深度学习图像分割算法—FCN代码实现
FCN(全卷积网络)
原论文链接:https://arxiv.org/pdf/1411.4038.pdf
官方源代码:https://github.com/shelhamer/fcn.berkeleyvision.org截图如下
data文件夹:官方提供的四个数据集相关的文件,允许代码下载的数据集放在这个文件夹中
demo:官方代码提供的演示效果
nyud、pascalcontext、sififlow、voc开头的文件夹分别对应caffe网络及训练参数文件,由对应的名称可做对应的实验
nyud_layer.py,pascalcontext_layer.py,sififlow_layer.py,voc_layer.py分别是四个数据集对应的训练层
infer.py:测试需要的文件
score.py:求取分割得分的文件
surgery.py:权重转换文件
vis.py:可视化文件
官方开源代码提供了PASCAL VOC models,SIFT Flow models,PASCAL-Context models的完整(32s,16s,8s)的代码,但对于NYUD只提供了32s的代码,这里我们就以NYUD作为例子说明一下FCN-8s训练的完整过程。
源代码下载和数据集预处理
下载官方源代码:
git clone https://github.com/shelhamer/fcn.berkeleyvision.org下载VGG16的预训练模型,放在FCN源代码文件夹ilsvrc-nets下:
cd fcn.berkeleyvision.org/ilsvrc-nets
wget http://www.robots.ox.ac.uk/~vgg/software/very_deep/caffe/VGG_ILSVRC_16_layers.caffemodel获取相对应的deploy文件,放到ilsvrc-nets文件夹下:
wget https://gist.githubusercontent.com/ksimonyan/211839e770f7b538e2d8/raw/0067c9b32f60362c74f4c445a080beed06b07eb3/VGG_ILSVRC_16_layers_deploy.prototxt
下载数据集到源代码data/nyud文件夹下,并解压数据集:
cd data/nyud
wget http://dl.caffe.berkeleyvision.org/nyud.tar.gz
tar -xvf nyud.tar.gz解压以后的文件夹有

benchmarkData/groundTruth中存储着所有我们需要的分割的真值,data/images文件夹存储着原始的RGB文件。由于源代码设置的groundTruth路径和现有的路径不同,所以我们需要把groundTruth文件copy到指定路径:
mkdir segmentation
cp /home/bxx-mct/fcn.berkeleyvision.org/data/nyud/nyud/benchmarkData/groundTruth/*.mat segmentation/合并train.txt和val.txt:在nyud文件夹中新建一个空白文件命名为trainval.txt,然后将train.txt和val.txt中的内容Copy过去。
cat train.txt>>trainval.txt
cat val.txt>>trainval.txtnyud文件夹下面的内容
![]()
FCN-32s网络的训练:
- 将要用的.py文件Copy到nyud-fcn32s-color文件夹:包括infer.py、score.py、surgery.py、vis.py、nyud_layer.py
cp /home/bxx-mct/fcn.berkeleyvision.org/infer.py nyud-fcn32s-color
cp /home/bxx-mct/fcn.berkeleyvision.org/score.py nyud-fcn32s-color
cp /home/bxx-mct/fcn.berkeleyvision.org/surgery.py nyud-fcn32s-color
cp /home/bxx-mct/fcn.berkeleyvision.org/vis.py nyud-fcn32s-color
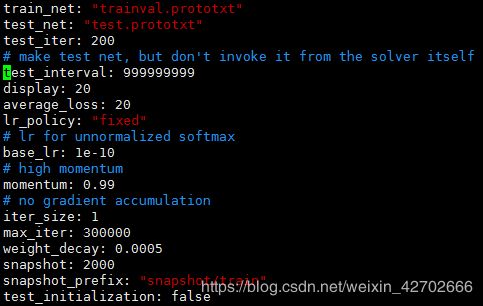
cp /home/bxx-mct/fcn.berkeleyvision.org/nyud_layers.py nyud-fcn32s-color- 修改solver.prototxt文件
该文件参数参考:https://blog.csdn.net/weixin_42702666/article/details/87794310
修改nyud-fcn32s-color/solve.py文件
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd())) #获得当前路径(返回最后的文件名)
#比如os.getcwd()获得的当前路径为/home/bxx-mct/fcn,则os.path.basename()为fcn;
#setproctitle是用来修改进程入口名称,如C++中入口为main()函数
except:
pass
#weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_weights = '../ilsvrc-nets/VGG_ILSVRC_16_layers.caffemodel' #用来fine-tune的FCN参数
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt' #VGGNet模型
# init
#caffe.set_device(int(sys.argv[1])) 获取命令行参数,其中sys.argv[0]为文件名,argv[1]为紧随其后的那个参数
caffe.set_device(1) #GPU型号id,这里指定第二块GPU
caffe.set_mode_gpu()
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights) #这个方法仅仅是从vgg-16模型中拷贝参数,但是并没有改造原先的网络,这才是不收敛的根源
solver = caffe.SGDSolver('solver.prototxt') #调用SGD(随即梯度下降)Solver方法,solver.prototxt为所需参数
vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN) #vgg_net是原来的VGGNet模型(包括训练好的参数)
surgery.transplant(solver.net, vgg_net) #FCN模型(参数)与原来的VGGNet模型之间的转化
del vgg_net #删除VGGNet模型
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k] #interp_layers为upscore层
surgery.interp(solver.net, interp_layers) #将upscore层中每层的权重初始化为双线性内核插值
# scoring
test = np.loadtxt('../data/nyud/test.txt', dtype=str) #载入测试图片信息
for _ in range(50):
solver.step(2000) #每2000次训练迭代执行后面的函数
score.seg_tests(solver, False, val, layer='score') #测试图片
(1)修改setup方法
- 同时由于路径原因,需要修改nyud_layers.py中load_label function 的内容:
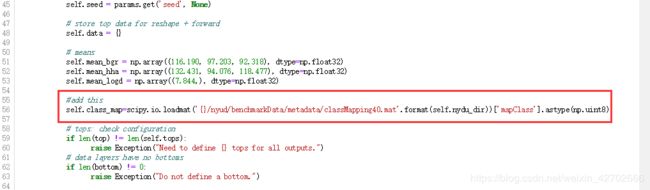
(2)修改 load_label方法

