maven工程打包,单节点跑wordcount(一)
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。首先在IDEA上编辑maven工程,在maven工程中的src填写wordcount代码,在xshell上运行(需连接集群结点),因wordcount程序运行需txt文档,因此还涉及在hdfs上的一些基本操作
一、在IDEA上编写maven(WordCount)的spark程序
1.新建maven工程,填写GroupId,ArtifactId(groupid(公司名+人名+项目名)artifactid(项目名),用maven打出的jar包,包名是artifactid中的项目)
2.将下方程序复制在Maven的pom.xml文件中
4.0.0
com.cai
wordcount1
1.0-SNAPSHOT
1.7
1.7
UTF-8
2.10.6
2.10
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.10
1.5.2
org.apache.spark
spark-streaming_2.10
1.5.2
org.apache.hadoop
hadoop-client
2.6.0
src/main/scala
src/test/scala
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
-make:transitive
-dependencyfile
${project.build.directory}/.scala_dependencies
org.apache.maven.plugins
maven-surefire-plugin
2.18.1
false
true
**/*Test.*
**/*Suite.*
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.cch.WordCount.wordcount
注意:配置好pom.xml以后,点击Enable Auto-Import.坑:查看你的hadoop版本(我的是2.6.9)是否与上述pom.xml匹配,相应位置修改。
3.将src/main/java和src/test/java分别修改成src/main/scala和src/test/scala,与pom.xml中的配置保持一致();
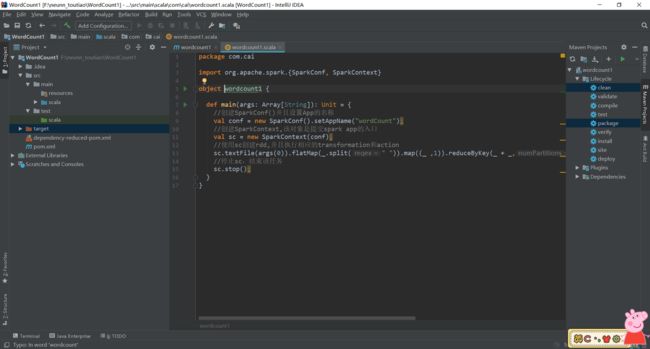
4.使用Maven打包:首先修改pom.xml中的,在此处是否是程序入口,与自己程序对应,本文的程序入口是com.cai.wordcount1。之后点击idea右侧的Maven Project选项,点击Lifecycle,选择clean和package,点击RUN:
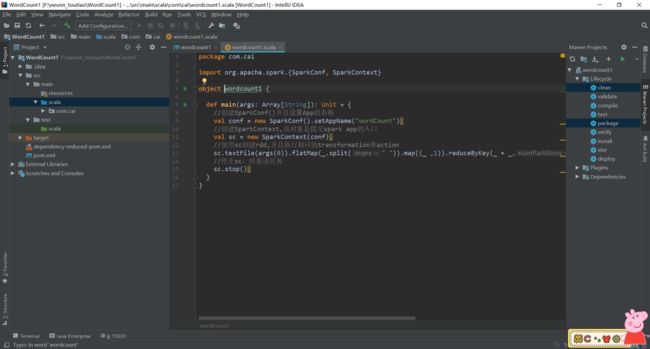
图中的程序就是wordcountspark源码
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf()并且设置App的名称
val conf = new SparkConf().setAppName("wordCount");
//创建SparkContext,该对象是提交spark app的入口
val sc = new SparkContext(conf);
//使用sc创建rdd,并且执行相应的transformation和action
sc.textFile(args(0)).flatMap(_.split(" ")).map((_ ,1)).reduceByKey(_ + _,1).sortBy(_._2,false).saveAsTextFile(args(1));
//停止sc,结束该任务
