Python小知识-正则表达式和Re库(一)
原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
1 概述
在爬虫过程中,有时会遇到正则表达式的问题,每次遇到时总会想各种方法去避免、逃避,今天又遇到类似的问题了,决心找个时间好好看一下这块内容,并总结出来。实际上,正则表达式是处理字符串的强大工具,它有自己特定的语法结构,实现字符串的检索、替换、匹配验证都可以实现。 这样,在爬虫中,通过正则表达式,从HTML就可以实现提取信息的目的。那接下来开始正式学习正则表达式喽喽喽…

2 内容详细讲解
既然详细讲解,就要讲到常用的匹配规则和一些常用的函数,当然还少不了必要的概念。那接下来就详细讲解。
2.1 常用匹配规则
废话不多说,直接上常用的匹配规则,如表1所示:(PS:可能刚开始会一头雾水,不要着急,深入浅出嘛!!!!)
表1 常用的匹配规则
| 模式 | 描述 |
|---|---|
| \w | 匹配字母、数字及下划线 |
| \W | 匹配不是字母、数字及下划线的字符 |
| \s | 匹配任意空白字符,等价于[\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于[0-9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行的任意字符 |
| […] | 用来表示一组字符, 单独列出,比如[ amk]匹配a、 m或k |
| [^…] | 不在[]中的字符,比如[^abc]匹配除了a、b、c之外的字符 |
| * | 匹配0个或多个表达式 |
| + | 匹配1个或多个表达式 |
| ? | 匹配0个或1个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面的表达式 |
| {n, m} | 匹配n到m次由前面正则表达式定义的片段,贪婪方式 |
| alb | 匹配a或b |
| () | 匹配括号内的表达式,也表示一个组 |
看完这个,肯定是一头无数,没有关系,接下来会详细讲解一些常见的规则用法。在讲解之前呢,先来看一个正则表达式测试工具,通过输入待匹配的文本,然后选择常用的正则表达式,就可以得到匹配的结果了,如图1所示:
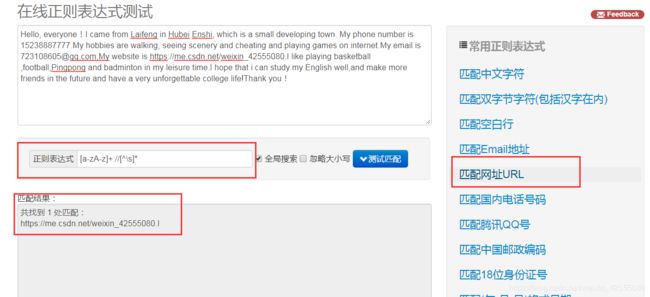
图1
通过上面的例子可以看出,输入文本之后,点击“匹配网址URL”,在正则表达式中会出现对应的匹配规则,然后就可以输出匹配结果。这里面的正则表达式是[a-zA-z]+://[^ \s]*,这个正则表达式看上去比较复杂,其实不然,这里面都是有特定的语法规则的。比如,[a-zA-z]代表匹配任意的小写字母 ,+代表前面的内容可以重复多次,\s 表示匹配任意的空白字符,*就代表匹配前面的字符任意多个,这长串的正则表达式就是这么多匹配规则的组合。写好正则表达式后,就可以拿它去一个长字符串里匹配查找了。只要符合规则,统统可以找出来。对于网页来说,如果想找出网页源代码里有多少URL,用匹配URL的正则表达式去匹配即可。
2.2 match()函数
2.2.1 match()函数的基本用法
首先呢,介绍第一个较为常用并且最简单的匹配方法match(正则表达式,待匹配内容). 向它传人要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否匹配字符串。match()方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回None。示例如下:
import re
content = "Hello 123 4567 zoneNumber I came from Laifeng in Hubei Enshi My phone number is 15238887777."
