软件工程第四次作业
| 这个作业属于哪个课程 | 2020春 S班 |
|---|---|
| 这个作业要求在哪里 | 结对编程作业要求 |
| 结对学号 | 221701131&221701131 |
| 作业目标 | 疫情统计可视化的实现 |
| 作业正文 | 作业链接 |
| 其他参考文献 | 博客园、CSDN、《构建之法 邹欣》 |
-
在文章开头给出Github仓库地址和代码规范链接。
github 仓库地址
[代码规范]([https://github.com/SpringAlex/InfectStatisticWeb/blob/master/java 代码规范.md](https://github.com/SpringAlex/InfectStatisticWeb/blob/master/java 代码规范.md))
-
展示你的成品,要求提供10张以上的图片,或者采用GIF或者视频嵌入的方式来展示作业要求的功能。如果部署到云服务器上,可以一并给出链接。
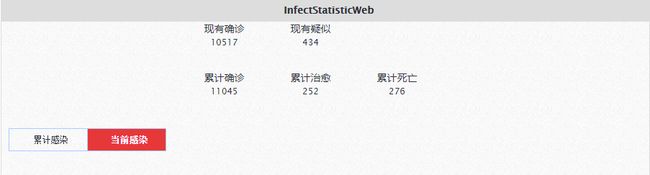

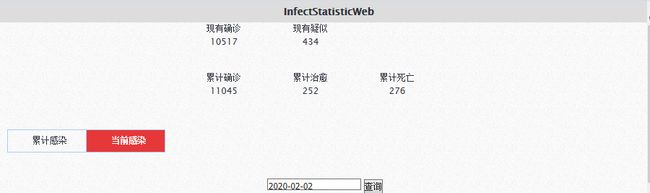
各省人数
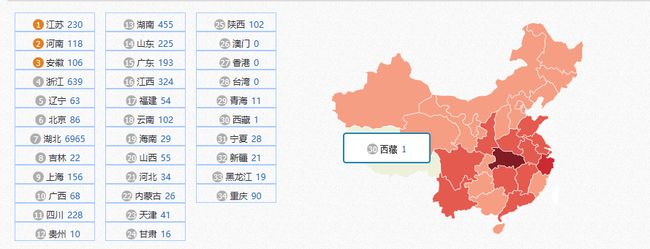

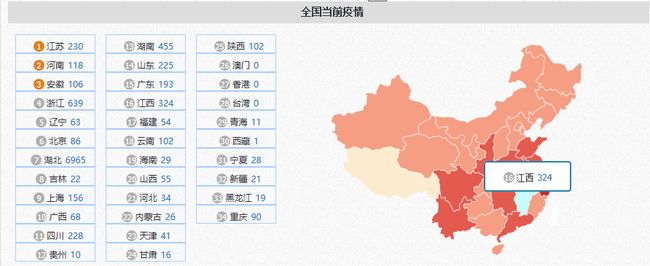
鼠标悬浮
省份的具体情报介绍
-
结对讨论过程描述,即刚开始拿到题目后,和队友怎么讨论,解决问题和查找资料的过程,并提供两人结对讨论的截图。
我们讨论是分阶段的。
第一阶段是就实验的平台和语言进行分析
备选方案是熟悉的WAMP和这学期刚开始学到Tomcat,相应的编程语言是php或者java。php语法简单,Java与之前实验的个人编程项目有关联。
为了拓展自己的认知,我们决定使用并不熟悉的Tomcat,这是一个并不明智的选择,因为我们只有一周时间,面对编译器到架构都不熟悉的语言,摆在我们的是一个巨大的挑战。
第二阶段是实验实现部分-前端实现。
我们采用前后台分离开发的策略,由一个负责前端开发,另一个同学负责后台java的改造。
前端主要解决的问题主要是JQuery的引入和E-chart的使用。通过上网搜索博客资料,学习心得,基本解决了展示部分的内容。
第三阶段是后端的开发与接入前端开发的内容。
后端要解决的问题有两个,一个是数据来源,老师提供的数据和网上提供的数据选哪一个?另一个就是如何拼接前后台的代码。
第一个问题经过我们多日的研究,决定还是改造旧的java代码读取文本数据。爬虫技术短时间的突击难以快速掌握。与数据读取的java httpClient只能读取原始的html,未能得到浏览器解析之后的代码。其他语言如python,没有学习的基础。
另外一个问题通过引入maven项目管理解决。
至此,各自技术难题基本解决。
-
描述设计实现过程,给出功能结构图。
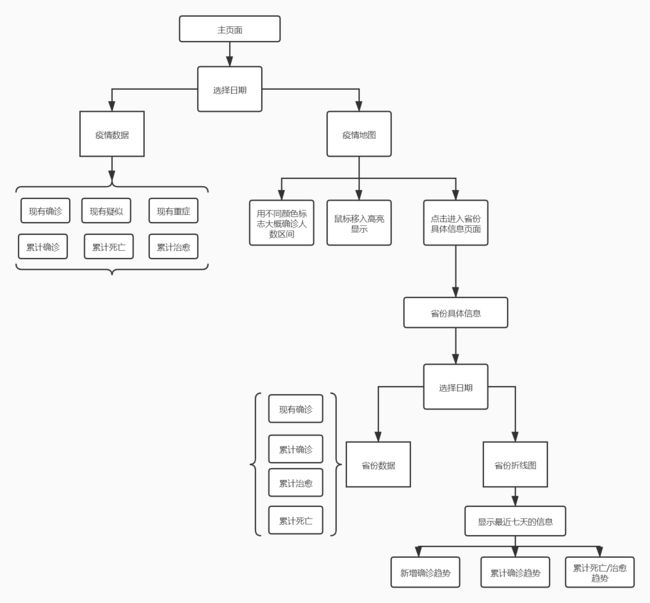
-
代码说明。展示出项目关键代码,300行左右,并解释思路。
//java代码部分:读取日志文件,统计各省份以及全国的感染情况,统计结果放在动态数组或数组当中
package mydao;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import javax.swing.text.StyledEditorKit.ForegroundAction;
public class InfectStatistic {
private String lastDate; //用户选择的日期
private String pathOfLog = "D:/log/"; //日志文件所在目录
public String[] allNeedDate; //记录所有用户选定日期之前(包括选定当天)的日期,格式:yyyy-mm-dd
//public ArrayList allProvince = new ArrayList(); //用于记录省份类的实例对象
public ArrayList allProvince;
private String[] allProvinceName = {"辽宁","吉林","黑龙江","河北","山西","陕西","甘肃","青海","山东","安徽","江苏","浙江","河南","湖北","湖南","江西","台湾","福建","云南","海南","四川","贵州","广东","内蒙古","新疆","广西","西藏","宁夏","北京","上海","天津","重庆","香港","澳门"};
public String[] allProvinceName2 = {"liaoning","jilin","heilongjiang","hebei","shanxi","shaanxi","gansu","qinghai","shandong","anhui","jiangsu","zhejiang","henan","hubei","hunan","jiangxi","taiwan","fujian","yunnan","hainan","sichuan","guizhou","guangdong","neimongol","xinjiang","guangxi","xizang","ningxia","beijing","shanghai","tianjin","chongqing","hongkong","macau"};
public class Province
{
public String provinceName; //省份名字
public String provinceName2;//省份拼音名字
public int ip; //当前感染患者数目
public int sp; //当前疑似患者数目
public int cure; //当前(累计)治愈数目
public int dead; //当前(累计)死亡数目
public int allIp; //累计确诊患者数量
public int newIp; //当天新增确诊数量
//用动态数据记录每天的情况
public ArrayList everyDayAddIp = new ArrayList();//每天新增确诊
public ArrayList everyDayIP = new ArrayList();//每天累计确诊数
public ArrayList everyDayCure = new ArrayList();//每天累计治愈数
public ArrayList everyDayDead = new ArrayList();//每天累计死亡数
//Description:构造函数
public Province(String provinceName,String provinceName2)
{
this.provinceName=provinceName;
this.provinceName2=provinceName2;
ip=0;
sp=0;
cure=0;
dead=0;
allIp=0;
newIp=0;
}
//Description:记录趋势
public void RecordTrend()
{
everyDayAddIp.add(newIp);//新增确诊趋势
everyDayIP.add(allIp);//累计确诊趋势
everyDayCure.add(cure);//累计治愈趋势
everyDayDead.add(dead);//累计死亡趋势
newIp = 0;//当天的新增确诊量,当天统计完成后,新增确诊数量清零
}
}
//Description:构造函数
public InfectStatistic(String date) {
this.lastDate = date;
allProvince = new ArrayList();
//创建所有省份实例对象
for (int i = 0;i < 34;i++)
{
Province province = new Province(allProvinceName[i],allProvinceName2[i]);
allProvince.add(province);
}
getAllNeedDate();//获取符合用户选择的日期前的日期(包括选定当天)
}
public int[] getNationSituation()
{
int nationIp=0;//全国现有确诊
int nationSp=0;//全国现有疑似
int nationAllIp=0;//全国累计确诊
int nationAllCure=0;//全国累计(现有)治愈
int nationAllDead=0;//全国累计(现有)死亡
for (int i=0;i<34;i++)
{
nationIp+=allProvince.get(i).ip;
