谢这些大神。同时也感谢一些实验室的小萌新,本代码是在他们的代码基础上汇总修改的。
爬虫
利用Python进行爬虫(对于简单的静态网页)其实简单来说就是两个步骤:
- 爬取网页的HTML源代码
- 对爬下来的网页进行正则表达式的匹配(使用
BeautifulSoup可以基本不用记正则表达式,后面也会作介绍)
本文实现的是最简单的爬虫技巧,也就是不进行ip地址伪装的对静态页面的爬取。这里分别介绍使用正则表达式以及使用BeautifulSoup两种方式进行爬虫。
下面我们先整理爬虫整体的思路:
1、将网页的HTML源码爬下来
假设我们想爬取一部电影的100条短评,但通常在一个页面中,是不会罗列那么多条短评。所以我们的做法是让计算机自动切换网页,然后进行爬取。但这里就涉及到了很多学问,因为很多网站是不希望爬虫的人爬他们的网站,这样会加剧他们服务器的负担以及被别人利用他们的数据,所以通常都会做一些反爬虫机制。正所谓道高一尺,魔高一丈,对绝大多数的反爬虫机制,爬虫者们都有办法进行解决,这部分在我们这篇博客中,不会进行说明,后面进阶爬虫再来详细叙述。(豆瓣的前200条短评不会涉及到这个问题)
所以第一步的关键是如何让计算机自动切换网页,数十条数十条的爬取,然后拼接在一起。这一步的关键是观察。
我们可以发现第一页短评的网址是:
https://movie.douban.com/subject/26384741/comments?start=0&limit=20&sort=new_score&status=P&percent_type=
第二页:
https://movie.douban.com/subject/26384741/comments?start=20&limit=20&sort=new_score&status=P&percent_type=
第三页:
https://movie.douban.com/subject/26384741/comments?start=40&limit=20&sort=new_score&status=P&percent_type=
可以发现,在start= 与 &limit=20 之间的数值都是20,20的递增,并且每一页恰好都是20条短评,所以想要整理100条短评,就需要下载5个页面,并且是有规律的,这就可以直接写for循环替换中间的数字来实现。
2、通过目标字段前后的内容进行筛选整理
这里可以用两种做法,分别是正则表达式匹配以及BeautifulSoup,对内容进行截取。
举个栗子:我们想要得到每个短评,以及其相应的评分,这就需要我们从源码中找到相应的字符前后对应的源码了。通常我们都是先使用google浏览器,然后对想要爬取的网页先点击右键,然后再点击检查,然后就会出现其源码。然后我们在源码的框框中移动鼠标,左侧就会有原网页的变化。
首先找到全局都框起来的代码,通常都是,效果如下:
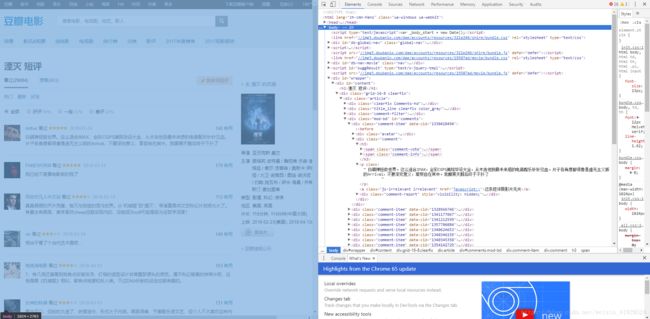
然后点击展开,继续滑动鼠标,一层一层搜索并展开。最后找到我们想要的 短评 与 评分 相对应的位置,具体位置如下图所示:
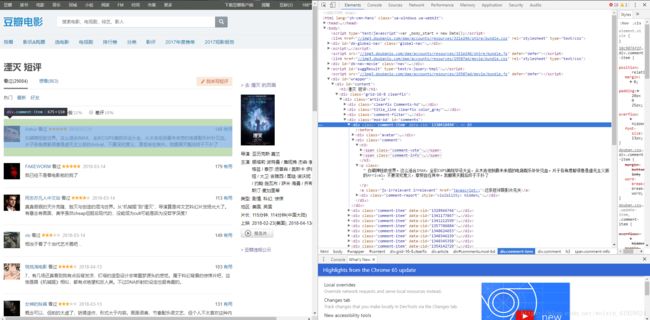
评分:
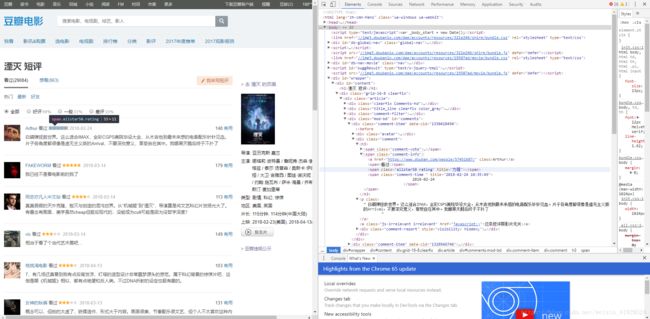
短评:

我们找到短评的前后分别是: 以及
,中间夹着 50 就是5星, 40 就是4星等等。我们可以根据这两点信息分别进行匹配。
找到之后,我们开始用代码进行匹配。
3、最后对所有的数据进行整理并导出Excel表格
这一步直接使用 pandas 库就可以非常轻松的完成。
正则表达式匹配做法
首先我们先载入相关的包:
import urllib.request # 从网页上将html源码爬下来
import re # 进行正则表达式匹配
import pandas as pd # 整理成最后的表格以及输出
import time # 每次爬取设置停止时间
import numpy as np # 随机设置停止时间
定义读取网页的函数:
def getHtml(url):
try:
page = urllib.request.urlopen(url) # 将网页爬取下来
html = page.read() # 存源码到html变量中
