数据预处理-----数据清洗
数据清洗主要处理三类值:重复值、缺失值以及异常值。
- 重复值:
重复值的处理主要用到了drop_duplicates()函数,该函数适用DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据。
函数:
df.drop_duplicates(subset=None, keep=‘first’, inplace=False)
参数说明:
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
1.df.drop_duplicates() 不指定任何参数

2.df.drop_duplicates(subset=[‘one’]) 指定subset参数
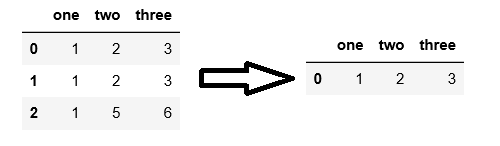
3.df.drop_duplicates(keep=‘last’) 指定keep参数为last

4.df.duplicates(keep=False) 指定keep参数为False

- 缺失值
1.pandas判断缺失值一般采用 isnull(),生成的是所有数据的true/false矩阵
在这里使用的DataFrame:
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
df = DataFrame({'one':[np.nan,1,2],'two':[2,np.nan,3],'three':[4,5,np.nan]})
df

1.1.df.isnull()
元素级别的判断,把对应的所有元素的位置都列出来,
元素为空或者NA就显示True,否则就是False

1.2.df.isnull().any()
列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
判断哪些’列‘存在缺失值:

1.3 df.isnull().sum()
将列中为空的个数进行合计

2.缺失值的处理通常有三种方法,分别是删除法、替换法以及插值法。在这里介绍前两种。
2.1删除法
删除缺失值在这里主要使用pandas中的dropna()方法
如果是Series,则返回一个仅含非空数据和索引值的Series,默认丢弃含有缺失值的行。
xx.dropna()
对于DataFrame:
1.data.dropna(how = 'all') # 传入这个参数后将只丢弃全为缺失值的那些行
2.data.dropna(axis = 1) # 丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征)
3.data.dropna(axis=1,how="all") # 丢弃全为缺失值的那些列
4.data.dropna(axis=0,subset = ["Age", "Sex"]) # 丢弃‘Age’和‘Sex’这两列中有缺失值的行
2.2 替换法(fillna())
fillna()函数:
.fillna(value, method, axis, inplace=False, limit, downcast=None, **kwargs)
常见参数解析:
method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值去替换缺失值(缺省默认这种方式)
limit参数:限制填充个数
axis参数:修改填充方向
2.2.1 不指定任何参数
- 用常数填充

2.使用字典填充
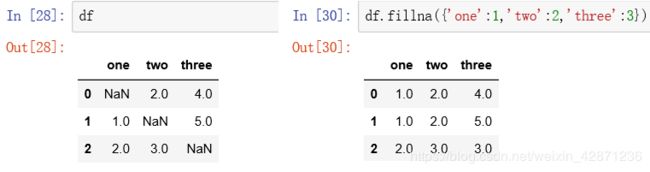
2.2.2 指定method参数
1.method = ‘ffill’/‘pad’:用前一个非缺失值去填充该缺失值

2.method = ‘bflii’/‘backfill’:用下一个非缺失值填充该缺失值

3.设置limit参数
只填充一个

- 异常值
异常值是指数据中有异常的值,其不是错误的数据,出现的频率通常很低,但对数据分析结果有着重要的影响。
异常值的判定方法:
1.标准差法
以样本均值和标准差为基准,
如果样本离平均值相差2个标准差以上的就是异常值
2.箱线图法
箱线图法:以上下四分位作为参考,
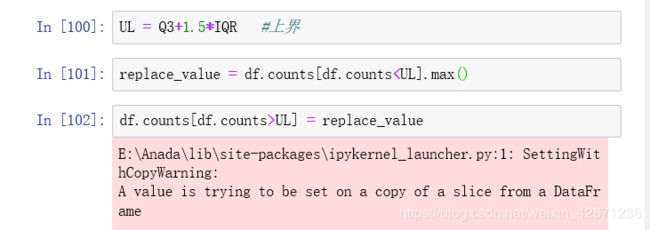
x > Q3+1.5*IQR 或者 x < Q1 - 1.5*IQR 的x,就是异常值
两种异常值判定是,如数据近似服从正态分布是,优先选择标准差法,因为数据的分布相对比较对称:否则优先选择箱线图法,因为分位数并不会受极端值的影响。
数据:

3.1标准差法
均值-2倍标准差 <= 正常值 <= 均值+2倍标准差
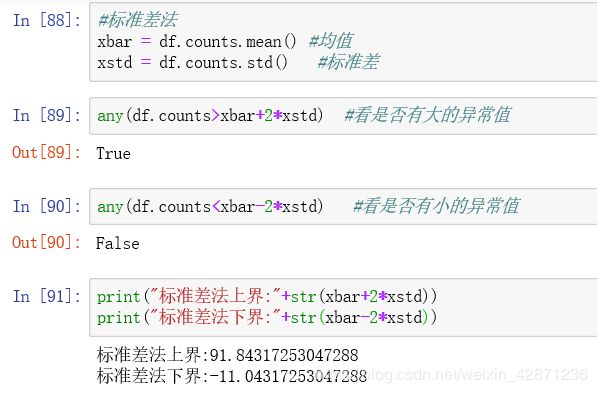
从下列直方图可以看出确实只有大的异常值,即大于91.843.。。的
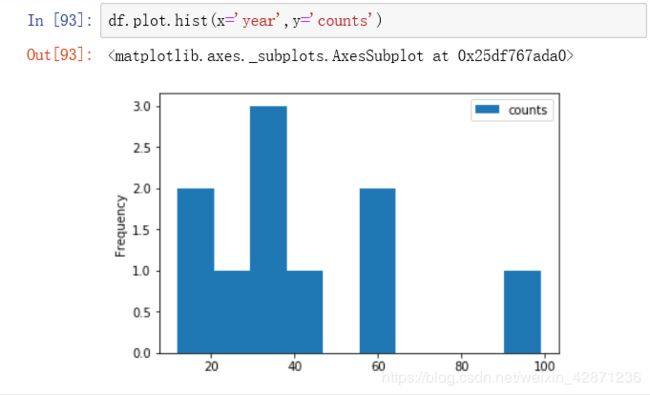
3.2箱线图法

画图看其数据分布,从下图可以看出,数据向左偏斜,不符合正态分布。故下面的异常值替换采用箱线图法。

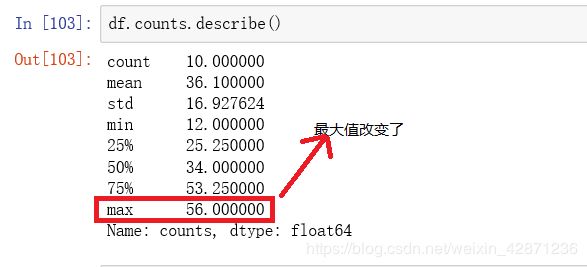
3.3 异常值替换

流程图
