AIML框架标签详解
文章目录
- AIML框架--->分词
- 中文分词库-Jieba
- 中英文分词的方式
- 全模式分词
- 精确模式分词
- 搜索模式
- AIML框架--->基本标签
- 小试牛刀
- 基本标签
- star标签
- random标签
- srai标签
- set和get标签
- that标签
- topic标签
- think标签
- condition标签
前言:
之前有写过关于 AIML初探的文章,
链接: https://blog.csdn.net/weixin_42250835/article/details/86766776
AIML框架—>分词
中文分词库-Jieba
安装Jieba中文分词库:pip install jieba / pip3 install jieba (全自动安装)
目前 Jieba 是几个主流的中文分词库之一,下面是几个主流的分词工具包
分词工具 词库中词的数量 最后更新时间
| 分词工具 | 词库中词的数量 | 最后更新时间 |
|---|---|---|
| jieba | 16.6万 | 2015年 |
| IK | 27.5万 | 2012年 |
| mmseg | 15万 | 2014年 |
| word | 64.2万 | 2015年 |
以上分词工具、词库中词的数量、最后更新时间 信息来自网络搜集。
中英文分词的方式
my name is Fiarter: my name is Fiarter
我的名字是张三: 我 的 名字 是 张三
以上的中英文分词特点,我们可以看到中文分词与英文分词有很大的不同,对英文而言,一个单词就是一个词,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,需要人为的切分才可以达到中文分词的目的。
在NLP中,分词是一块比较大的知识要点,自然语言处理汉语的时候,中文分词技术是相当重要的,这里关于分词技术不做太多深入的详解,先带大家初步了解分词,形成一种简单直观的分词感觉。
jieba 支持三种分词模式:全模式、精确模式、搜索模式。
全模式:将句子中所有的可能成词的词语都扫描出来,速度非常快,但是不能解决歧义。
精确模式:试图将句子最精确地切开,适合文本分析。
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。
全模式分词
使用全模式分词需要添加 cut_all 参数,将其设置为 True,代码如下:
import jieba #导入jieba
#全模式
while True:
my_in = input("") #input手动输入的内容,赋值给变量 my_in
s = jieba.cut(my_in,cut_all = True) #input手动输入的内容,通过jieba.cut函数调用,匹配cut_all全模式
z = " ".join(s) #使用空格把 jieba 分词的结果区分开。" ":引号中就是普通的字符串
print(z) #输出 分词 的结果
#例句:早上吃了一个茶叶蛋
#分词结果:早上 吃 了 一个 茶叶 茶叶蛋
精确模式分词
精确模式分词,默认情况下使用精确模式。同样的也可使用cut()方法进行精确模式分词的操作,cut()方法的参数改为 False 即可。代码如下:
#精确模式
while True:
my_in = input("")
#s = jieba.cut(my_in) #默认的情况下使用的就是精确模式
s = jieba.cut(my_in,cut_all = False)
z = " ".join(s)
print(z)
#例句:早上吃了一个茶叶蛋
#分词结果:早上 吃 了 一个 茶叶蛋
搜索模式
使用搜索引擎模式分词需要调用 cut_for_search() 方法,代码如下:
#搜索模式(也叫‘搜索引擎模式’)
while True:
my_in = input("")
s = jieba.cut_for_search(my_in)
z = " ".join(s)