nationSp+=allProvince.get(i).sp;
nationAllIp+=allProvince.get(i).allIp;
nationAllCure+=allProvince.get(i).cure;
nationAllDead+=allProvince.get(i).dead;
}
int[] nation= {nationIp,nationSp,nationAllIp,nationAllCure,nationAllDead};
return nation;
}
//Description:获取符合用户选择的日期前的日期(包括选定当天)
private void getAllNeedDate()
{
int count=0; //用于记录符合要求的日期的天数
File file = new File(pathOfLog);
File[] allLogFiles = file.listFiles();
String[] allLogFilesName = new String[allLogFiles.length];
for(int i = 0;i < allLogFiles.length;i++)
{
allLogFilesName[i] = allLogFiles[i].getName();
if (allLogFilesName[i].compareTo(lastDate+".log.txt") <= 0)
{
count++;
}
else
{
break;
}
}
if (count >= 1){
allNeedDate = new String[count];
for (int i = 0;i < count;i++)
{
int index = allLogFilesName[i].indexOf('.');
allNeedDate[i] = allLogFilesName[i].substring(0, index);
}
}
}
//Description:读取日志文件,得到各省的疫情数据
public void analyzeInfectSituation() throws IOException
{
for (int i = 0;i < allNeedDate.length;i++)
{
String oneLineOfFile = null;
try
{
InputStreamReader isr = new InputStreamReader(
//new FileInputStream(pathOfLog+allLogFilesName[i]), "UTF-8");
new FileInputStream(pathOfLog+allNeedDate[i]+".log.txt"));
BufferedReader br = new BufferedReader(isr);
while ((oneLineOfFile = br.readLine()) != null
&& oneLineOfFile.length() != 0 //不读取空行
&& oneLineOfFile.startsWith("//") == false) //不读取注释行
{
//System.out.println(oneLineOfFile);
//统计省份的感染人数,疑似人数,治愈人数和死亡人数
getProvincialInformation(oneLineOfFile);
}
br.close();
isr.close();
}
catch (FileNotFoundException e) {
e.printStackTrace();
}
for (int j = 0;j < allProvince.size();j++)
{
allProvince.get(j).RecordTrend();
}
}
}
//Description:分析日志文件中的每行,统计出相应人数情况
//Input:从日志文件读取出的一行信息
private void getProvincialInformation(String oneLineOfFile)
{
String[] splitString = oneLineOfFile.split(" ");
int countOfPeople = getStringNumber(splitString[splitString.length - 1]);
