pythton爬取智联招聘职位信息
前言
在智联招聘https://sou.zhaopin.com/时,发现无法直接去解析获得的html文本,它的数据是用js动态加载的,数据内容存储在json文件中,所以不能用以前的方法使用xpath、bs4或正则进行解析
如需用MapReduce对此数据进行清洗,请移步下方链接
优化前代码(注释详细):https://blog.csdn.net/weixin_42063239/article/details/88315036
优化后代码(只列出了优化内容):https://blog.csdn.net/weixin_42063239/article/details/88537897
分析
首先要找到获取json文件的链接
在进入到页面后F12打开Google的开发者工具,点击Network并刷新页面查看请求的资源有哪些
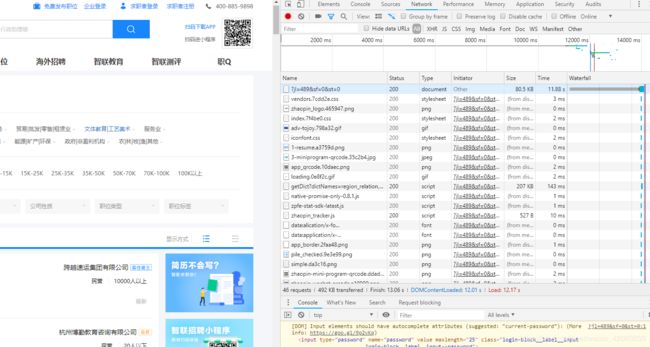
可以看到此网页请求了很多资源,想要更快捷的寻找存储json数据的请求则点击ALL右边的XHR
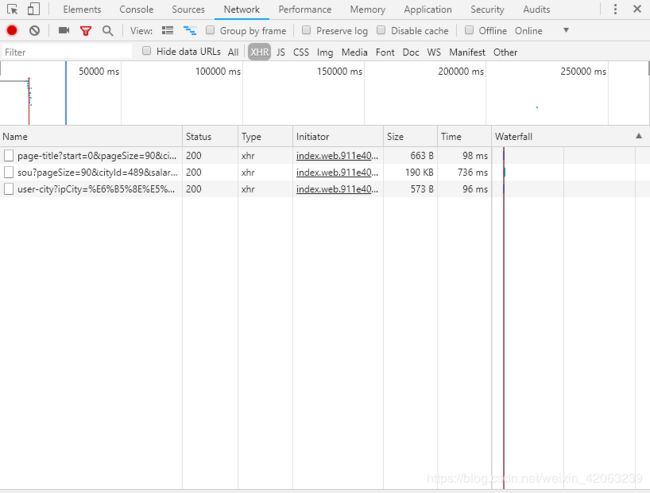
双击查看资源发现第二条是我们要找的数据内容

分析URL
此时我们复制地址栏的URL
https://fe-api.zhaopin.com/c/i/sou?pageSize=90&cityId=489&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kt=3&=0&_v=0.35297839&x-zp-page-request-id=9793ccbae74e490d9fc80be4a9ce4c14-1552438664291-807665
进入第二页的职位信息并重复以上操作得到URL为
https://fe-api.zhaopin.com/c/i/sou?start=90&pageSize=90&cityId=489&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kt=3&=0&_v=0.08335930&x-zp-page-request-id=dc74ace3a94446b3a0b26779f7d5f86c-1552439126154-995031
观察可以得到此URL中?后的有用参数为start和pageSize,分别指定了获得数据的起始位置和获得数据的条数,因为此网页只能查看12页的内容,每页有90条信息,当我们把start参数设为1080时获取页面为

可知最多能获得1080条数据,则我们可以访问12次来获取数据,每次的start参数分别0, 90, 180, 270 ……990,pageSize为90
爬虫部分
import requests
import json
import csv
from bs4 import BeautifulSoup
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
# 传入获取数据的起始位置,返回一个字典列表,每条数据为一个字典
def get_data(start):
response = requests.get(url='https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=90'.format(start), headers=headers)
response.encoding = 'utf-8'
# 把json格式的文本转成字典
data_dict = json.loads(response.text)
# 创建存储数据的空列表
data_list = []
# 找到存放数据的列表,遍历并获取想得到的数据
for item in data_dict['data']['results']:
# 把范围型薪资转化为最高薪资和最低薪资,parse_salary()方法在后方定义并说明
# 使用 字典.get(键, a)方法可以在没有键为此值的元素时返回a,防止出现异常
salarys = parse_salary(item.get('salary', ''))
data = {
'company_name': item.get('company', dict()).get('name', ''),
'company_size': item.get('company', dict()).get('size', dict()).get('name', ''),
'job_city': item.get('city', dict()).get('display', ''),
'updateDate': item.get('updateDate', ''),
'low_salary': salarys[0],
'high_salary': salarys[1],
'edu_level': item.get('eduLevel', dict()).get('name', ''),
'job_name': item.get('jobName', ''),
'work_exp': item.get('workingExp', dict()).get('name', ''),
# 在json文件里没有职位要求信息,需要通过url到相应的页面获取
'url': item.get('positionURL', '')
}
print(data)
# 把所有的数据添加进列表
data_list.append(data)
return data_list
# 获取起始start参数列表
def get_page():
page_list = []
for i in range(0, 12):
page_list.append(i*90)
return page_list
# 因为想保存一份json格式文件和一份csv格式文件,所以在此把字典列表转化为普通列表数据
def trans_dict_to_list(data_dict_list):
data_list = []
for data_dict in data_dict_list:
data_list.append(data_dict.values())
return data_list
# 传入解析完json获得的字典列表
def get_job_desc(data_list):
total_data = []
# 遍历列表,判断键url对应的值是否为空
# 在字典中加入键为job_desc的元素
# 如url为空则job_desc的值为空字符串
# 如url不为空则获取此url页面并解析
for item in data_list:
url = item['url']
item['job_desc'] = ''
if url:
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
html = response.text
# 创建bs对象
bs = BeautifulSoup(html, 'html.parser')
# 获得职位描述所在的div
data = bs.select('.pos-ul')
if data:
# 删除空格、换行及特殊字符
raw_info = ''.join(str(data[0]).split())
# 删除html标签
reg = re.compile(r'')
item['job_desc'] = re.sub(reg, '', raw_info)
# 因为职位描述已经抓取,url没用了,删除此元素
del(item['url'])
print(item)
# 把数据添加到新列表
total_data.append(item)
return total_data
# 传入salary字符串,返回一个包含最低薪资和最高薪资的列表
# 并把K替换为1000
def parse_salary(salary):
salarys = ['', '']
if 'K' in salary:
salary = salary.replace('K', '000')
if '-' in salary:
salarys = salary.split('-')
else:
salarys = [salary, salary]
return salarys
if __name__ == '__main__':
all_data = []
for page in get_page():
all_data += get_data(page)
end_data = get_job_desc(all_data)
try:
with open('f://zhilian.json', 'a+', encoding='utf-8') as file:
json.dump(end_data, file, ensure_ascii=False)
with open('f://zhilian.csv', 'a+', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(trans_dict_to_list(end_data))
except Exception as e:
print(e)
注:查看获取的json数据格式时,可以先把pageSize设为1,用json.loads()转化成字典后用字典相应操作查看字典结构,可以查看我整理的字典常用操作,在保存数据文件时,尽量用utf-8编码来储存,因为在职位描述中有一些gbk无法识别的内容,保存为utf-8后的csv文件用exce打开会乱码,这里建议另存为转码,也可以上传到linux中查看,或者用notepad++打开,保存为utf-8另一个好处为在用MapReduce进行清洗时不用进行转码
notepad++打开查看结果