except:
print("failed to geturl") # 如果网络连接异常,则报错。
else:
return html
定义正则表达式匹配的函数,其中由于短评较为容易,由于短评没有缺失值,所以使用 re.findall 函数直接进行匹配即可。每页有20条短评,所以每页list的长度都为20。
# 匹配对电影的短评
def getComment(html):
commentList = re.findall(r'(.*?)<'
, html, re.S) # 可能需要根据实际情况进行修改
return commentList
评分汇总起来相对就比较复杂了。因为部分用户在进行短评的时候并没有进行评分,所以爬取每个用户的评分时不能像爬取短评的时候那样,简单的汇总成一个list长度就一定是20,这就需要做一个判断。这里我们使用的判断是每一条短评都有的部分,

然后再判断其中有没有评分,也就是在每一个小block中寻找有没有rating,于是就得到我们下面的匹配对电影评分的一个函数:
# 匹配对电影的评分
def getScore(html):
is_scoreList = re.findall(r'(.*?), html, re.S)
scoreList = []
for item in is_scoreList:
if item.count('rating') == 0:
scoreList.append("NA")
else:
scoreList.append(re.findall(r'
细心的童鞋到这里可能对 re.findall 函数中的内容有些疑问,不知道其中为什么是这样的。还有一些正则表达式的匹配方式又是什么?这里另外开了一篇博客来简述(.*?) 与 re.S 分别是什么含义,并且详细地演示了为什么我们使用如上的匹配能够提取出我们想要的信息。
传送门在此
接着,我们正式编写for循环来进行自动化爬虫:
scoreList=[]
commentList=[]
for page in range(0,220,20): # 0~200,间隔20
# 每个网页的通用表达,将page的内容补入{}中
url = 'https://movie.douban.com/subject/26384741/comments?start={}&limit=20&sort=new_score&status=P&percent_type='.format(page)
html = getHtml(url).decode("UTF-8") # 注意这里需要进行UTF-8转码,通常中文网页都是这种编码
# 爬取分数与评论
scoreList.extend(getScore(html))
commentList.extend(getComment(html))
# 设置每两个网页爬取的间隔时间,2~4s之间随机产生时间,一种反爬虫的手段(在这里可以不要)
time.sleep(np.random.uniform(2, 4))
print(page)
最后,我们将爬取下来的短评与评分整理成数据框的形式,进行数据的存储,可以用于后续的分析等。
data = []
if len(scoreList) == len(commentList):
len_mov = len(scoreList)
for i in range(0,len_mov):
print("score = "+ "".join(scoreList[i]) +" ,\n comment="+commentList[i])
tmp = []
tmp.append(scoreList[i])
tmp.append(commentList[i])
data.append(tmp) # 整理成list
name = ['score','comment']
data = pd.DataFrame(columns = name, data = data) # 利用pandas包转化成数据框形式
os.chdir('D:\Kanny') # 设置存储路径
data.to_csv("movie_annihilation_200.csv") # 存储出来
到这其实一个简单的爬虫攻略就全部完成了,但如果我们不想使用正则表达式来进行匹配,是否有更简单的做法,将评分与短评等信息提取出来呢?