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())
运行结果如下:
92
Hello 123 4567 zoneNumber
(0, 25)
对上面的代码进行详细的解析: 这里首先声明了一个字符串,其中包含英文字母、空白字符、数字等。接下来,我们写一个正则表达式:^Hello\s\d\d\d\s\d{4}\s\w{10}
用它来匹配这个长字符串。开头的^是四配字符串的开头,也就是以Hello开头;然后\s匹配空白字符,用来匹配目标字符串的空格; \d匹配数字,3个\d匹配123;然后再写1个\s匹配空格;后面还有4567.我们其实可以依然用4个\d来匹配,但是这么写比较烦琐,所以后面可以跟{4}以代表匹配前面的规则4次,也就是匹配4个数字;然后后面再紧接1个空白字符,最后w{10}匹配10个字母及下划线。我们注意到,这里其实并没有把目标字符串匹配完,不过这样依然可以进行匹配,只不过匹配结果短点而已而在match()方法中,第一个参数传人了正则表达式,第二个参数传人了要匹配的字符串。
打印输出结果,可以看到结果是SRE Match对象,这证明成功匹配。该对象有两个方法: group()方法可以输出匹配到的内容,结果是Hello 123 4567 zoneNumber, 这恰好是正则表达式规则所匹配的内容: span() 方法可以输出匹配的范围,结果是(0, 25),这就是匹配到的结果字符串在原字符串中的位置范围。
2.2.2 匹配目标
刚才用match()方法可以得到匹配到的字符串内容,但是如果想从字符串中提取一部分内容。就像最前面的实例一样, 从一段文本中提取出邮件或电话号码等内容。这里可以使用()括号将想提取的子字符串括起来。()实际上标记了一个子表达式的开始和结束位置,被标记的每个表达式会依次对应每个分组,调用group()方法传人分组的索引即可获取提取的结果。示例如下:
import re
content = "Hello 1234567 zoneNumber I came from Laifeng in Hubei Enshi My phone number is 15238887777."
result = re.match('^Hello\s(\d+)\szone', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
这里是想将Hello后面的数字1234567 ,单独提取出来。 这里用到了group(1),它与group()有所不同,后者会输出完整的匹配结果.
运行结果如下:
Hello 1234567 zone
1234567
(0, 18)
通过结果可以清楚的看到提取了数字“1234567”,这里用的是group(1),它与group()的区别是,后者会输出完整的匹配结果,前者会输出第一个被()包围的匹配结果。如果正则表达式后面还有()包裹起来,就可以依次用group(2)、group(3)…等进行提取。
2.2.3 通用匹配
为了实现该功能,上面的正则表达式采取的方式是:出现空白字符我们就写\s匹配,出现数字我们就用\d匹配,这样的工作量非常大。为了简化公式,可以使用万能匹配,那就是.(点星),其中.(点)可以匹配任意字符(除换行符), (星)代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。有了它,我们就不用挨个字符地匹配了。
上面的例子就可以改写一下 正则表达式:
import re
content = "Hello 1234567 zoneNumber I came from Laifeng in Hubei Enshi My phone number is 15238887777"
result = re.match("^Hello.*77$",content)
print(result)
print(result.group())
print(result.span())
这里我们将中间部分直接省略,全部用. *来代替,最后加一一个结尾字符串就好了。运行结果如下:
7
(0, 90)
目的呢,依然想获取中间的数字。而数字两侧由于内容比较杂乱,所以想省略来写,都写成.*。 最后,组成,"^Hello.(\d+).77$",但是通过观察结果后发现print(result.group(1))输出的结果是7,而不是想要的1234567这是怎么回事呢?这里就涉及一个贪婪匹配与非贪婪匹配的问题了。在贪婪匹配下, 会匹配尽可能多的字符。正则表达式中 * 后面是\d+,也就是至少一个数字,并没有指定具体多少个数字,因此,. 就尽可能匹配多的字符,这里就把123456匹配了,给\d+留 下一个可满足条件的数字7,最后得到的内容就只有数字7了。这就相当于两个人(一个叫.*一个叫\d+)去抢饭吃,总共有7份饭,规定每个人至少一份饭,由 . * 先抢,它的原则是:尽可能多去抢饭,在规则的限制性,它只给\d+留下一份饭。\d+接着去抢,没办法只剩下最后一份叫“7”的饭了,而且它也不生气,为啥呢,因为他的原则是:尽可能把饭留给大家,自己够吃就行。
