浅析Linux中完全公平调度——CFS
| 日期 | 内核版本 | 架构 | 作者 | 内容 |
|---|---|---|---|---|
| 2018-11-11 | Linux-2.6.32 | X86 |
Bystander | Linux系统CFS |
一、前序
目前Linux支持三种进程调度策略,分别是SCHED_FIFO 、 SCHED_RR和SCHED_NORMAL;而Linux支持两种类型的进程,实时进程和普通进程。实时进程可以采用SCHED_FIFO 和SCHED_RR调度策略;普通进程则采用SCHED_NORMAL调度策略。从Linux2.6.23内核版本开始普通进程(采用调度策略SCHED_NORMAL的进程)采用了绝对公平调度算法,不再跟踪进程的睡眠时间,也不区分是否为交互式进程,它将所有的进程都统一对待,这就是完全公平的含义。
二、CFS基本原理概述
cfs定义了一种新调度模型,它给cfs_rq(cfs的run queue)中的每一个进程都设置一个虚拟时钟-virtual runtime(vruntime)。如果一个进程得以执行,随着执行时间的不断增长,其vruntime也将不断增大,没有得到执行的进程vruntime将保持不变。
而调度器将会选择最小的vruntime那个进程来执行。这就是所谓的“完全公平”。不同优先级的进程其vruntime增长速度不同,优先级高的进程vruntime增长得慢,所以它可能得到更多的运行机会。
三、CFS算法设计核心
CFS根据各个进程的权重分配进程运行时间。
进程的运行时间计算公式为:
分配给进程的运行时间 = 调度周期 * 当前进程权重 / 所有进程权重总和 (公式3.1)
备注:调度周期:将所有处于TASK_RUNNING态进程都调度一遍的时间,在O(1)调度算法中就是运行队列中进程运行一遍的时间。所以进程权重与分配给进程的运行时间成正比。
vruntime的计算公式为:
vruntime = 实际运行时间 * NICE_0_LOAD/ 当前进程权重 (公式3.2)
如果分配给进程的运行时间等于实际运行的时间时,将推到出另一vruntime计算公式。把公式3.2中的分配给进程的运行时间 与公式3.1中实际运行时间替换,将得出以下结果:
vruntime = (调度周期 * 当前进程权重 / 所有进程权重总和) * NICE_0_LOAD/ 当前进程权重
= 调度周期 * NICE_0_LOAD/ 所有进程权重总和
初步结论:当分配给进程的运行时间等于实际运行的时间时,虽然每个进程的权重不同,但是它们的 vruntime增长速度均相同,与权重无关。上文已述用vruntime来选择将要运行的进程,vruntime值较小表明它以前占用cpu的时间较短,受到了“不公平”对待,因此下一个运行进程就是它。如此一来既能公平选择进程,又能保证高优先级进程获得较多的运行时间。
如果分配给进程的运行时间不等于实际运行的时间时:CFS的思想就是让每个调度实体的vruntime增加速度不同,权重越大的增加的越慢,这样高优先级进程就能获得更多的cpu执行时间,而vruntime值较小者也得到执行。
每一个进程或者调度组都对应一个调度的实体,每一个进程都通过调度实体与CFS运行对列建立联系,每次进行CFS调度的时候都会在CFS运行对列红黑树中选择一个进程(vruntime值较小者)。cfs_rq代表CFS运行对列,它可以找到对应的红黑树。进程task_struct ,可以找到对应的调度实体。调度实体sched_entity对应运行对列红黑树上的一个节点。
四、CFS调度器
4.1调度器概述
现代的操作系统是多任务的操作系统,硬件的处理器核心和各种资源越来越多,CPU也是一个资源。为了保证进程合理的使用CPU资源,则需要一个管理单元,负责调度进程,由管理单元来决定下一刻应该由谁使用CPU,这里管理单元就是进程调度器。调度器可以临时分配一个任务在上面执行(单位是时间片)。进程调度器的任务就是合理分配CPU时间给运行的进程,创造一种所有进程并行运行的错觉,使得我们同时执行多个程序成为可能,可以具有各种需求的用户共享CPU。因此调度器必须在各个进程之间尽可能公平地共享CPU时间, 而同时又要考虑不同的任务优先级。调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器的一般原理是, 按所需分配的计算能力, 向系统中每个进程提供最大的公正性, 或者从另外一个角度上说, 试图确保没有进程被亏待。
4.2调度器的结构
在目前Linux内核中,调度器分成两个层级,在进程中被直接调用的成为通用调度器或者核心调度器,它们作为一个组件和进程其它部分分开,而通用调度器和进程并没有直接关系,其通过第二层的具体的调度器类来直接管理进程。具体架构如下图:
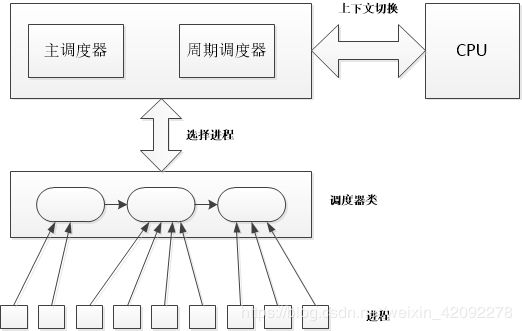
4.2.1调度器类:
Linux内核中实现了一个调度器类的框架,其中定义了调度器应该实现的函数,每一个具体的调度器类都要实现这些函数 。
在Linux版本中(3.11.1),使用了四个调度器类:stop_sched_class、rt_sched_class、fair_sched_class、idle_sched_class,在最新的内核中又添加了一个调度类dl_sched_class。每个进程必然属于一个特定的调度器类,Linux会根据不同的需求实现不同的调度器类。各个调度器类之间具备一定的层次关系,即在通用调度器选择进程的时候,会从最高优先级的调度器类开始选择,如果通用调度器类没有可运行的进程,就选择下一个调度器类的可用进程,这样逐层递减。调度器类的定义 为sched_class的结构体。
struct sched_class {
const struct sched_class *next;
//向就绪队列添加一个进程,该操作发生在一个进程变成就绪态(可运行态)的时候。
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
//执行enqueue_task的逆操作,在一个进程由运行态转为阻塞的时候就会发生该操作。
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
//进程自愿放弃控制权的时候
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
//挑选下一个可运行的进程,发生在进程调度的时候
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p, int next_cpu);