我们来介绍使用 BeautifulSoup 进行字符串操作的方法。
BeautifulSoup做法
Beautiful Soup 是一个HTML/XML的解析器(就是从HTML 或 XML 文件提取你想要的数据),它可以大大节省我们编写正则表达式的时间。
Beautiful Soup 的中文文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/(文档里面的说明已经非常非常的详细了!非常值得推荐!)
载入BeautifulSoup库:
from bs4 import BeautifulSoup
下面就直接进行提取,省去了正则表达式匹配的环节:
scoreList=[]
commentList=[]
for page in range(0, 220, 20):
# 爬取网页(同前面)
url = 'https://movie.douban.com/subject/26384741/comments?start={}&limit=20&sort=new_score&status=P&percent_type='.format(page)
soup = BeautifulSoup(getHtml(url).decode("UTF-8"))
# 先初步提取内容,提取每篇短评的大框架
tags = soup("div", {"class": "comment-item"})
for tag in tags:
# 获取短评信息
comment = tag.p.getText()
# 获取得分信息
try:
score = tag.find(class_ = re.compile("star"))['class'][0]
except:
score = 'NA'
# 总和列表
commentList.append(comment)
scoreList.append(score)
# 设置间隔时间,并输出循环爬取信息
print(page)
time.sleep(np.random.uniform(2, 4))
这里对上面代码中使用到的BeautifulSoup进行详细的说明:
首先 :
soup("div",{"class":"comment"})
等价于
soup.find_all("div",{"class":"comment"})
其目的是将每个HTML中的 与 之间夹着的内容进行提取,组合成类似list的结构。有几个这样的结构,其长度就为几。我们将这个集合定义为tags,它由多个tag组成
tag长下面这样:
<div class="comment-item" data-cid="1341158132">
<div class="avatar">
<a href="https://www.douban.com/people/nezhaboy/" title="哪吒男">
<img class="" src="https://img3.doubanio.com/icon/u42174843-51.jpg"/>
a>
div>
<div class="comment">
<h3>
<span class="comment-vote">
<span class="votes">14span>
<input type="hidden" value="1341158132"/>
<a class="j a_show_login" href="javascript:;" onclick="">有用a>
span>
<span class="comment-info">
<a class="" href="https://www.douban.com/people/nezhaboy/">哪吒男a>
<span>看过span>
<span class="allstar30 rating" title="还行">span>
<span class="comment-time " title="2018-03-14 17:40:15">
2018-03-14
span>
span>
h3>
<p class=""> 亚历克斯加兰的作品,最美、最有想象力、最动人心魄的就是片尾字幕的设计了!
p>
div>
div>
然后,我们获取短评信息所使用的:
comment = tag.p.getText()
是找到每个tag中间的
的内容,这样获得的comment为:
' 亚历克斯加兰的作品,最美、最有想象力、最动人心魄的就是片尾字幕的设计了!\n '
如果不加上.getText(),就会将前后的与
try:
score = tag.find(class_ = re.compile("star"))['class'][0]
except:
score = 'NA'
之所以用了try-except是因为如果用户没有评分,那么tag.find那串话会报错,而如果有进行评分,那么就会有如下部分:
<span class="allstar30 rating" title="还行">span>
其中包含了star这个字符串,所以我们要使用
tag.find(class_ = re.compile("star"))
将上面那个部分进行输出,其中的 re.compile 表示对"star"进行UNICODE编码,然后再使用['class']
,提取出:
['allstar30', 'rating']
然后我们保留前面一个。如果还想要将里面的3提取出来,再用一些字符串操作的技巧即可。
到这里我们就成功使用了BeautifulSoup进行爬虫后面的匹配操作。
最后
当然是大家喜欢哪个,就使用哪个!(虽然自己比较偏好于正则表达式)
一定要自己动手实践哦!
