运用MTCNN和Facenet模型实现人脸识别和检测
引言
积跬步以至千里,积怠情以至深渊。
这应该算是本人第一篇用心写的博客了。网上也已经有很多关于人脸识别的博客,但是受某票圈各位大佬的影响,还是决定把刚完成的CV课程的大作业在这里写篇博客做个详细的记录,也算是总结下收获和体验了。这其中也参考了很多大佬的博客,感谢路过的各位大佬批评指正。
这篇博客的内容关于本人在实现人脸识别系统过程中的一些总结以及感悟,这其中包括部分源自Google的Facenet的源码解读、个人在实现人脸识别时经过学习总结的一些思路以及部分代码片段分享等内容。
整体思路
参考论文
主要参考了文献:
1.FaceNet
Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
2.MTCNN
Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
3.《如何应用 MTCNN 和 FaceNet 模型实现人脸检测及识别》
https://www.infoq.cn/article/how-to-achieve-face-recognition-using-mtcnn-and-facenet
NT:关于论文的解读这里就不再赘述,网上已经有大量的分析。
Facenet推理过程
Facenet
这是谷歌的一个开源项目,实现了将输入的人像最终转换为shape为1*128的向量,而后通过计算不同照片之间的欧几里德距离来判他们的相似度。预训练模型请戳这里下载
MTCNN
该模型是一个Multi-task的人脸检测框架,使用了3个CNN级联算法结构,将人脸检测和人脸特征点检测同时进行。需要经历Resize、P-Net、R-Net、O-Net四个阶段。简单的说,这就是一个检测图片中人脸位置的一个模型。
实现流程
1.通过MTCNN人脸检测模型,从照片中提取人脸图像
#返回提取后的图像
def get_crop_image(image_paths, image_size, margin, gpu_memory_fraction)
minsize = 20 # minimum size of face
threshold = [ 0.6, 0.7, 0.7 ] # three steps's threshold
factor = 0.709 # scale factor
print('创建网络,并载入相关参数:')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
img_list = []
for image in image_paths:
print(image
img = misc.imread(image, mode='RGB')
img_size = np.asarray(img.shape)[0:2]
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
if len(bounding_boxes) < 1:
image_paths.remove(image)
print("无法检测到人脸,并移除图像 ", image)
continue
det = np.squeeze(bounding_boxes[0,0:4])
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0]-margin/2, 0)
bb[1] = np.maximum(det[1]-margin/2, 0)
bb[2] = np.minimum(det[2]+margin/2, img_size[1])
bb[3] = np.minimum(det[3]+margin/2, img_size[0])
cropped = img[bb[1]:bb[3],bb[0]:bb[2],:]
# 根据cropped位置对原图resize,并对新得的aligned进行白化预处理
aligned = misc.imresize(cropped, (image_size, image_size), interp='bilinear')
prewhitened = facenet.prewhiten(aligned)
img_list.append(prewhitened)
images = np.stack(img_list)
return images
2.把人脸图像输入到Facenet中,计算Embedding的特征向量
# Get input and output tensor
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder =tf.get_default_graph().get_tensor_by_name("phase_train:0")
image=[]
nrof_images=0
#该路径为mtcnn模型训练后得到的图像的存储路径
emb_dir='E:\\WorkSpace\\PycharmProject\\face_recognition_system\\embed_img'
all_img=[]
for i in os.listdir(emb_dir):
all_img.append(i)
img = misc.imread(os.path.join(emb_dir,i), mode='RGB')
prewhitened = facenet.prewhiten(img)
image.append(prewhitened)
nrof_images=nrof_images+1
images=np.stack(image)
feed_dict = { images_placeholder: images, phase_train_placeholder:False }
compare_emb = sess.run(embeddings, feed_dict=feed_dict)
compare_num=len(compare_emb)
3.比较特征向量间的欧式距离,判断是否为同一个人。
例如当距离小于1时,则认为时同一个人。在进行比较时,需要计算带比较人脸的特征向量。
结合OpenCV实现实时人脸识别系统
关于OpenCV的一点干货
呃…还是直接看本人在github上分享的关于OpenCV简单功能实现的代码片段吧!!
下面介绍一款可以调用手机摄像头的APP,并结合OpenCV使用,IPhone手机亲测可用。苹果手机直接下载IP摄像头 简化版即可,可不用下载付费款的。下载完成后,打开软件,点击打开IP摄像头服务器,而后出现以下界面,记下红框中的IP地址。
然后就是结合OpenCV使用的部分代码了:
# 开启ip摄像头
# 此处@后的ipv4 地址需要修改为上面记下的IP地址,并且客户端与手机需要连接在同一个局域网下
video = "http://admin:[email protected]:8081/"
# 参数为0表示打开内置摄像头,参数是视频文件路径则打开视频
capture = cv2.VideoCapture(video)
cv2.namedWindow("camera", 1)
while True:
ret, frame = capture.read()
cv.imshow(title, frame)
相信,在搞懂本人在github上上传的代码片段以及以上代码,怎么实现实时人脸识别系统,就可以根据自己想要的设计开发属于自己的人脸识别系统啦。至于识别精度方面。。相信谷歌。。亲测。。说可以也还可以。。说不可以也还真不可以。。
人脸识别结果
人脸识别结果的展示:
1.只要检测到人脸框就进行标注

|
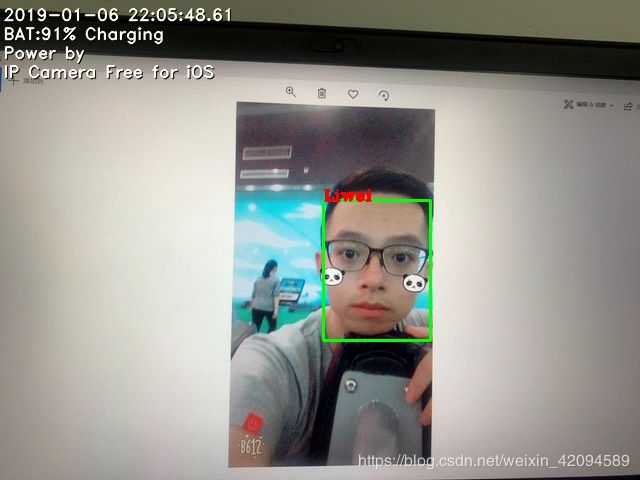
|
2.展示检测到的图像中最大的人脸
利用mtcnn计算图片中检测到的所有人脸框中最大的一个人脸框,并显示其身份。
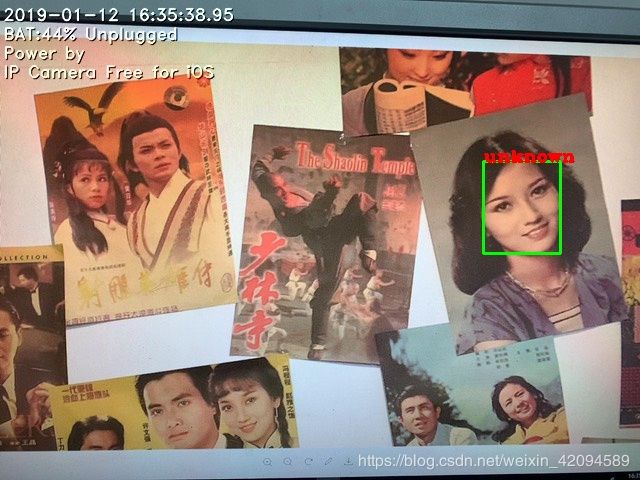
|
相关代码片段,其中det为调用align.detect_face.detect_face函数后得到的返回值,并进行相关处理后的结果:
#找最大矩形框
for rec_position in range(len(det)):
a = abs(det[rec_position, 0]-det[rec_position, 2])
b = abs(det[rec_position, 1]-det[rec_position, 3])
s = a*b
if s > max_area:
max_area = s
max_area_point = [det[rec_position, 0],det[rec_position, 1],
det[rec_position, 2],det[rec_position, 3]]
#绘制矩形框
cv2.rectangle(frame, (max_area_point[0], max_area_point[1]),
(max_area_point[2], max_area_point[3]), (0, 255, 0), 2, 8, 0)
