python一行代码实现百度翻译和有道翻译结果获取-----py学习爬虫历程(一)
更新(18-6-2):利用requests库只需一行代码就可以获取结果,代码在最后
前言:本文参考于https://blog.csdn.net/c406495762/article/details/59095864
一.本节主要用到的知识
1-1:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)¶
1-2 :
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)¶
1-3:
urllib.parse.urlencode()
二.正文
2-1:用微软edge浏览器的审查元素提取出有道翻译接口地址
1. 找到post类型的方法(简单来说,get是服务器向你发送数据,post是你向服务器提交信息)
2. 可以右下角标头看到请求url:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule复制下来
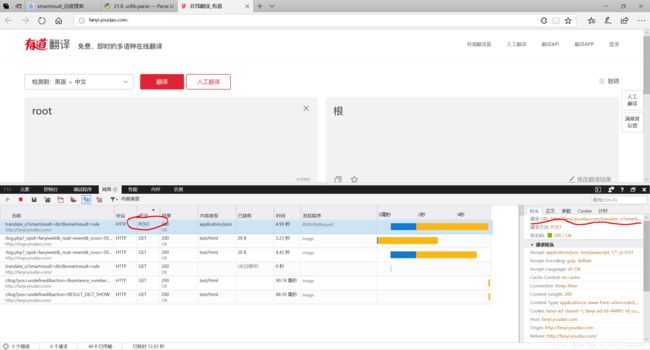
2-2:创建提交的数据格式
在响应正文里可以看到服务器向我们返回的结果,是一个json格式的信息。要想知道我们刚才在点击翻译时向服务器提交的数据,我们需要打开请求正文,那些就是我们向服务器提交的数据,但是这些数据不能直接向服务器提交,需要转化为服务器可以处理的编码方式,这里就要用到urllib.parse.urlencode()方法。


3-3:实战
大致思路如下:
1. 创建连接接口
2. 创建要提交的数据
3. 将数据转化为服务器可以处理的信息并提交
4. 返回翻译结果
代码实现如下:
# 有道翻译结果获取from urllib import request, parse
import json
if __name__ == '__main__':
req_url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' # 创建连接接口
# 创建要提交的数据
Form_Date = {}
Form_Date['i'] = 'i love you'
Form_Date['doctype'] = 'json'
Form_Date['form'] = 'AUTO'
Form_Date['to'] = 'AUTO'
Form_Date['smartresult'] = 'dict'
Form_Date['client'] = 'fanyideskweb'
Form_Date['salt'] = '1526995097962'
Form_Date['sign'] = '8e4c4765b52229e1f3ad2e633af89c76'
Form_Date['version'] = '2.1'
Form_Date['keyform'] = 'fanyi.web'
Form_Date['action'] = 'FY_BY_REALTIME'
Form_Date['typoResult'] = 'false'
data = parse.urlencode(Form_Date).encode('utf-8') # 数据转换
response = request.urlopen(req_url, data) # 提交数据并解析
html = response.read().decode('utf-8') # 服务器返回结果读取
print(html)
# 可以看出html是一个json格式
translate_results = json.loads(html) # 以json格式载入
translate_results = translate_results['translateResult'][0][0]['tgt'] # json格式调取
print(translate_results) # 输出结果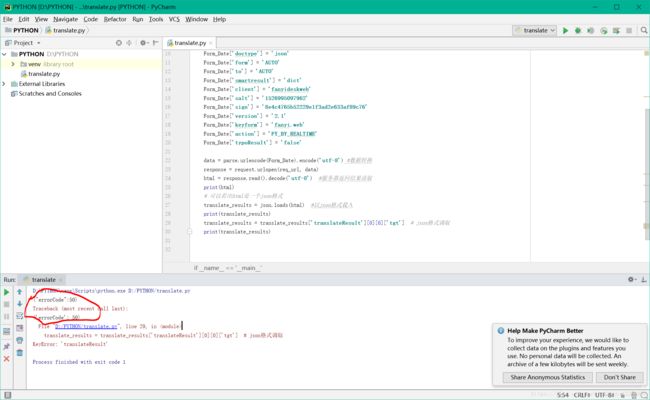
运行之后发现出现“errorCode:50”(或者是“error:997”),百度了一波发现是连接接口有问题(凡事多百度),于是将连接改为:http://fanyi.youdao.com/translate,这才是有道翻译的真正接口,再次运行,出结果。