分享一下我们的部分结果:
,score,information
0,['3'],"属于“工作日宝贵的晚上看这个可能会比较懊悔”一类
"
1,['3'],"前大半槽点太多扣一星:美帝军人/科学家就是死光了也不会派这么垃圾的队伍执行关乎人类存亡的任务。狗一样的心理学家就是盖茨/总统女儿也当不上项目/队伍领导。0生/物/化/核防护装备逗我【不懂怎么评价这个设定和世界观,并不硬核…洞里那段鸟肌…最后结束得太御都合。政府还有智商就该立马搞死男女主
"
2,['4'],"1.又名《膨胀的保鲜膜》,讲一群人进入保鲜膜探险的故事。2.故事告诉我们:女生为了调查丈夫去哪儿了,什么事都干得出来。3.如果丈夫一年才回一次家,那他可能不是你丈夫。4.娜塔莉一次得到两个奥斯卡(·伊萨克)。5.泰莎汤普森演的是三毛转世,因为三毛说来生要做一颗树。6.雷神不去救女友和女武神吗
"
3,['2'],"所以三年内全军覆没之后的决定就是派五个毫无防备的女科学家进去考察?你检疫站谈话都要隔离,然后派人进去就直接裸?全片就是个故弄玄虚外壳下的低成本b级片。充斥着exposition的谈话,谈话,然后谈话?全员智商掉线,表演生硬,摄影特效眩光亮瞎狗眼,最后随便丢一个高概念的结尾糊弄观众。。
"
4,['4'],"文科生看不懂《降临》,理科生看不懂《湮灭》。
"
5,['5'],"看完湮灭出来 漫天飞雪 市中心灯光如昼 高楼上的液晶屏在播放芭蕾表演 车站里几个女生簇拥说笑着 突然觉得能平凡活着真好
"
6,['4'],"科幻片拍成这样,可以说是相当高级了!惊心动魄又渗透着冷峻的美感,神秘莫测还搭配着复杂的内核,真的很久没有看一部怪奇题材的科幻电影能让人如此屏气凝神了。
"
7,['3'],"看完前10分钟,扪心自问一次;看完30分钟后,再扪心自问一次;看到结尾,还想扪心自问,发现胸口都扣烂了……一开始,我觉得这片子就是拍砸了……后来,我看了大银幕,觉得都TMD怪资本家……
"
8,['5'],"或许是今年最好的科幻片了!相比《降临》,《湮灭》在想象力上丝毫不逊色。加兰对于影片节奏与气氛的塑造完全是大师水准,而娜塔丽波特曼也贡献了极为精彩的表演!
"
9,['2'],"只有我一个人觉得难看么?原著第一部读的时候那种氛围现在还记得,电影里那些花是淘宝包邮买的吗?还敢更假一点么?
"
10,['2'],"对这漏洞百出的设定实在不能忍,本着对科学的忠诚还是回来给个差评
"
11,['4'],"从机械姬中的未来极简主义 到这部的末世/废土美学 都可见导演高超的个人品味 剧情掌控极佳 叙事缓慢到来 视听效果上乘 音响马力十足轰炸全场 五位女主演都贡献精彩的演出 小说自身承载厚重 改编则简化剧情线索 但开放讨论与结局 不同观众可以得到不同答案
"
12,['4'],"其实故事设定还是比较简单的,半程左右就说明白了,所以到了最后更多是被视觉效果所震,音乐也配的不错。科幻内核是不如机械姬的,整个电影更像是异形那种团队探险密室惊悚。老美的科幻片为啥总是设定成“一个人生活中受创,失去了爱人,生无可恋了于是决定赌上性命跟外星人搏斗”,看多了感觉略土
"
13,['4'],"【8/10】原著已经被改得面目全非,更像是基于原著设定上的新故事,内核也更像是《机械姬》的延续(人/非人;己/非己)。整体场景设计和氛围营造实在太出色了,亦有近年来最出色的恐怖场景之一,甚至还有疑似的《异形》致敬。可惜结尾相对实在逊色,有些概念卖得也含糊隐晦。总体还是上佳之作。
"
14,['2'],"在我看来,除了那带点艺术感的场景想象力之外,这片子可以说是一无是处的神棍片,甚至算不上科幻片,顶多就算个比较装逼的恐怖片
"
15,['4'],"导演延续了【机械姬】的所有优点,而且能从中看出很多大导演的影子,在丹尼斯·维伦纽瓦之后,再一次看到有人致敬老塔的【潜行者】,剧作在类型上属于老雷的【异形】,不过是更克苏鲁气质的版本,从情绪上更像极简动作版的【降临】,但最终还是加兰导演自己,最爱死亡场景里装置艺术一般的视觉效果。
"
16,['5'],"卧槽啊这他妈的恐怕是我看过的最creepy的东西了!
"
17,['2'],"真的不喜欢如今软科幻的发展方向