Tensorflow实现自编码器AutoEncoder
@
Tensorflow实现自编码器AutoEncoder
自编码器,就是可以使用自身的高阶特征编码自己,本质上也是一种神经网络,输入和输出是一致的。
特点:(1)期望输入/输出一致的
(2)使用高阶特征来重构自己,而不是复制像素点
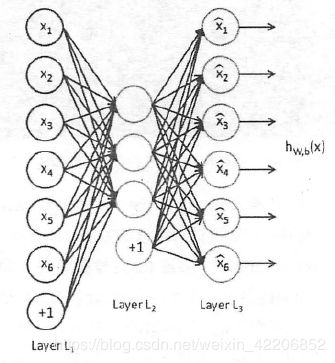
当hidden_layers = 1 相当于PCA
当bidden_layers有多个时,每一个隐含层都是受限玻尔兹曼机(RBM)
代码如下:
#-*- coding:utf-8 -*-
import numpy as np
import os
import sklearn.preprocessing as prep
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
#这里用到的是一种参数初始化方法xavier_initialization.
#在Yoshua Bengio 的一篇文章中指出,如果深度学习模型的权重初始化设置的太小,那么信号在每层间传递就会逐渐缩小而难以产生作用;如果设置的太大,那信号在每层之间传递逐渐放大并导致发散或失效。
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
high = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),minval = low,maxval = high,dtype = tf.float32)
def plot_image(image):
plt.imshow(image.reshape((28,28)),interpolation='nearest',cmap='binary')
plt.show()
#下面是去噪自编码器的class,方便后面使用
class AdditiveGaussianAutoencoder(object):
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,optimizer=tf.train.AdamOptimizer(),scale=1.0):
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function
self.scale = tf.placeholder(tf.float32)
self.training_scale = scale
network_weights = self._initalize_weights()
self.weights = network_weights
# 定义网络结构
self.x = tf.placeholder(tf.float32,[None,self.n_input]) # 输入层
self.noisex = self.x+scale*tf.random_normal((n_input,)) # 加入噪声的输入图像
# 下面是给输入的数据加入了噪声
self.hidden = self.transfer(tf.add(tf.matmul(self.noisex,self.weights['w1']),self.weights['b1']))
# 上一行是隐含层
# 输出层
self.reconstruction = tf.add(tf.matmul(self.hidden,self.weights['w2']),self.weights['b2'])
# 定义自编码器的损失函数,这里使用平方误差作为cost
self.cost = 0.5*tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction,self.x),2.0))
self.optimizer = optimizer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init)
# 编写成员函数
def _initalize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input,self.n_hidden))
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden],dtype=tf.float32))
all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden,self.n_input],dtype=tf.float32)) # 输出神经元数和输入一样
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input],dtype = tf.float32))
return all_weights
# 定义计算损失cost以及执行一步训练的函数
def partial_fit(self,X):
cost,opt = self.sess.run((self.cost,self.optimizer),feed_dict={self.x:X,self.scale:self.training_scale})
return cost
#
def calc_total_cost(self,X):
return self.sess.run(self.cost,feed_dict={self.x:X,self.scale:self.training_scale})
# 定义transform函数,返回隐含层的结果
def transform(self,X):
return self.sess.run(self.hidden,feed_dict={self.x:X,self.scale:self.training_scale})
# 定义generate()函数
def generate(self,hidden=None):
if hidden:
hidden = np.random.normal(size=self.weights["b1"])
return self.sess.run(self.reconstruction,feed_dict={self.hidden:hidden})
def reconstrdata(self,X):
return self.sess.run(self.reconstruction,feed_dict={self.x:X,self.scale:self.training_scale})
# 获取隐含层的权重w1
def getWeights(self):
return self.sess.run(self.weights["w1"])
# 获取隐含层的偏置系数b1
def getBiases(self):
return self.sess.run(self.weights['b1'])
# 可视化对比原输入图像和加入噪声后的图像
def plot_noiseimg(self,img,show_comp=True):
self.noise = self.sess.run(tf.random_normal((self.n_input,)))
noiseimg = img + self.training_scale*self.noise
plot_image(noiseimg)
if show_comp:
plt.subplot(121)
plt.imshow(img.reshape((28, 28)), interpolation='nearest', cmap='binary')
plt.subplot(122)
plot_image(noiseimg)
# 定义一个对训练、测试数据进行标准化(0均值,且标准差为1的分布)处理的函数。
def standard_scale(X_train,X_test):
preprocessor = prep.StandardScaler().fit(X_train) # 这句是保证训练、测试数据都使用完全相同Scalar
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train,X_test
def get_random_block_from_data(data,batch_size):
start_index = np.random.randint(0,len(data)-batch_size)
return data[start_index:(start_index+batch_size)]
if __name__ == '__main__':
mnist = input_data.read_data_sets("C:\\Users\ADMIN\\Desktop\\shuju", one_hot=True)
X_train,X_test = standard_scale(mnist.train.images,mnist.test.images)
n_samples = int(mnist.train.num_examples)
training_epochs = 20
batch_size = 128
display_step = 1
image0 = mnist.train.images[2]
#img = X_train[2]
# scale是噪声系数
autoencoder =AdditiveGaussianAutoencoder(n_input=784,
n_hidden=200,
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.1)
#plot_image(img)
autoencoder.plot_noiseimg(image0)
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(n_samples/batch_size)
for i in range(total_batch):
batch_xs = get_random_block_from_data(X_train,batch_size)
cost = autoencoder.partial_fit(batch_xs)
#output = autoencoder.reconstrdata(batch_xs)
avg_cost += cost/n_samples*batch_size
if epoch % display_step == 0:
print("Epoch:",'%04d'%(epoch+1),"cost=","{:.9f}".format(avg_cost))
#print(output)
#with tf.Session() as sess:
# sess.run(tf.global_variables_initializer())
# afterimg = autoencoder.reconstruction(image0)
# plot_image(afterimg)
#print(autoencoder.reconstrdata(X_train))
reimg = autoencoder.reconstrdata(X_train)[2]
plot_image(reimg)
print("Total cost:"+str(autoencoder.calc_total_cost(X_test)))
实验结果
Epoch: 0001 cost= 18884.709260227
Epoch: 0002 cost= 12666.596769318
Epoch: 0003 cost= 11025.238650000
Epoch: 0004 cost= 10303.450009091
Epoch: 0005 cost= 10488.024457955
Epoch: 0006 cost= 9462.400169886
Epoch: 0007 cost= 9524.137480682
Epoch: 0008 cost= 9412.738680682
Epoch: 0009 cost= 8626.502057386
Epoch: 0010 cost= 8315.852368182
Epoch: 0011 cost= 8844.221456818
Epoch: 0012 cost= 9342.149281250
Epoch: 0013 cost= 8691.658151136
Epoch: 0014 cost= 8302.021069886
Epoch: 0015 cost= 8067.476687500
Epoch: 0016 cost= 8872.686853409
Epoch: 0017 cost= 8055.707444886
Epoch: 0018 cost= 7852.056722727
Epoch: 0019 cost= 8187.902400568
Epoch: 0020 cost= 8065.570531818
注意事项:(1)报错: runfile(‘C:/Users/ADMIN/Desktop/auto.py’, wdir=‘C:/Users/ADMIN/Desktop’)
File “C:/Users/ADMIN/Desktop/auto.py”, line 117
mnist = input_data.read_data_sets(“C:\Users\ADMIN\Desktop\shuju”, one_hot=True)
^
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
说明路径错误;
修改:mnist = input_data.read_data_sets(“C:\Users\ADMIN\Desktop\shuju”, one_hot=True)
注意是‘\’