# 有道翻译结果获取
from urllib import request, parse
import json
if __name__ == '__main__':
req_url = 'http://fanyi.youdao.com/translate' # 创建连接接口
# 创建要提交的数据
Form_Date = {}
Form_Date['i'] = 'i love you'
Form_Date['doctype'] = 'json'
Form_Date['form'] = 'AUTO'
Form_Date['to'] = 'AUTO'
Form_Date['smartresult'] = 'dict'
Form_Date['client'] = 'fanyideskweb'
Form_Date['salt'] = '1526995097962'
Form_Date['sign'] = '8e4c4765b52229e1f3ad2e633af89c76'
Form_Date['version'] = '2.1'
Form_Date['keyform'] = 'fanyi.web'
Form_Date['action'] = 'FY_BY_REALTIME'
Form_Date['typoResult'] = 'false'
data = parse.urlencode(Form_Date).encode('utf-8') #数据转换
response = request.urlopen(req_url, data) #提交数据并解析
html = response.read().decode('utf-8') #服务器返回结果读取
print(html)
# 可以看出html是一个json格式
translate_results = json.loads(html) #以json格式载入
translate_results = translate_results['translateResult'][0][0]['tgt'] # json格式调取
print(translate_results) #输出结果
# 有道翻译结果获取
from urllib import request, parse
import json
if __name__ == '__main__':
req_url = 'http://fanyi.youdao.com/translate' # 创建连接接口
# 创建要提交的数据
Form_Date = {}
Form_Date['i'] = 'i love you' # 要翻译的内容可以更改
Form_Date['doctype'] = 'json'
data = parse.urlencode(Form_Date).encode('utf-8') #数据转换
response = request.urlopen(req_url, data) #提交数据并解析
html = response.read().decode('utf-8') #服务器返回结果读取
print(html)
# 可以看出html是一个json格式
translate_results = json.loads(html) #以json格式载入
translate_results = translate_results['translateResult'][0][0]['tgt'] # json格式调取
print(translate_results) #输出结果
三:获取百度翻译结果
3-1:抓取接口地址
这里百度出现了两个接口地址(有道只有一个),实时翻译的(sug接口)和鼠标点击翻译后的接口(v2transapi接口)地址是不一样的(有道翻译一样),一个是:http://fanyi.baidu.com/sug(经过实践,发现只能翻译英语到汉语),另一个是http://fanyi.baidu.com/v2transapi。
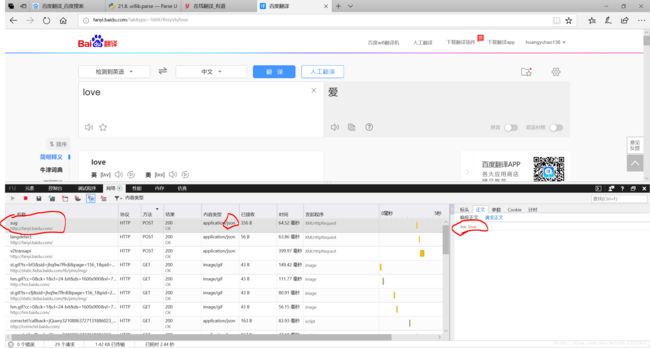

这时可能有的小伙伴会问,为什么同是post类型的http://fanyi.baidu.com/langdetect不可以,我们查看他的响应正文,发现没有我们需要的返回结果,而查看另外两个的响应正文,发现都是以json编码格式的返回结果。