if (splitString.length == 3)
{
for (int i = 0;i < allProvince.size();i++)
{
if (allProvince.get(i).provinceName.equals(splitString[0]))
{
if (splitString[1].equals("死亡"))
{
allProvince.get(i).dead += countOfPeople;
allProvince.get(i).ip -= countOfPeople;
break;
}
else if (splitString[1].equals("治愈"))
{
allProvince.get(i).cure += countOfPeople;
allProvince.get(i).ip -= countOfPeople;
break;
}
}
}
}
else if (splitString.length == 4)
{
for (int i = 0;i < allProvince.size();i++)
{
if (allProvince.get(i).provinceName.equals(splitString[0]))
{
if (splitString[1].equals("新增")
&& splitString[2].equals("感染患者"))
{
allProvince.get(i).ip += countOfPeople;
allProvince.get(i).newIp += countOfPeople;//新增感染患者增加
allProvince.get(i).allIp += countOfPeople;//累计感染患者增加
break;
}
else if (splitString[1].equals("新增")
&& splitString[2].equals("疑似患者"))
{
allProvince.get(i).sp += countOfPeople;
break;
}
else if (splitString[1].equals("疑似患者")
&& splitString[2].equals("确诊感染"))
{
allProvince.get(i).sp -= countOfPeople;
allProvince.get(i).ip += countOfPeople;
allProvince.get(i).newIp += countOfPeople;//新增感染患者增加
allProvince.get(i).allIp += countOfPeople;//累计感染患者增加
break;
}
else if (splitString[1].equals("排除")
&& splitString[2].equals("疑似患者"))
{
allProvince.get(i).sp -= countOfPeople;
break;
}
}
}
}
else if (splitString.length == 5)
{
for (int i = 0;i < allProvince.size();i++)
{
if (allProvince.get(i).provinceName.equals(splitString[0]))
{
if (splitString[1].equals("感染患者"))
{
allProvince.get(i).ip -= countOfPeople;
}
else if (splitString[1].equals("疑似患者"))
{
allProvince.get(i).sp -= countOfPeople;
}
}
else if (allProvince.get(i).provinceName.equals(splitString[3]))
{
if (splitString[1].equals("感染患者"))
{
allProvince.get(i).ip += countOfPeople;
}
else if (splitString[1].equals("疑似患者"))
{
allProvince.get(i).sp += countOfPeople;
}
}
}
}
}
//Description:提取字符串当中的数字并转换成整数返回
//Input:一个包含了数字字符的字符串
//Return:一个整数