#在左上角输出对应信息
cv2.putText(
frame,
result[rec_position],
(max_area_point[0], max_area_point[1]),
cv2.FONT_HERSHEY_COMPLEX_SMALL,
0.8,
(0, 0, 255),
thickness=2,
lineType=2)
3 在识别到最大人脸框后,将这个人在里对应的最像的照片缩小叠加显示在边上
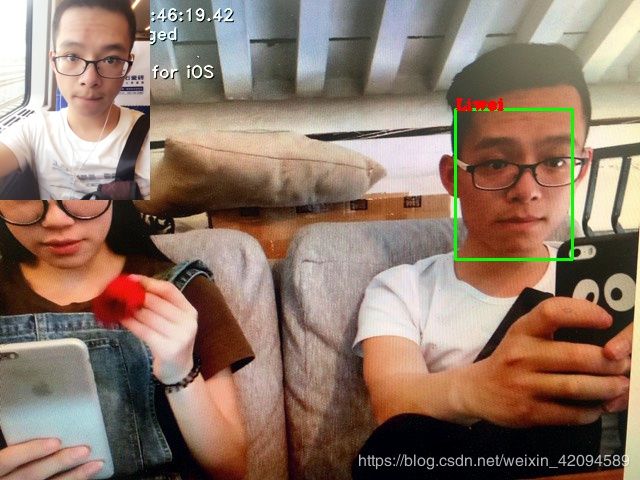
|
验证人脸识别的准确率
在做人脸识别任务时,常常会用ROC曲线、CMC曲线作为实验性能指标。根据以下绘图结果以及实时测试,该人脸识别实时系统的识别精度为98.72%,由于个人PC配置问题,实时视频后期会出现卡顿现象。
ROC曲线
相关定义
ROC(Receiver Operating Characteristic)曲线,以及AUC(Area Under Curve),常用来评价一个二值分类器的优劣,ROC的横轴为false positive rate,FPR,也就是实例是负类被预测为正类的比例;纵轴是true positive rate,TPR, 也就是实例是正类被预测为正类的比例。
AUC被定义为时ROC曲线下的面积,可用于评价模型性能,AUC值越接近于1,表示模型越好。
曲线绘制
1.Labeled Faces in the Wild, LFW
在开源的facenet源码中,给出了针对LFW数据的ROC计算代码,代码相关解释可参考博客,而后通过调用lfw数据集的路径以及对应的pairs.txt文件即可绘制出ROC曲线,结果如下:
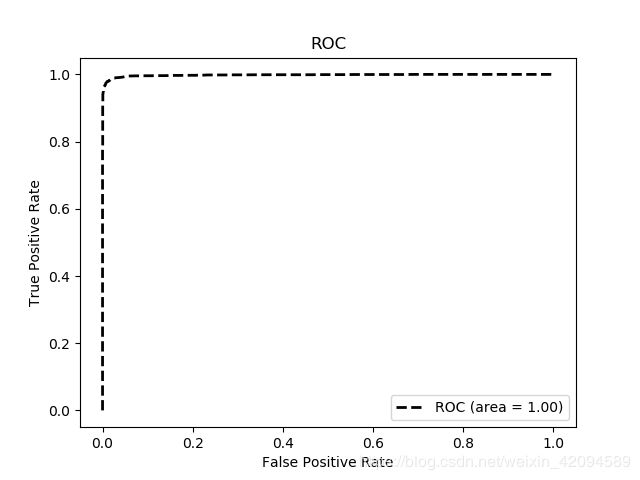
|
呃。。。。
2 绘制其他数据集,比如 AT&T “The Database of Faces”
Facenet源码中对ROC的计算时针对LFW数据集的,要想使用其他数据集,就必须自己造pairs.txt文件。这里选用了att_face数据集,制作其pairs.txt格式文件步骤如下:
首先是Facenet源码中的pairs.txt格式文件解读:
|
|
数据集中的样本图片格式及名称的修改:
att_face数据集数据集中的图片格式是.pgm格式,将其转化成.jpg格式,并将每张图片路径存为…/s1/s1_0001.jpg格式。实现代码如下
def batch_image(in_dir, out_dir):
if not os.path.exists(out_dir):
print(out_dir, 'is not existed.')
