spark入门框架+python
目录:
简介
pyspark
IPython Notebook
安装
配置
spark编写框架:
首先开启hdfs以及yarn
1 sparkconf
2 sparkcontext
3 RDD(核心)
4 transformation(核心)
5 action(核心)
当然也可以指定运行py程序
-
简介:
不可否认,spark是一种大数据框架,它的出现往往会有Hadoop的身影,其实Hadoop更多的可以看做是大数据的基础设施,它本身提供了HDFS文件系统用于大数据的存储,当然还提供了MR用于大数据处理,但是MR有很多自身的缺点,针对这些缺点也已经有很多其他的方法,类如针对MR编写的复杂性有了Hive,针对MR的实时性差有了流处理Strom等等,spark设计也是针对MR功能的,它并没有大数据的存储功能,只是改进了大数据的处理部分,它的最大优势就是快,因为它是基于内存的,不像MR每一个job都要和磁盘打交道,所以大大节省了时间,它的核心是RDD,里面体现了一个弹性概念意思就是说,在内存存储不下数据的时候,spark会自动的将部分数据转存到磁盘,而这个过程是对用户透明的。
spark安装及配置部分可以参看:https://mp.csdn.net/postedit/82346367
-
pyspark
下面介绍的例子都是以python为框架
因为spark自带python API即pyspark,所以直接启动即可
很简单使用pyspark便进入了环境:

但是在命令行中总归是不方便,所以下面的案例均在IPython Notebook中进行
-
IPython Notebook
使用IPython Notebook开发更加方便
安装
sudo apt-get install ipythonudo apt-get install ipython-notebook安装好后就可以启动了:
ipython notebook配置:
sudo vim /etc/bash.bashrcexport PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"source /etc/bash.bashrc然后再次使用pyspark启动时就会自动启动IPython Notebook啦!!!!!!!!!!
-
spark编写框架:
首先开启hdfs以及yarn:

1 sparkconf:
sparkconf对象是是spark应用的配置信息:
2 sparkcontext:
是调用spark一切功能的一个接口,使用不同的开发语言对应不同的接口,类如java就是javasparkcontext,SQL就是SQLspark,Python,Scala等等都是如此

这里报错是因为开启了多个SparkContests,所以解决方法是先关闭:

3 RDD(核心):
创建初始RDD有三种方法(用textFile时默认是hdfs文件系统):
使用并行化集合方式创建

这里主要就是使用了parallelize方法,至于collect下面会有详细介绍
使用本地文件创建:
进行一个wordcount任务
sparktest.txt


这里看不懂没关系,下面都会详细介绍,这里主要知道,可以读取file://本地文件就可以了
注意:在linux上面要使用本地文件时,需要将data.txt拷贝到所有worker。
使用一些其他文件储存系统类如Hdsf:
先要上传一个文件,这里还是上传上面的sparktest.txt吧,进行一个wordcount任务

from pyspark import SparkContext, SparkConf
conf=SparkConf()
conf.setAppName("My app")
sc.stop()
sc = SparkContext(conf=conf)
lines=sc.textFile("hdfs://localhost:9000/sparktest.txt")
words=lines.flatMap(lambda line:line.split(" "))
keyvalue=words.map(lambda word:(word,1))
result=keyvalue.reduceByKey(lambda x,y:x+y)
print(result.collect())
这里也是看不懂没关系,下面都会详细介绍,这里主要知道,可以读取hdfs://本地文件就可以了
注意:使用Hdfs时,在配置Spark时,将setMaster设置的local模式去掉即:
4 transformation(核心):
spark中的一些算子都可以看做是transformation,类如map,flatmap,reduceByKey等等,通过transformation使一种GDD转化为一种新的RDD。
一些算子介绍:
map:就是对每一条输入进行指定操作,为每一条返回一个对象:
flatmap: map+flatten即map+扁平化.第一步map,然后将map结果的所有对象合并为一个对象返回:

可以看到使用map时实际上是[ [0,1,2,3,4],[0,1,2],[0,1,2,3,4,5,6] ]
类如切分单词,用map的话会返回多条记录,每条记录就是一行的单词,
而用flatmap则会整体返回一个对象即全文的单词这也是我们想要的。
mapValues:对于key-value这种数据类型中每一个value操作:

filter:筛选符合一定条件的数据:
distinct:去重
randomSplit:切分数据:

groupBy:依据什么条件分组

groupbykey:通过key进行分组
在java中返回类型还是一个JavaPairRDD,第一个类型是key,第二个是Iterable里面放了所有相同key的values值
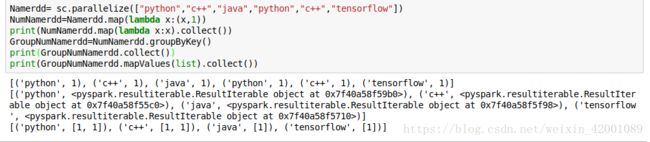
reduceByKey:有三个参数,第一个和第二个分别是key,value,第三个是每次reduce操作后返回的类型,默认与原始RDD的value类型相同,


sortByKey:排序

cartesian: 返回一个笛卡尔积的数据集:

join:就是mysal里面的join,连接两个原始RDD,第一个参数还是相同的key,第二个参数是一个Tuple2 v1和v2分别是两个原始RDD的value值:
还有leftOuterJoin和rightOuterJoin,其实这里就是类似mysql里面的,这里不再详细介绍,可自行百度
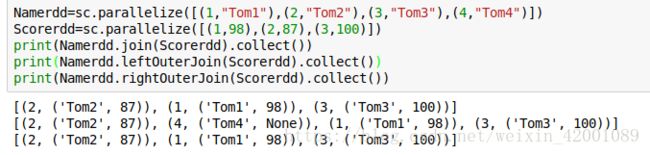
cogroup:和join类似,只不过返回的RDD两个都是Iterable:

transformation 的一个重要特性就是Lazy,就是说虽然定义了各种transformation,但是都不会执行,只有在执行了一个action动作后才会触发所有的transformation,这是spark的一种优化,避免产生过多的中间结果,所以下面看一下什么是action
5 action(核心):
例如foreach,reduce就是一种action操作,后者是将RDD中多有元素进行聚合,获取最终结果,返回给Drive程序,action 的特性就是触发一个spark job,进一步触发上面的transformation。即在执行action后,Driver才会提交task到之前注册的worker上的executor一步步执行整个spark任务(定义的那些transformation啥的)
action 也有很多:
reduce:即将RDD所有元素聚合,第一个和第二个元素聚合产生的值再和第三个元素聚合,以此类推

collect:将RDD中所有元素获取到本地客户端
这个在上面已经充分体现了
count:获取RDD元素总数

take(n):获取RDD中前n个元素:

first() : 返回RDD中的第一个元素:

top:返回RDD中最大的N个元素
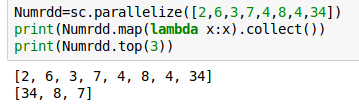
takeOrdered(n [, key=None]) :返回经过排序后的RDD中前n个元素

min,max,mean,stdev:
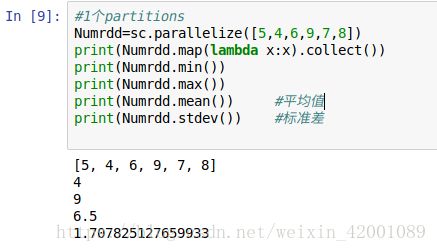
fold:对每个分区给予一个初始值进行计算:

countByKey:对相同的key进行计数:

countByValue:对相同的value进行计数

takeSample:取样

foreach:遍历RDD中的每个元素
saveAsTextFile:将RDD元素保存到文件中(可以本地,也可以是hdfs等文件系统),对每个元素调用toString方法
textFile:加载文件

-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
当然也可以指定运行py程序:
WordCount:
from pyspark import SparkContext, SparkConf
conf=SparkConf()
conf.setAppName("My app")
sc = SparkContext(conf=conf)
lines=sc.textFile("hdfs://localhost:9000/sparktest.txt")
words=lines.flatMap(lambda line:line.split(" "))
keyvalue=words.map(lambda word:(word,1))
result=keyvalue.reduceByKey(lambda x,y:x+y)
print(result.collect())

运行:
spark-submit WordCount.py 