private int getStringNumber(String str)
{
str = str.trim();
String numString = "";
if(str != null && !"".equals(str))
{
for(int i = 0;i < str.length();i++)
{
if(str.charAt(i) >= 48 && str.charAt(i) <= 57)
{
numString += str.charAt(i);
}
}
}
return Integer.parseInt(numString);
}
}
-
阅读《构建之法》第四章至第五章的内容,结合在构建之法中学习到的相关内容,结对伙伴分别撰写结对开发项目的心路历程与收获,并评价结对队友。
《构建之法》阅读心得
两人合作,或者多人以上的合作,其实最在乎的点是互通。让别人理解自己,学会理解别人。为此我们必须有一套标准化的流程。
代码规范就是合作的第一步。自己写的代码往往随心所欲,因为自己是按照自己思路写的,就算是有问题出现也很容易看出来。然而,代码开发并非一人之功,你的代码终究还是要被别人阅读。而人与人之间的阅读能力和代码习惯不同,将会导致我们难以读懂代码。
代码规范看似只是行文风格,但其中涉及的程序设计,模块关系,设计模式的使用原则,都是编程的关键。
代码风格的规范包含:缩进、行宽、括号、断行和空白的{}行、分行、命名、下划线、大小写、注释。
书中的建议也很使用。
Tab键在不同情况下会有不同的缩进。4个空格固定,且在阅读距离上刚刚好。
行宽100字即可。(与屏幕大小有关)
括号能在复杂的表达式中清晰的表示逻辑优先级。
断行和空白{}行
使用{}都独占一行可以清晰看出嵌套的层次。
命名
有多种风格建议,我们使用熟悉的匈牙利命名法。
下划线
分隔变量名字中的作用域标注和变量的语义。
大小写
Pascal—所有单词的第一个字母都大写。Camel— 第一个单词全部小写,随后单词随Pas-cal形式,这种方式也叫lowerCamel。一 个通用的做法是:所有的类型/类/函数名都用Pascal形式,所有的变量都用Camel 形式。类/类型/变量:名词或组合名词,如Member、ProductInfo等。函数则用动 词或动宾组合词来表示,如get/set、RenderPage()。
注释
为了解释程序做什么(What),为什么这样做 (Why),以及要特别注意的地方。
复杂的注释应该放在函数头,很多函数头的注释都用来解释参数的类型。
代码设计规范包括函数,goto,错误处理,断言使用,类的使用
函数只做一件事,即低耦合,高内聚。
goto函数出口,最好是只有单一出口。
错误处理往往要占编程80%
断言和错误处理的关系是:当你觉得某事肯定如何时,就可以用断言。 当你觉得某事肯定如何时,就可以用断言。如果你认为某事可能会发生,这时 就要写代码来处理可能发生的错误情况 。
简单的数据封装不需要使用类的封装。不要往析构函数和构造函数塞太多的东西。
运算符也一般不需要自定义。
异常的处理也很重要。
尽在必要时候才进行类型处理。const用来标注不改变数据的函数。
代码复审
目前阶段,同伴复审和自我复审。
复审就是对开发的完善。是做中学思想的体现。
复审必须得到双发的一致意见。
可以为复审核查表添加自己的注意事项。
主要涉及是否符合已知的项目设计模式和设计规范。
有没有硬编码或者字符串/数字等存在。
代码的可移植性。
有没有无用的代码删除(会影响阅读和理解)
代码风格规范。
具体代码是否健壮,参数处理、边界条件的使用是否正确。
代码执行的效率如何。有没有可以优化的部分。
结对编程可以互换角色,避免过度疲劳,工作紧张,导致观察力和判断力的下降。双方都要和结对精神和合作精神。
结对编程是一个渐进的过程,需要双方不断地磨合和适应。
第五章介绍的是团队编程。
首先什么是团队啊。团队不是一群人热热闹闹,就是团队。团队是一个团队,而不是简单地人地集合体。
团队要称得上团队,第一要点就是凝聚力。什么是凝聚力,就是力的方向一致。方向是什么,方向就是共同的目标。一个团队要有公共的目标。
第二点是管理,所谓的管理,就是让合力最大化的分配。
书上介绍了几种有趣的管理模型。分别是主治医生团队(一个人干活,其他人帮忙),明星模式(主治医师的极致),社区模式(开源项目),业余剧团模式(业余业余,每个人都可能担当不同角色),秘密团队(很神秘哦,几乎不和外界沟通)交响乐模式(各司其职,精诚合作,沟通较少,都是专业选手)爵士乐模式(个性发挥,创意为主),功能团队模式(是具备不同能力的同 事们平等协作,共同完成一个功能),官僚模式(技术团队和传统管理的结合,如果运用不好就会有成为老板驱动的风险)