经过上面的有道翻译结果的获取,我们有了一定的经验。
查看v2transapi的请求正文,发现多了个“from”:zh和“to“:en,我们都知道这时zh是中文的缩写,en是英文的缩写,由此我们可以判断这两个数据是我们必须的,而且可以更改取得不同语言的翻译结果。
四:实战:
4-1:
思路和获取有道翻译的一样,代码实现如下(第一个接口):
from urllib import request,parse
import json
if __name__ == '__main__':
#实时翻译的接口,只能翻译英语到汉语
req_url = 'http://fanyi.baidu.com/sug'
Form_Data = {"kw": 'love'}
data = parse.urlencode(Form_Data).encode('utf-8')
response = request.urlopen(req_url,data)
html = response.read().decode('utf-8')
print(html)
#可以看出html是一个json格式
translate_results = json.loads(html)
for item in translate_results['data']:
for items in item:
print(item[items])
from urllib import request,parse
import json
if __name__ == '__main__':
#点击翻译的接口
req_url = 'http://fanyi.baidu.com/v2transapi'
Form_Data = {"query": 'love','from':'en','to':'de'} #英语翻译为德语
data = parse.urlencode(Form_Data).encode('utf-8')
response = request.urlopen(req_url,data)
html = response.read().decode('utf-8')
print(html)
#可以看出html是一个json格式
translate_results = json.loads(html)
translate_results = translate_results['data'][0]['dst']
print(translate_results)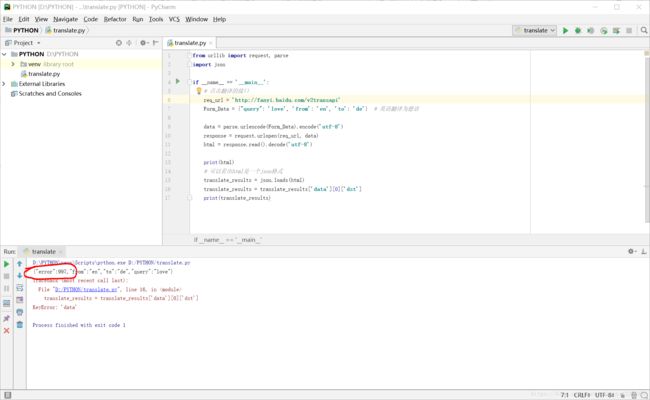
出现error:997,和上面有道翻译错误一样,我们将接口地址改为:
http://fanyi.baidu.com/transapi
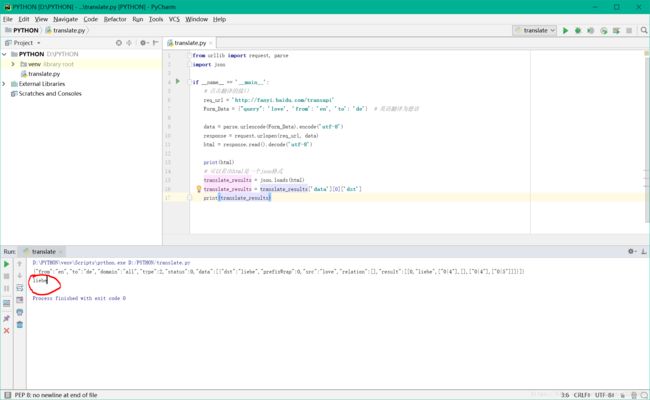
成功运行
更新(18-6-2):
requests库官方文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html

代码如下:
import requests
if __name__ == '__main__':
# 实时翻译的接口,只能翻译英语到汉语
# req_url = 'http://fanyi.baidu.com/sug'
# Form_Data = {"kw": 'love'}
req_url = 'http://fanyi.baidu.com/transapi'
Form_Data = {"query": 'love', 'from': 'en', 'to': 'de'} # 英语翻译为德语
translate_result = requests.post(req_url,Form_Data)
result = translate_result.json() #转化为json格式
print(result['data'][0]['dst'])
#简化为一行代码就是
print(requests.post('http://fanyi.baidu.com/transapi', data={"query": 'love', 'from': 'en', 'to': 'de'}).json()['data'][0]['dst'])