os.mkdir(out_dir)
if not os.path.exists(in_dir):
print(in_dir, 'is not existed.')
return -1
count = 0
for dir in os.listdir(in_dir):
path = os.path.join(in_dir,dir)
for files in glob.glob(path + '/*'):
#返回路径基名和路径目录名
filepath, filename = os.path.split(files)
out_file = dir + '_000'+ re.findall(r'\d+',filename[0:9])[0] + '.jpg'
im = Image.open(files)
new_path1 = out_dir + '\\'+ dir
if not os.path.exists(new_path1):
print(new_path1, 'is not existed.')
os.mkdir(new_path1)
new_path = os.path.join(new_path1, out_file)
print(count, ',', new_path)
count = count + 1
im.save(new_path)
if __name__ == '__main__':
indir = r'E:\WorkSpace\PycharmProject\face_recognition_system\ROC_PLOT\Data_Transfer\att_faces'
outdir = r'E:\WorkSpace\PycharmProject\face_recognition_system\ROC_PLOT\Data_Transfer\dataset'
batch_image(indir, outdir)
生成数据集对应的pairs.txt:
import os
import random
dataset_path = "E:/WorkSpace/PycharmProject/face_recognition_system/ROC_PLOT/Data_Transfer/s_data/"
pairs_generate_path = "E:/WorkSpace/PycharmProject/face_recognition_system/ROC_PLOT/Data_Transfer/pairs.txt"
# Make all matches
for name in os.listdir(dataset_path):
a = []
for file in os.listdir(dataset_path + name):
a.append(file)
with open(pairs_generate_path, "a") as f:
for i in range(5):
temp = random.choice(a).split("_") #根据自己图片的命名格式更改这行代码
w = temp[0] + "_" + temp[1]
f.write(temp[0] + "\t" + random.choice(a).split("_")[1].lstrip("0").rstrip(".jpg") + "\t" + random.choice(a).split("_")[1].lstrip("0").rstrip(".jpg") + "\n")
# Make all mismatches
for i,name in enumerate(os.listdir(dataset_path)):
remaining = os.listdir(dataset_path)
del remaining[i] # 删除对应索引的元素,以免重复选取
other_dir = random.choice(remaining)
with open(pairs_generate_path,"a") as f:
for i in range(5):
file1 = random.choice(os.listdir(dataset_path + name))
file2 = random.choice(os.listdir(dataset_path + other_dir))
f.write(name + "\t" + file1.split("_")[1].lstrip("0").rstrip(".jpg") + "\t"
+ other_dir + "\t" + file2.split("_")[1].lstrip("0").rstrip(".jpg") + "\n")
3 针对自己构建的分类器模型,测试任意数据集的ROC曲线