void (*pre_schedule) (struct rq *this_rq, struct task_struct *task);
void (*post_schedule) (struct rq *this_rq);
void (*task_waking) (struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
//当进程的调度策略发生变化时,需要执行此函数
void (*set_curr_task) (struct rq *rq);
//在每次激活周期调度器时,由周期调度器调用
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
//建立fork系统调用和调度器之间的关联,每次新进程建立后,就调用该函数通知调度器
void (*task_fork) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p, int on_rq);
#endif
};4.2.2周期调度器:
周期调度器根据频率自动调用scheduler_tick函数。其主要作用就是根据进程运行时间触发调度;在进程遇到资源等待被阻塞也可以显示的调用调度器函数进行调度;另外在有内核空间返回到用户空间时,会判断当前是否需要调度,在进程对应的thread_info结构中,有一个flag,该flag字段的第二位(从0开始)作为一个重调度标识TIF_NEED_RESCHED,当被设置的时候表明此时有更高优先级的进程,需要执行调度。另外目前的内核支持内核抢占功能,在适当的时机可以抢占内核的运行。周期性调度器并不直接调度,至多设置进程的重调度位TIF_NEED_RESCHED,在返回用户空间的时候仍然由主调度器执行调度。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
spin_lock(&rq->lock);
update_rq_clock(rq);
update_cpu_load(rq);
curr->sched_class->task_tick(rq, curr, 0);
spin_unlock(&rq->lock);
perf_event_task_tick(curr, cpu);
#ifdef CONFIG_SMP
rq->idle_at_tick = idle_cpu(cpu);
trigger_load_balance(rq, cpu);
#endif
}4.2.3主调度器:
主调度器是通过schedule()函数来完成进程的选择和切换。
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
//禁止内核抢占
preempt_disable();
cpu = smp_processor_id();
//获取CPU 的调度队列
rq = cpu_rq(cpu);
rcu_note_context_switch(cpu);
//保存当前进程任务
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
/* 当内核态没有被抢占, 并内核抢占有效时
即同时满足以下条件:
1 该进程处于停止状态
2 该进程没有在内核态被抢占 */
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
pre_schedule(rq, prev);
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
//通知调度器prev进程将被调度出去
put_prev_task(rq, prev);
//选择下一个可运行进程
next = pick_next_task(rq);
//清除pre的TIF_NEED_RESCHED标志
clear_tsk_need_resched(prev);
rq->skip_clock_update = 0;
//如果next和当前进程不一致时可以调度
if (likely(prev != next)) {
rq->nr_switches++;
//设置当前调度进程为next
rq->curr = next;
++*switch_count;
//切换进程上下文
context_switch(rq, prev, next); /* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
raw_spin_unlock_irq(&rq->lock);
post_schedule(rq);
sched_preempt_enable_no_resched();
if (need_resched())
goto need_resched;
}4.2.4上下文切换:
上下文切换主要由context_switch函数完成,主要做了两件事情:切换地址空间、切换寄存器域和栈空间。整个切换过程需要加锁和关中断,首先切换的是地址空间,mm 和active_mm分别代表调度和被调度的进程的 mm_struct,如果mm为空,则表明next是内核线程,内核线程没有自己独立的地址空间,所以其mm为null,运行的时候使用prev的active_mm即可。如果非空,则是用户进程,那么可以直接切换,这里调用switch_mm函数进行切换;如果prev为内核线程,由于其没有独立地址空间,所以需要设置其active_mm为null。最后进程切换的部分调用switch_to来切换寄存器域和栈。(switch_to是一个宏,由汇编代码实现,有能力者可深入学习)
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
//进程切换准备工作加锁和关中断,最后调用finish_task_switch
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
//如果要执行的是内核线程
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
//如果被调度的是内核线程
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
context_tracking_task_switch(prev, next);
/* Here we just switch the register state and the stack. */
//切换寄存器域和栈
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}笔者仓促成文,不当之处,尚祈读者批评指正!笔者及时纠正。