print(z)
#例句:早上吃了一个茶叶蛋
#分词结果:早上 吃 了 一个 茶叶 茶叶蛋
AIML框架—>基本标签
小试牛刀
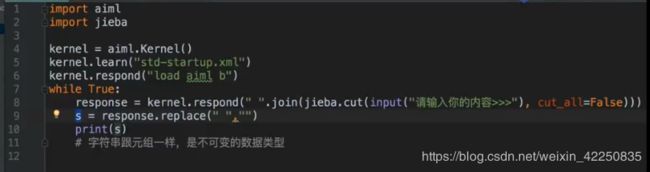
“Project”下新建一个 aiml_main.py 文件,代码如下:
import aiml
import jieba
kernel = aiml.Kernel()
kernel.learn("std-startup.xml")
kernel.respond("load aiml b")
while True:
print(kernel.respond(" ".join(jieba.cut_for_search(input("请输入你的内容>>>")))))
new —> file —> std-startup.xml 创建 “std-startup.xml”文件,代码如下:
<aiml version="1.0.1" encoding="UTF-8">
<category>
<pattern>我 老 了pattern>
<template>
好像是的
template>>
category>
aiml>
运行 aiml_main

基本标签
附:可以理解为所有的对话都由category组成
附:其实就是问题
: 定义机器人对用户输入的响应
附:其实就是机器人对用户的回答
举例:
<aiml version="1.0.1" encoding="UTF-8">
<category>
<pattern>HELLOpattern>
<template>Hello Usertemplate>
category>
aiml>
star标签
使用方法
附:这样说可能不是很直观,我们结合下面的代码来看一下
<category>
<pattern>一个 * 是 一种 * 吗pattern>
<template>
第一个参数值是<star index="1"/>,第二个参数值是<star index="2">
template>
category>
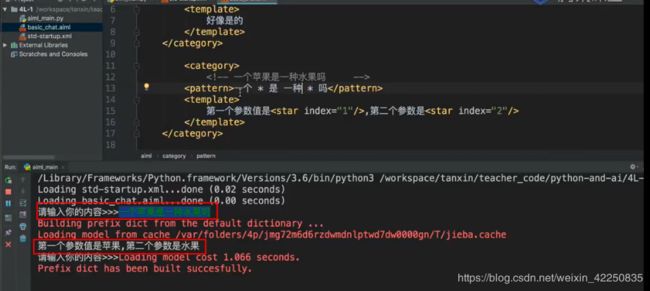
第一个 * 对应的是苹果,第二个行对应的是水果。
附:也可以通过正则表达式这样理解,* 匹配的是苹果和水果。
random标签
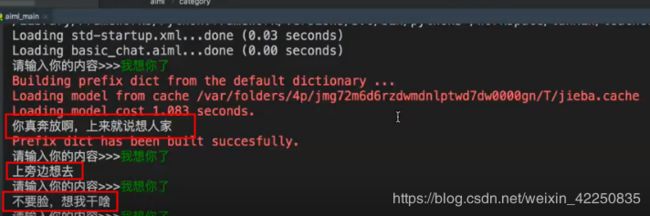
用于获取随机响应。此标记使AIML能够针对相同的输入做出不同的响应。
代码实例:
<category>
<pattern>我 想 你 了pattern>
<template>
<li>我也想你了li>
<li>不要脸,想我干啥li>
<li>你真奔放啊,上来就说想人家li>
<li>上旁边想去li>
template>
category>
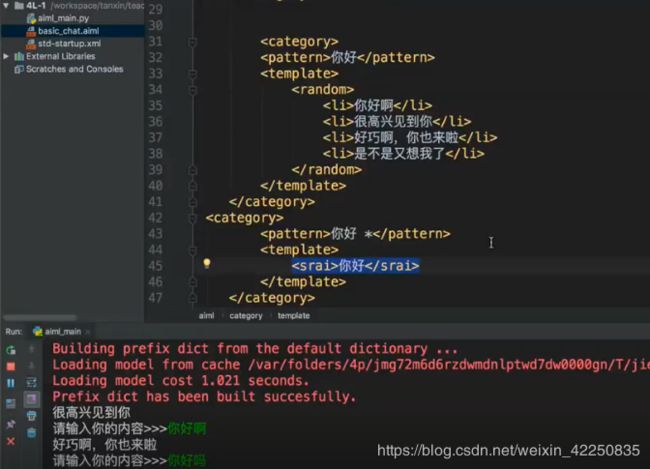
srai标签
有很多时候,我们提出一系列的问题,但实际上只需要统一的回答,这个时候
<category>
<pattern>你好 *pattern>
<template>
<srai>你好srai>
template>
category>
<category>
<pattern>你好pattern>
<template>
<li>你好啊li>
<li>很高兴见到你li>
<li>好巧啊,你也来啦li>
<li>是不是又想我了li>
template>
category>

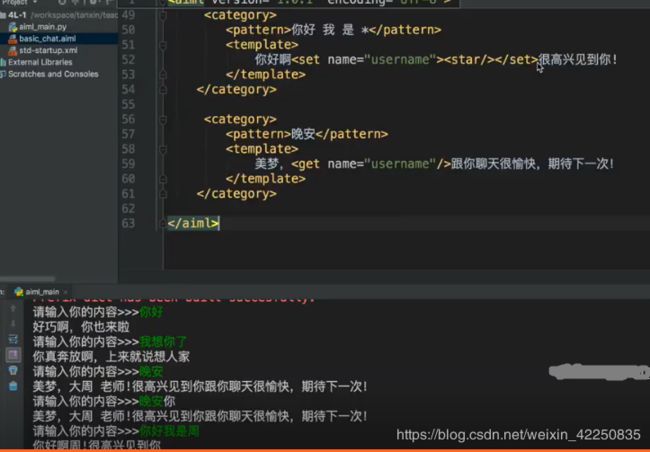
set和get标签
示例:
示例:
<category>
<pattern>你好 我 是 *pattern>
<template>
你好啊<set name="username"><star/>set>很高兴见到你
template>
category>
<category>
<pattern>晚安pattern>
<template>
美梦,<get name="username"/>跟你聊天很愉快,期待下一次!