本次人脸识别过程中构建了SVM线性分类器对录入人脸类别进行了42个分类,以提供识别,后期亦可添加。多分类下的ROC曲线的绘制有别于二分类,详情参考了博客。绘制结果如下,从结果可以看出,精度还是相当高的,但是若每个类别下的人脸图像数据过少,识别精度就很有可能急剧下降。
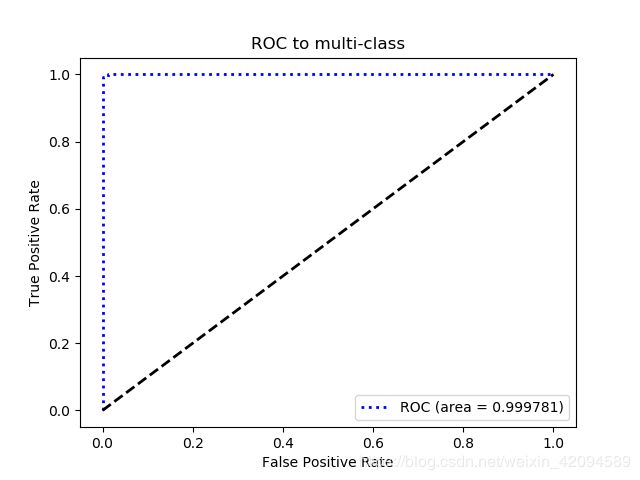
|
CMC曲线
相关定义
全称为Cumulative Match Characteristic Curve, 也就是累积匹配曲线。其评价指标与DL中常用的top error1评价指标一样的意思,区别在于横坐标Rank表示正确率而不是错误率(Rank1识别率 = 1 - top1 err), 更多不再解释,网上有很多这里举个例子:
我们训练了一个分类器,来识别五个物体,即1,2,3,4,5,他们属于三类即A,B,C。经过分类预测,如果物体1,2为一次就命中,3,4为两次才能命中,5为三次命中,则rank1为40%、rank2为80%、rank3为100%。
曲线绘制
Python下实现CMC曲线绘制的教程还是比较少的,这里给出实现代码:
# -*- coding: utf-8 -*-
from sklearn.externals import joblib
import matplotlib.pyplot as plt
import train
import numpy as np
from sklearn.preprocessing import label_binarize
# CMC曲线
# 需要提供confidence_values和y_test这两个变量
X_test = train.X_test
y_test_ = train.y_test
model = joblib.load('./models/svm_classifier.model')
# 得到每个样本在每个标签下的置信值,返回的confidence_values为模型预测得到的匹配置信分数矩阵
confidence_values = model.decision_function(X_test)
# 将标签二值化,返回一个one-hot标签矩阵
y_test= label_binarize(y_test_, classes=[i for i in range(42)])
# 保存accuracy,记录rank1到rank42的准确率
test_cmc = []
# y_test为测试样本的真实标签矩阵;返回每行真实标签相对应的最大值的索引值
actual_index = np.argmax(y_test,1)
#返回每行预测标签相对应的最大值的索引值
predict_index = np.argmax(confidence_values,1)
# 若为1代表相同,一次命中;0代表不同,第一次猜测并未命中
temp = np.cast['float32'](np.equal(actual_index,predict_index))
# rank1
test_cmc.append(np.mean(temp))
# 按行降序排序,返回匹配分数值从大到小的索引值
sort_index = np.argsort(-confidence_values,axis=1)
# rank2到rank42
for i in range(sort_index.shape[1]-1):
for j in range(len(temp)):
if temp[j]==0:
predict_index[j] = sort_index[j][i+1]
temp = np.cast['float32'](np.equal(actual_index,predict_index))
test_cmc.append(np.mean(temp))
#创建绘图对象
plt.figure()
x = np.arange(0,sort_index.shape[1])
plt.plot(x,test_cmc,color="red",linewidth=2)
plt.xlabel("Rank")
plt.ylabel("Matching Rate")
plt.legend()
plt.title("CMC Curve")
plt.show()
绘制曲线结果如下:
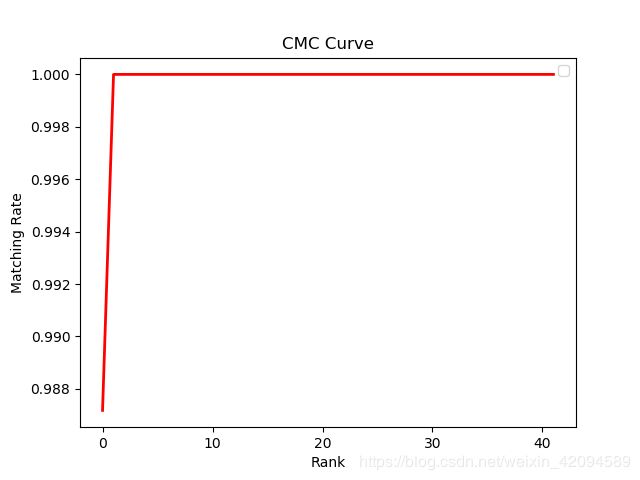
|
其他参考
- facenet源码解析:Triplet Los
https://zhuanlan.zhihu.com/p/38341541 - facenet入门程序:里边包括很多对facenet源码的解读
https://github.com/boyliwensheng/understand_facenet - pairs.txt文件结构
http://vis-www.cs.umass.edu/lfw/README.txt