开发流程有:
写了就改模式(只用一次,就好像我们的作业,呵呵)
瀑布模式(传统的开发模式,层次分明,但是缺乏灵活性,改进之后的有相邻步骤回溯)需要各个步骤都足够明确,但是我们都知道,需求不是那么明显,所以在早期对用户的需求的分析很重要。否则开发可能功亏一篑。此外各个阶段的文档收集也很重要。
他的缺点很明显
各步骤之间是分离的,但是软件生产过程中的各个步骤不能这样严格分离出来 回溯修改很困难甚至不可能,但是软件生产的过程需要时时回溯 最终产品直到最后才出现,但是软件的客户,甚至软件工程师本人都需要尽早知道产品的原型并试用 。
改进之后的瀑布模型重视步骤的关联和回溯,将步骤进行细分等。比如生鱼片模型,子瀑布模型。这样做能够改善产品的回溯。但最终产品还是得很久才能看到。
Rational Unified Process
重计划,重事先 设计,重文档表达。要完成一个复杂的软件项目,团队的各种成员要在不同阶段做不同的事 情,这些不同类型的工作在RUP中叫做规程(Discipline)或者工作流
业务建模
理解目前用户的业务流程任何和客户的正常工作相关的业务活动(例 如政府为居民提供网上服务,学生到图书馆借书)都是建模的对象。。这个工作流 的结果通常是用例(Use Case)。
需求
分析并确认软件系统得提供 什么样的功能来满足用户的需求,功能有什么约束条件,如何验证功能满足了用 户需求。这就是需求(Requirement)工作流的作用。
分析和设计
分析和设计(Analysis & Design)工作流将需求转化成系统的设计。这一步结束 之后,团队成员就能知道系统有哪些子系统、模块,它们之间的关系是怎样的。
实现
在实现(Implementation)工作流中,工程师按照计划实现上一步产出的设计, 将开发出的组件(Module),连同验证模块(例如:单元测试)提交到系统中。 同时,工程师们集成由单个开发者(或小组)所产生的结果,通过手工或自动化 的手段,把可执行的系统搭建出来。
测试
测试(Test)工作流要验证现阶段交付的所有组件的正确性、组件之间交互的正 确性,以及检验所有的需求已被正确地实现。在这个过程中,发现、报告、会 诊、修复各种缺陷,在软件部署之前保证质量达到预期要求。
部署
部署(Deployment)工作流的目的是生成最终版本并将软件分发给最终用户。具 体过程可以参考本书“典型用户和场景”一章。
配置和变更管理
配置和变更管理工作流(Configuration andChange Management)负责管理 RUP各个阶段产生的各种工作结果(例如源代码控制系统管理和备份各种源文 件),要记录修改人员、修改原因、修改时间等属性,有些团队还可以考虑并行 开发、分布式开发等。
项目管理
软件项目管理工作流(Project Management)平衡各种可能产生冲突的目标,管 理风险,克服各种约束并成功地在各个阶段交付达到要求的产品。
环境
环境(Environment)工作流的目的是向软件开发组织提供软件开发环境,包括 过程和工具。RUP有四个阶段
1.初始阶段分析大概构成
2.细化阶段分析问题领域,建立健全的体系结构。
3.构造阶段,开发所有的功能集,并进行各种测试,这个阶段是产品最为重要的阶段。
4.交付阶段,确保用户的需求能能够正确实现。
有趣的boss-driven process阶段
由老板驱动的流程。领导的权威对于团队的影响最大。但是领导对于技术可能一窍不通。
渐进交付的流程(MVP、BMP)
反复进行迭代式开发。开发→发布→听取反 馈→根据反馈做改进
不断的渐进。
MVP式开发以核心功能集为中心进行开发。
BMP也是类似的道理,以核心功能为中心进行开发。
评价结对队友
031:
这次合作学习了很多,总的来说,还是认知的不够,工具不够熟练,在一些问题上用了太多的时间,效率有待提高,一直对自己的编程能力有一种蜜汁自信的我算是尝到了痛苦的滋味。
队友还是挺给力的,后端一个人撑起来了,回复也很及时。缺点就是有点拖沓,deadline 之前才开始认真。
014:
学习了很多,想的没有做的容易。项目的迁徙并没有那么顺利。github 的使用还是不够。以后要加强。deadline的压迫下,效率低得可怕。真是另外一种滋味。合作比单独编程难多了。
队友还是挺认真的,前端界面做得挺好的