sc.stop();
}
}
5.等待编译完成后,选择编译成功的jar包,并将改jar上传到Spark集群中的某个节点上,jar包在上方图片左侧target中wordcount1-1.0-SNAPSHOT.jar
二、上传到spark集群,运行程序,需用到xshell、xftp工具(首先在官网下载好)
1.打开Xshell->新建->填写链接的主机地址->新建好后输入用户名和密码,建立连接(通过xshell将你自己的电脑和服务器上的linux系统的电脑链接上)。
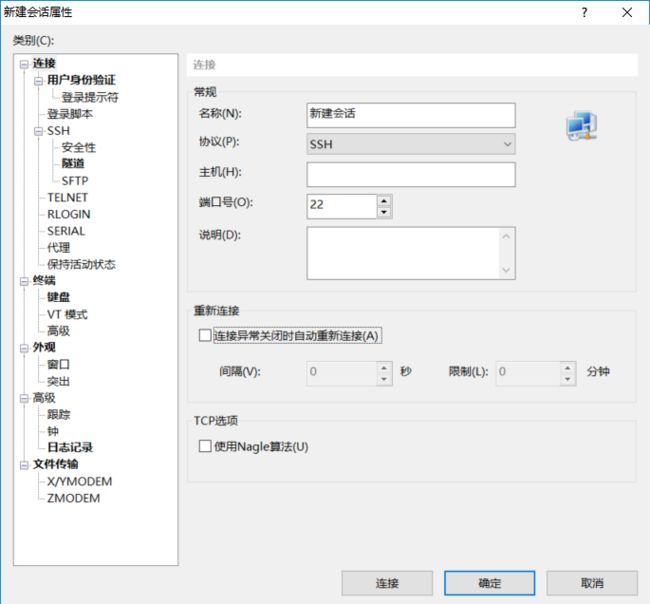
2.使用xftp,xftp是将本地文件传到远程Linux系统的工具,具体如下:将jar包和WordCount.txt,从做向右拖拽至/home/hdfs(自己建的文件夹)即可实现上传到远程Linux系统上。
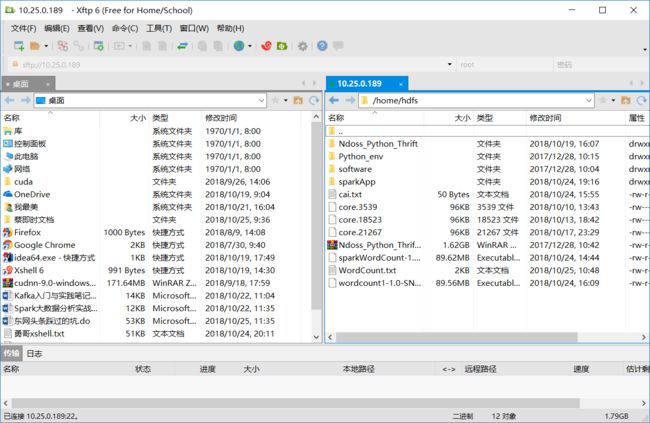
因为我们这个程序需要统计WordCount文档中各个词的词数,提前写好了一个WordCount.txt供程序统计,本文想实现分布式存储,因此需要将WordCount.txt上传到分布式文件存储系统中hdfs,具体代码如下:
[root@data6 ~]# su hdfs //切换成hdfs用户(root用户没有权限)
[hdfs@data6 root]$ cd /home/hdfs/software/hadoop/bin //切换到hadoop中的bin目录下,因为hadoop的bin文件夹是对hdfs操作的接口,这样才可以操作hdfs
[hdfs@data6 bin]$ ./hadoop fs -mkdir /inn //在hdfs系统上创建inn目录,这个系统使我们看不到的
[hdfs@data6 bin]$ ./hadoop fs -ls / //查看创建的目录
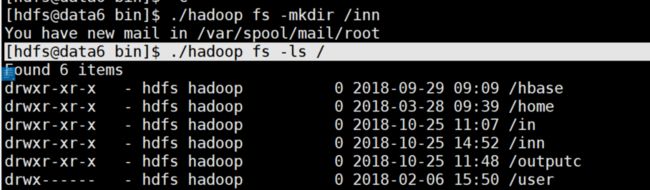
由图片可以看出inn文件夹已经存在在hdfs系统中
[hdfs@data6 bin]$ ./hadoop fs -put /home/hdfs/WordCount.txt /inn //将本地文件夹home中的hdfs中的WordCount.txt文件上传到inn目录下
 现在需要的文档提交完了,那么只需要运行jar包了
现在需要的文档提交完了,那么只需要运行jar包了
jar包在/home/hdfs目录下,因此先将现在的目录回退到个人用户目录下
[hdfs@data6 /]$ cd ~ //通过这个命令,以后的命令行下面就变成了,即变成了[hdfs@data6 ~]$,表示的是hdfs中的个人用户
[hdfs@data6 ~]$ /home/hdfs/software/spark/bin/spark-submit --class com.bie.WordCount sparkWordCount-1.0-SNAPSHOT.jar hdfs://#########:9000/inn/WordCount.txt hdfs://#######:9000/outputc
最后一条命令解释一下:因为在spark集群,因此先进入(spark的bin文件夹中/home/hdfs/software/spark/bin/)+(spark-submit命令)+(–class,这个表示此程序的入口,程序入口为com.bie.WordCount)+(jar包名)
+(WordCount.txt的位置,在我们集群inn文件夹中)+(这里是结果的位置,如果没有,会直接新建个目录outputc),若运行成功,会直接显示下一条命令。
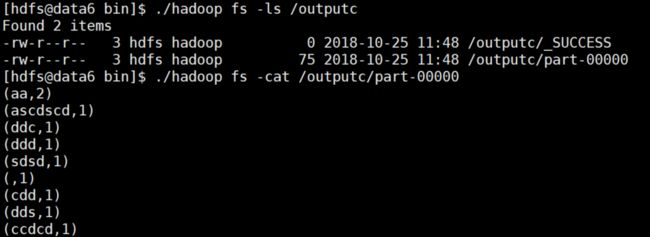
查看结果目录outputc,并查看目录下的part-00000 结果文件内容,大功告成。
原创作品。禁止转载!!!