template>
category>
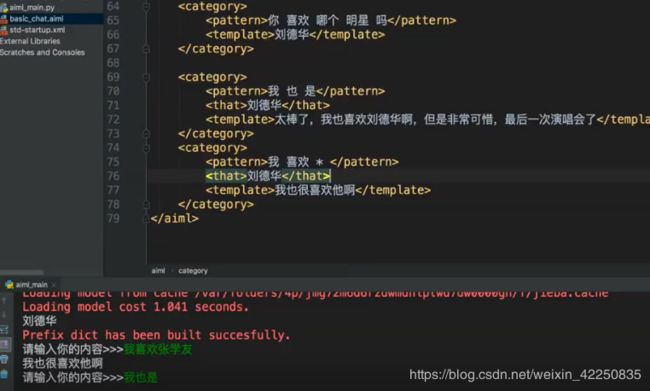
that标签
实例:
<category>
<pattern>你 喜欢 哪个 明星 吗pattern>
<template>刘德华template>
category>
<category>
<pattern>我 也 是pattern>
<that>刘德华that>
<template>太棒了,我也喜欢刘德华啊template>
category>
<category>
<pattern>我 喜欢 * pattern>
<that>刘德华that>
<template>我也很喜欢他啊template>
category>
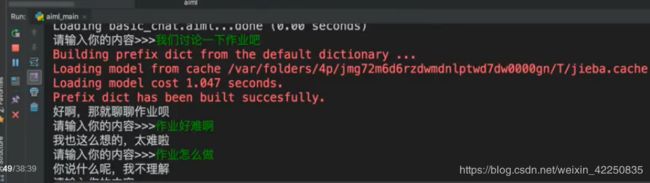
topic标签
1、使用
<template>
<set name="topic">topic-nameset>
template>
2、使用
<topic name="topic-name">
<category>...category>
topic>
实例:
<category>
<pattern>我们 讨论一下 作业 吧pattern>
<template>好啊,那就聊聊<set name="topic">作业set>呗template>
category>
<topic name="作业">
<category>
<pattern>好难 啊pattern>
<template>作业真是难,我也这么想的,太难啦template>
category>
<category>
<pattern>作业 怎么 做pattern>
<template>你说什么呢?我不太理解template>
category>
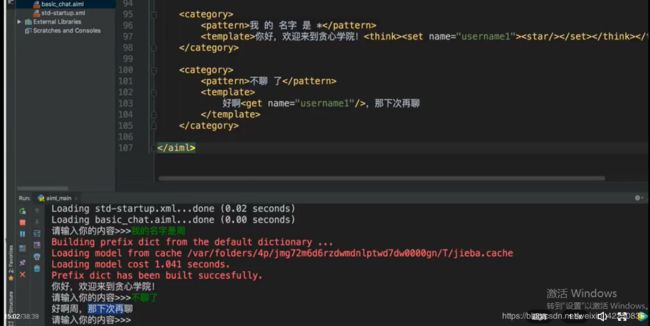
think标签
实例:
<category>
<pattern>我的 名字 是 *pattern>
<template>你好,欢迎来到贪心学院!<think><set name="username1">set>think>template>
category>
<category>
<pattern>不聊 了pattern>
<template>
好啊,<get name="username1"/>,那下次聊。
template>
category>
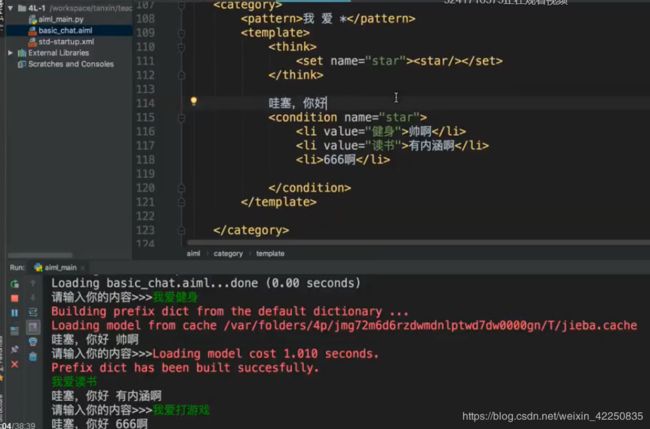
condition标签
实例:
<category>
<pattern>我 爱 *pattern>
<template>
<think>
<set name="star"><star/>set>
think>
哇塞,你好
<condition name="star">
<li value="健身">帅啊li>
<li value="读书">有内涵啊li>
<li>666啊li>
<condition>
template>
category>