但是,有时候呢,想着\d+这个人太奉献了,那就让他多吃点吧(获取尽可能多的资源,达到匹配目的),这个时候就要对. * 进行限制,使用非贪婪匹配:.*?,多了一个?,这样可以通过上面的例子看一下:
import re
content = "Hello 1234567 zoneNumber I came from Laifeng in Hubei Enshi My phone number is 15238887777"
result = re.match("^Hello.*?(\d+).*77$",content)
print(result)
print(result.group(1))
print(result.span())
这里面只是将.改为了.?,转化为了非贪婪匹配, 结果为: 这个代码和上面的代码的区别是:将content里面的内容进行了换行处理,其他所有内容还是没有改动的,接下里的目的还是要匹配该内容中的数字,但是我们可以看到接下来的结果却是: 现在又遇到一个问题,那就是如果带匹配的符串里面就本省就包含 . 那该怎么办呢?正则表达式定义了许多匹配模式,如,匹配除换行符以外的任意字符,但是如果目标字 它的解决办法就是:当遇到用于正则匹配模式的特殊字符时,在前面加反斜线转义一下即可。例如.就可以用 \ .来匹配,运行结果如下:< sre.SRE Match object; span=(0, 17), match=’(百 度)www.baidu.com >可以看到,这里成功匹配到了原字符串。这个内容相对来说较为简单就不必详细讲解了。读者如果有问题可以自行查阅资料。 这篇内容讲解了正则表达式的基本内容,包括介绍了一个正则表达式的测试工具、介绍了常用的匹配规则、介绍了一个最基本、最终重要的函数match()、;匹配目标中的group()和span()方法、通用匹配.* 、贪婪和非贪婪 .*和. * ?、修饰符re.S、转义匹配等内容,下篇文章会继续讲解search()函数、findall()函数、sub()函数、compile()函数,下篇文章将会结合具体的网页代码进行讲解。以上内容参考资料:崔庆才《Python3 网络爬虫开发实战》,夏敏捷《Python程序设计-从基础到开发》,[挪]芒努斯·利·海特兰德(Magnus Lie Hetland)《Python基础教程第3版 Python编程从入门到实践 》,并对以上作者表示感谢。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
None
Traceback (most recent call last):
File “C:/Users/Administrator/PycharmProjects/practice1/1.py”, line 7, in
print(result.group(1))
AttributeError: ‘NoneType’ object has no attribute ‘group’
直接就出现了报错信息,通过上面的内容可以看到,result的内容是None,而且又通过调用result.group(1)方法,到这出下完了AttributeError的错误。那么,问题就来了,为什么就是简单的加了一个换行符就会出现这么大的错误呢?这是因为.匹配的是除换行符之外的任意字符,当遇到换行符时,.?就不能匹配了,所以导致匹配失败。这里只需加一个修饰符re.S, 、即可修正这个错误:re.match("^Hello.?(\d+).*?77$",content,re.S)。这个修饰符的作用是使.匹配包括换行符在内的所有字符。此时运行结果如下:1234567 这个re.S在网页匹配中经常用到。因为HTML节点经常会有换行,加上它,就可以匹配节点与节点之间的换行了。
如表2是全部的修饰符,其中网页匹配常用的、重要的为re.I 和re.S:
表2 修饰符
修饰符
描述
re.I
使匹配对大小写不敏感
re.L
做本地化识别( locale-aware)匹配
re.M
多行匹配,影响^和$
re.S
使.匹配包括换行在内的所有字符
re.U
根据Unicode字符集解析字符。这个标志影响\W、\w、\b和\B
re.X
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
2.2.6 转义匹配
这里就需要用到转义匹配了,示例如下:import re
content = ‘( 百度)www. baidu. com'
result = re.match('\( 百度\)www\. baidu\. com', content)
print(result)
3 总结