训练
以上配置全部结束,开始进行模型训练
cd nyud-fcn32s-color
mkdir snapshot
python solve.py

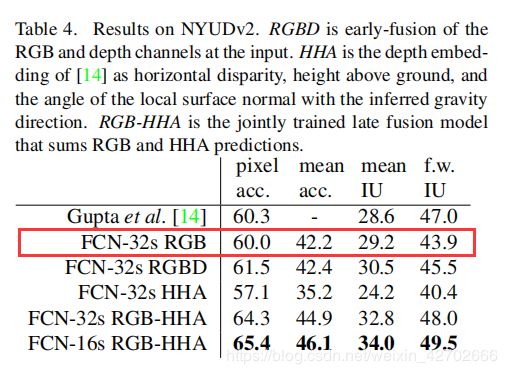
训练100000次的结果,可以和原文比较,已经很接近论文的结果了,如果迭代次数为150000次的话,会与原论文结果相似。
测试
接下来利用生成的模型进行测试,修改infer.py文件如下,这里会用到测试时的deploy.prototxt文件。
# -*- coding: utf-8 -*-
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import scipy.io
CAFFE_ROOT = "/home/bxx-mct/caffe"
import sys
sys.path.insert(0, CAFFE_ROOT + '/python')
import caffe
import vis
# the demo image is "2007_000129" from PASCAL VOC
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('../demo/image.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
#加载网络文件,与模型文件,并设置为测试模型
# load net
net = caffe.Net('./deploy.prototxt', './snapshot/train_iter_100000.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
scipy.io.savemat('./out.mat', {'X': out})
# visualize segmentation in PASCAL VOC colors
plt.imshow(out)
plt.show()
plt.axis('off')
plt.savefig('../demo/testout_32s.png')
#voc_palette = vis.make_palette(21)
#out_im = Image.fromarray(vis.color_seg(out, voc_palette))
#out_im.save('demo/output.png')
#masked_im = Image.fromarray(vis.vis_seg(im, out, voc_palette))
#masked_im.save('demo/visualization.jpg')
nyud-fcn32s-color文件夹下没有deploy.prototxt文件,可以根据以下方法生成:
nyud-fcn32s-color的文件夹,里面有trainval.prototxt文件,将文件打开,全选,复制,新建一个名为deploy.prototxt文件,粘贴进去,然后ctrl+F 寻找所有名为loss的layer 将这个layer统统删除,并去除第一层的python层。
实际删除的是:
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "nyud_layers"
layer: "NYUDSegDataLayer"
param_str: "{\'tops\': [\'color\', \'label\'], \'seed\': 1337, \'nyud_dir\': \'../data/nyud\', \'split\': \'trainval\'}"
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "score"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255
normalize: false
}
}
然后在第一层添加:
layer {
name: "input"
type: "Input"
top: "data"
input_param {
# These dimensions are purely for sake of example;
# see infer.py for how to reshape the net to the given input size.
shape { dim: 1 dim: 3 dim: 480 dim: 640 }
}
}
运行文件infer.py即可。

