python机器学习---监督学习---决策树和随机森林(用于分类和回归)
目录
1、决策树
1.1决策树的基本原理
1.2 决策树的优势和不足
2、随机森林
2.1随机森林的基本原理
2.2 随机森林的优势和不足
3、实战案例---收入预测案例
备注:本文主要来自于对《深入浅出python机器学习》书籍的学习总结笔记,感兴趣的同学可以购买本书学习,学习的本质就是形成自己的逻辑。
1、决策树
1.1决策树的基本原理


决策树有分类树---对离散变量做的决策树,也有回归树---对连续变量做的决策树。
决策树的数学原理是信息熵,样本的具有一定的集中度(规律) 信息熵就小,样本都是随机的,信息熵就大。
决策树算法参数如下:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
具体参数说明见:https://blog.csdn.net/linzhjbtx/article/details/85722187
1.2 决策树的优势和不足
(1)优势---它很容易就能将模型的决策机制可视化出来(使用graphviz工具),让非专业人士也能看明白;另外,它是对每个样本特征进行单独处理,因此不需要太多的数据预处理。
(2)不足---容易出现过拟合的的情况,为了避免这种不足,可以采用集合学习的方法,也就是将要介绍的随机森林算法。
2、随机森林
2.1随机森林的基本原理
随机森林是利用随机的方式将许多决策树组合成一个森林,每棵树的参数都不相同,然后在把每棵树预测的结果取平均值,这样即可以保留决策树们的工作成效,又可以降低过拟合的风险。它是一种结合算法,在机器学习中有很多集合算法。

随机森林函数的参数以及方法
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
具体参数说明见:https://blog.csdn.net/w952470866/article/details/78987265
随机森林可以用于分类和回归,是现在应用最广泛的方法之一。
2.2 随机森林的优势和不足
(1)优势---随机森林集成的决策树的所有优点(决策机制易解释,不需要太多数据处理),又能弥补决策树的不足(过拟合的问题);
(2)对于超大数据集比较耗时间,因为要建立很多决策树,可以用多进程并行处理的方式来解决这个问题,实现方式是调节n_jobs参数。
3、实战案例---收入预测案例
网上有一个著名数据集---成年人数据集,包括了数万条样本数据,下载地址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/,下载下来的是.data文件,修改成.csv即可用excel打开。数据中没有列名,可以再下载adult.name文件查看。

##1-数据准备
#1.1导入数据
#用pandas打开csv文件
import pandas as pd
data=pd.read_csv(r'/Users/Eric/Documents/2019/learning/Python机器学习/adult.csv', header=None,encoding="gbk",
names=['年龄','单位性质','权重','学历','受教育时长',
'婚姻状况','职业','家庭情况','种族','性别',
'资产所得','资产损失','周工作时长','原籍',
'收入'])
#查看字段信息
data.head(5)
#为了方便展示,我们选取其中一部分数据
data2 = data[['年龄','单位性质','学历','性别','周工作时长',
'职业','收入']]
#利用shape方法获取数据集的大小
data2.shape![]()

##1-数据准备
#1.2 数据预处理
#用get_dummies将文本数据转化为数值
data_dummies=pd.get_dummies(data2)
#对比样本原始特征和虚拟变量特征---df.columns获取表头
print('样本原始特征:\n',list(data2.columns),'\n')
print('虚拟变量特征:\n',list(data_dummies.columns))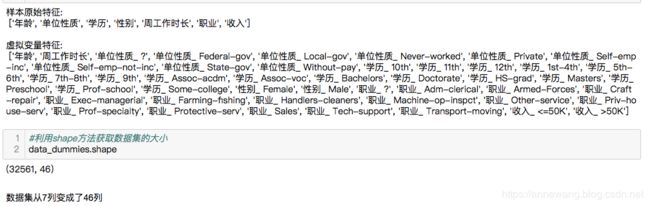
##1-数据准备---导入数据/数据处理/选择特征
#1.3 选择特征
#按位置选择---位置索引---df.iloc[[行1,行2],[列1,列2]]---行列位置从0开始,多行多列用逗号隔开,用:表示全部(不需要[])
#选择除了收入外的字段作为数值特征并赋值给x---df[].values
x=data_dummies.loc[:,'年龄':'职业_ Transport-moving'].values
#将'收入_ >50K'‘作为预测目标y
y = data_dummies['收入_ >50K'].values
#查看x,y数据集大小情况
print('特征形态:{} 标签形态:{}'.format(x.shape, y.shape))![]()
##2-数据建模---拆分数据集/模型训练/测试
#2.1将数据拆分为训练集和测试集---要用train_test_split模块中的train_test_split()函数,随机将75%数据化道训练集,25%数据到测试集
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#拆分数据集---x,y都要拆分,rain_test_split(x,y,random_state=0),random_state=0使得每次生成的伪随机数不同
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)
#查看拆分后的数据集大小情况
print('x_train_shape:{}'.format(x_train.shape))
print('x_test_shape:{}'.format(x_test.shape))
print('y_train_shape:{}'.format(y_train.shape))
print('y_test_shape:{}'.format(y_test.shape))
##2、数据建模---模型训练/测试---决策树算法
#2.2 模型训练---算法.fit(x_train,y_train)
#导入算法包
from sklearn.tree import DecisionTreeClassifier
#使用算法
tree = DecisionTreeClassifier(max_depth=5) #这里参数max_depth最大深度设置为5
#算法.fit(x,y)对训练数据进行拟合
tree.fit(x_train, y_train)
##2、数据建模---拆分数据集/模型训练/测试---决策树算法
#2.3 模型测试---算法.score(x_test,y_test)
score_test=tree.score(x_test,y_test)
score_train=tree.score(x_train,y_train)
print('test_score:{:.2%}'.format(score_test))
print('train_score:{:.2%}'.format(score_train))![]()
##3、模型应用---算法.predict(x_new)---决策树算法
#导入要预测数据--可以输入新的数据点,也可以随便取原数据集中某一数据点,但是注意要与原数据结构相同
x_new=[[37, 40,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,1,0,1,
0,0,0,0,0,0,0,0,0,0,0,0,0]] #37岁,机关工作,硕士,男,每周工作40小时,文员
#模型应用
prediction=tree.predict(x_new)
print('预测数据:{}'.format(x_new))
print('预测结果:{}'.format(prediction))![]()
下面是随机森林算法:

