一、Spark
(一)Spark基础知识
1、Spark的产生背景
1. MapReduce的发展
1.1、MRv1的缺陷
(1)MRv1包括:
运行时环境(JobTracker和TaskTracker)
编程模型(MapReduce)
数据处理引擎(MapTask和ReduceTask)
(2)不足:
可扩展性差:JobTracker既负责资源调度又负责任务调度
可用性差:采用单节点Master,容易产生单点故障
资源利用率低
不能支持多种MapReduce框架
1.2、MRv2的缺陷
(1)运行时环境被重构:
JobTracker拆分为:
资源调度平台(ResourceManager)、
节点管理器(NodeManager)
负责各个计算框架的任务调度模型(ApplicationMaster)
(2)不足:
由于对HDFS的频繁操作(包括计算结果持久化、数据备份、资源下载及Shuffle等)
导致磁盘I/O成为系统性能的瓶颈,因此只适用于离线数据处理或批处理,而不能支持
对迭代式、交互式、流式数据的处理。
1.3、Spark的产生
(1)减少磁盘I/O:Spark允许将map端的中间输出和结果存储在内存中,reduce端
在拉取中间结果是避免了大量的磁盘I/O。Spark将应用程序上传的资源文件缓冲到Driver
本地文件服务的内存中,当Executor执行任务时直接从Driver的内存中读取,也节省
了大量的磁盘I/O。
(2)增加并行度:Spark把不同的环节抽象为Stage,允许多个Stage既可以串行执行,
又可以并行执行。
(3)避免重新计算:当Spark中的某个分区的task执行失败后,会重新对此stage调度,
但在调度的时候会过滤掉已经执行成功的分区任务,所以不会造成重复计算和资源浪费。
(4)可选的Shuffle和排序:Hadoop MapReduce在Shuffle之前有着固定的排序
操作(只能对key进行字典排序),Spark可以根据不同的场景选择在map端排序或者
reduce端排序。
(5)灵活的内存管理策略:Spark将内存分为堆上的存储内存、堆外的存储内存、堆上
堆上的执行内存、堆外的执行内存。
2、Spark特点
1. 快速高效
2. 简洁易用
3. 全栈式数据处理
3.1、支持批处理(SparkCore)
3.2、支持交互式查询(SparkSQL)
3.3、支持流式计算(SparkStreaming)
3.4、 支持机器学习(Spark MLlib)
3.5、 支持图计算(Spark GraghX)
3.6、 支持Python操作(PySpark)
3.7、支持R语言(SparkR)
4. 兼容
4.1、可用性高
4.2、丰富的数据源支持
3、Spark应用场景
1. 复杂的批量处理(SparkCore)
2. 基于历史数据的交互式查询(SparkSQL)
3. 基于实时数据流的数据处理(SparkStreaming)
(二)SparkCore
1、Spark核心概念
1.Application
表示应用程序,包含一个Driver Program和若干Executor
2.Driver Program
Spark中的Driver,即运行上述Application的main()函数并且创建SparkContext,其中
创建SparkContext的目的是为了准备Spark应用程序的运行环境。由SparkContext负责与
Cluster Manager 通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭
SparkContext。
3.ClusterManager
在standalone模式中即为Master(主节点),控制这个集群,监控Worker。在YARN模式
中为资源管理器。
4.SparkContext
整个应用的上下文,控制应用程序的生命周期,负责调度各个运算资源,协调各个Worker
上的Executor。初始化的时候,会初始化DAGScheduler和TaskScheduler两个核心组件。
5.RDD
Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Gragh。
6.DAGScheduler
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是
RDD之间的依赖关系:宽依赖,也叫Shuffle依赖。
7.TaskScheduler
将Taskset提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
8.Worker
集群中可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的
worker节点,在Spark on YARN模式中指的就是NodeManager节点。
9.Executor
某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且把数据
存在内存或者磁盘上。
10.Stage
每个Job会被拆成很多组Task,每组作为一个TaskSet,其名称为Stage。
11.Job
包含多个Task组成的并行计算,是由Action行为触发的
12.Task
在Executor进程中执行任务的工作单元,多个Task组成一个Stage。
13.SparkEnv
线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内创建并包含如下一些重要组件的引用:
MapOutPutTracker:负责Shuffle元数据的存储
BroadcastManager:负责广播变量的控制与元信息的存储
BlockManager:负责存储管理、创建和查找块
MetricsSystem:监控运行时性能指标信息
SparkConf:负责存储配置信息
2、Spark核心功能
1. SparkContext
通常而言,DriverApplication 的执行与输出都是通过 SparkContext 来完成的,
在正式提交Application 之前,首先需要初始化 SparkContext。SparkContext
隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、测量系统、文件
服务、Web 服务等内容,应用程序开发者只需要使用 SparkContext 提供的 API 完成
功能开发。
SparkContext 内置的 DAGScheduler 负责创建 Job,将 DAG 中的 RDD 划分
到不同的 Stage,提交 Stage 等功能。
SparkContext 内置的 TaskScheduler 负责资源的申请、任务的提交及请求集群
对任务的调度等工作。
2.存储体系
Spark 优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,
这极大地减少了磁盘 I/O,提升了任务执行的效率
3.计算引擎
计算引擎由 SparkContext 中的 DAGScheduler、RDD 以及具体节点上的 Executor
负责执行的 Map 和 Reduce 任务组成。
4.部署模式
通过使用 Standalone、YARN、Mesos、kubernetes、Cloud等部署模式为 Task
分配计算资源,提高任务的并发执行效率。
3、Spark基本架构
Spark集群组成:
1.Cluster Manager:
Spark的集群管理器,主要负责资源的分配和管理。集群管理器分配的资源属于一级分配,
它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源
分配。目前,Standalone、YARN、Mesos、K8S,EC2 等都可以作为 Spark的集群管理
器。
2.Master:Spark集群的主节点
3.Worker:
Spark的工作节点。对Spark应用程序而言,有集群管理器分配得到资源的Worker节点
主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,
同步资源信息给Cluster Manager。
4.Executor:
执行计算任务的一些进程。主要负责任务的执行以及与Worker、Driver Application
的信息同步。
5.Driver Application:
客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转化为RDD和DAG,
并与Cluster Manager进行通信和调度。
4、Spark运行流程
1.构建DAG
使用算子操作RDD进行各种Transformation操作,最后通过action操作出发Spark作业运行。
提交之后Spark会根据转换过程所产生的RDD之间的依赖关系构建有向无环图。
2.DAG切割
DAG切割主要根据RDD的依赖是否为宽依赖来决定切割节点,当遇到宽依赖就将任务划分为
一个新的调度阶段(stage)。每个Stage中包含一个或多个Task。这些Task将形成任务集
(Taskset),提交给底层调度器进行调度运行。
3.任务调度
每一个Spark任务调度器只为一个SparkContext实例服务。当任务调度器收到任务集后负责
把任务集以Task的形式分发给Worker节点的Executor进程中运行,如果某个任务执行失败,
任务调度器负责重新分配该任务的计算。
4.执行任务
当Executor收到发送过来的任务后,将以多线程(会在启动executor的时候就初始化好了一
各线程池)的形式执行任务的计算,每个线程负责一个任务,任务结束后会根据任务的类型选
择相应的返回形式将结果返回给任务调度器。
5、RDD概述
1.什么是RDD
RDD叫做分布式数据集,是Spark中最基本的抽象概念,它代表一个不可变、可分区、
里面的元素可并行计算的集合。
1.1、数据集DataSet
RDD是数据集合的抽象,是复杂物理介质存在数据的一种逻辑视图。从外部来看,
RDD的确可以被看待成经过封装,带扩展特性的数据集合。
1.2、分布式Distributed
RDD的数据可能在物理上存储在多个节点的磁盘或内存中,也就是所谓的多级存储。
1.3、弹性Resilient
虽然RDD内部存储的数据是可读的,但是我们可以去修改并行计算单元的划分结构,
也就是分区的数量。
2.RDD的特点
自动容错、位置感知性调度、可伸缩性
3.RDD的属性
3.1、A list of partitions
一组分片(partition),及数据集的基本组成单位。分区的个数决定了并行的粒度。
分区的个数可以在创建RDD的时候进行设置,若没有,则默认为cores个数。每个partition
最终会bei被逻辑映射为BlockManager中的一个Block,而这个Block会被下一个Task使用
进行计算。
3.2、A function for computing each split
一个计算每个分区的函数,也就是算子。
3.3、A list of dependencies on other RDDs
RDD之间的依赖关系:宽依赖和窄依赖
宽依赖:一个子RDD中的分区可以依赖于父RDD分区中一个或多个完整分区。
窄依赖:父RDD的一个partition中的部分数据与RDDx的一个partition相关,而另一部分
数据则与RDDx中的另一个partition有关。
3.4、Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
一个partitioner,即RDD的分片函数。
3.5、Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
一个列表,存储存取每个partition的优先位置。
4.RDD创建
4.1、由一个已经存在的Scala数据集合创建
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8))
val rdd = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
4.2、由外部存储系统的数据集创建
val rdd = sc.textFile("hdfs://myha01/spark/wc/input/words.txt")
4.3、扩展
从 HBase 当中读取
从 ElasticSearch 中读取
5.Transformation转换
转换算子:map、filter、flatMap、mapPartitions、sample、union、intersection、
distinct、groupByKey、aggregateByKey、sortByKey、sortBy、join、coalesce、
repartition、foldByKey、combineByKey、partitionBy、cache、persist、substract、
leftOuterJoin、rightOuterJoin、subtractByKey
总结:Transformation返回值还是一个RDD。它使用l了链式调用的设计模式,对一个
RDD进行计算后,变换成另一个RDD,然后这个RDD又可以进行另外一次转换。这个
过程是分布式的。
6.Action
Action算子:reduce、reduceByKeyLocally、collect、count、first、take、takeSample、
top、takeOrdered、countByKey、foreach、foreachPartition、fold、aggregate、
lookup、saveASTextFile、saveAsSequenceFile、saveAsObjectFile
总结:Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,
要么是空,最终返回到Driver程序,或把RDD写入到文件系统中。
6、Spark任务执行流程
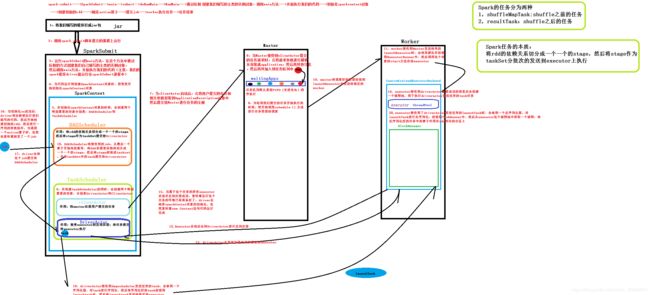
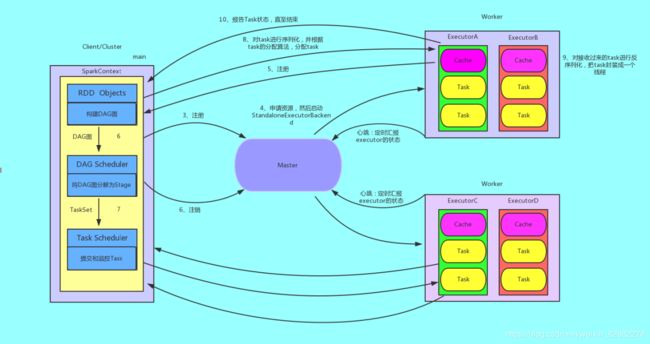
7、Spark On StandAlone运行过程
8、Spark On YARN YARN-Client运行过程

9、Spark On YARN YARN-Cluster运行过程
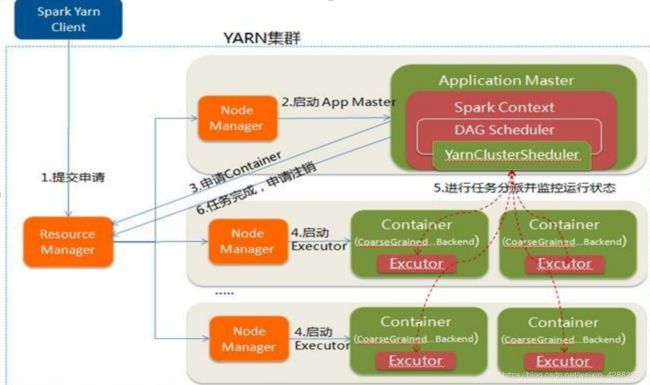
10、YARN-Client 和 YARN-Cluster 区别
1.YARN-Cluster模式下,Driver运行在AM(Application Master),它负责向YARN申请资源,
并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN
上运行,因而YARN-Cluster模式不适合运行交互类型的作业。
2.YARN-Client模式下,ApplicationMaster仅仅向Yarn请求Executor,Client会和请求的
container通信来调度他们工作,也就是说client不能离开。
11、Spark内存模型
1.在执行Spark的应用程序时,Spark集群会启动Driver和Executor两种JVM进程。
1.1、前者为主控进程,负责创建Spark上下文对象SparkContext,提交Spark作业(job),
并将作业转换为计算任务(Task),在各个Executor进程间协调任务的调度。
1.2、后者负责在工作节点上执行具体的计算任务,并将结果返回给Driver,同时为需要持
久化的RDD提供存储功能。
2.堆内和堆外内存规划
对堆内内存进行更为详尽的分配,引入堆外内存
2.1、堆内内存
堆内内存的大小,由Spark应用程序启动时的--executor-memory或
spark.executor.memory
(1)Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD数据集和
广播(Broadcast)数据时占用的内存被规划为存储内存。
(2)这些任务在执行Shuffle时占用的内存被规划为执行内存。
(3)剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户自定义的Spark
应用程序中的对象实例,均占用剩余的空间other。
Spark申请内存:
(1)Saprk在代码中new一个对象实例
(2)JVM从堆内内存分配空间,创建对象并返回对象引用
(3)Spark保存该对象的引用,记录该对象占用的内存
Spark释放内存:
(1)Spark记录该对象释放的内存,删除该对象的引用
(2)等待JVM的垃圾回收机制释放该对象占用的堆内内存
JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,
本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需
要进行序列化的逆过程--反序列化,将字节流转化为对象,序列化的方式可以节省存储空
间,但增加了存储和读取时候的计算开销。对于 Spark 中序列化的对象,由于是字节流的形
式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地
采样近似估算而得。
2.2、堆外内存
Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回
收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可
以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启
用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。
12、资源参数调优
1.num-executors
1.1、参数说明:该参数用于设置 Spark 作业总共要用多少个 Executor 进程来执行。
1.2、参数调优建议:每个 Spark 作业的运行一般设置 50~100 个左右的 Executor 进程比较
合适
2.executor-memory
2.1、参数说明:该参数用于设置每个 Executor 进程的内存。
2.2、参数调优建议:每个 Executor 进程的内存设置 4G~8G 较为合适。
3.executor-cores
3.1、参数说明:该参数用于设置每个 Executor 进程的 CPU core 数量。
3.2、参数调优建议:Executor 的 CPU core 数量设置为 2~4 个较为合适。
4.driver-memory
4.1、参数说明:该参数用于设置 Driver 进程的内存。
4.2、参数调优建议:Driver 的内存通常来说不设置,或者设置 1G 左右应该就够了。唯一需
要注意的一点是,如果需要使用 collect 算子将 RDD 的数据全部拉取到 Driver 上进行处理,
那么必须确保 Driver 的内存足够大,否则会出现 OOM 内存溢出的问题。
5.spark.default.parallelism
5.1、参数说明:该参数用于设置每个 stage 的默认 task 数量。
5.2、参数调优建议:Spark 作业的默认 task 数量为 500~1000 个较为合适。
6.spark.storage.memoryFraction
6.1、参数说明:该参数用于设置 RDD 持久化数据在 Executor 内存中能占的比例,默认是
0.6。
6.2、参数调优建议:如果 Spark 作业中,有较多的 RDD 持久化操作,该参数的值可以适当
提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只
能写入磁盘中,降低了性能。但是如果 Spark 作业中的 shuffle 类操作比较多,而持久化操作
比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的 gc 导致
运行缓慢(通过 spark web ui 可以观察到作业的 gc 耗时),意味着 task 执行用户代码的内存
不够用,那么同样建议调低这个参数的值。
7、spark.shuffle.memoryFraction
7.1、参数说明:该参数用于设置 shuffle 过程中一个 task 拉取到上个 stage 的 task 的输出
后,进行聚合操作时能够使用的 Executor 内存的比例,默认是 0.2。
7.2、如果 Spark 作业中的 RDD 持久化操作较少,shuffle 操作较多时,建议降低持久化操
作的内存占比,提高 shuffle 操作的内存占比比例,避免 shuffle 过程中数据过多时内存不够
用,必须溢写到磁盘上,降低了性能。
(三)Spark SQL
1、Spark SQL概述
1.Spark SQL是Spark用来处理结构化数据(结构化数据可以来自外部结构数据源也可以通
过RDD获取)的一个模块,它提供了一个编程抽象DataFrame并且作为分布式SQL查询引擎的
作用。
2.工作机制是将 Spark SQL 的 SQL 查询转换成 Spark Core 的应用程序,然后提交到集群
执行。
3.Spark SQL特点
3.1、容易整合
3.2、统一的数据访问方式
3.3、兼容Hive
3.4、标准的数据连接
4.Spark SQL编程
4.1、创建 SparkSession 对象,Spark-2.0.x之后找到SparkSession
4.2、通过程序入口构建一个 DataFrame 或 Dataset
4.3、在 DataFrame 或 Dataset 之上进行转换和 Action。最重要编写SQL语句。
4.4、对得到的数据结果进行处理
2、SparkSession
1.SparkSession 是 Spark-2.0 引如的新概念。SparkSession 为用户提供了统一的切入点,来
让用户学习 Spark 的各项功能。
2.在 Spark 的早期版本中,SparkContext 是 Spark RDD API的主要切入点。在 Spark2.0 中,
引入 SparkSession 作为 DataSet 和 DataFrame API 的切入点。
2.1、对于 Spark Streaming,我们需要使用 StreamingContext
2.2、对于 Spark SQL,使用 SQLContext
2.3、对于 Hive,使用 HiveContext
SparkSession 实质上是 SQLContext 和 HiveContext 的组合
3.特点
3.1、为用户通过一个统一的切入点使用Spark的各项功能
3.2、允许用户通过它调用DataFrame和Dataset相关API来编写程序
3.3、减少了用户需要了解的一些概念,可以很容易的和Spark进行交互
3.4、与Spark交互之时不需要显示的创建SparkConf、SparkContext以及SQLContext,这些
对象以及封闭在SparkSession中
3.5、SparkSession提供对Hive特征的内部支持:用HiveSQL写SQL语句,访问HDFS,从
Hive表中读取数据。
3、RDD/DataFrame/Dataset
1.RDD的局限性
1.1、RDD仅表示数据集,RDD没有元数据,也就是说没有字段语义定义
1.2、RDD需要用户自己优化程序
1.3、从不同数据源读取数据相对困难,读取到不同格式的数据都必须用户自己定义转换方
式。合并多个数据源中的数据也较困难。
2.DataFrame
1.1、DataFrame = RDD + Schema((元数据) = SchemaRDD
1.2、内部数据无类型,统一为Row
1.3、DataFrame是一种特殊类型的Dataset
1.4、DataFrame自带优化器,可以自动优化程序
1.5、DataFrame提供了一整套的Data source API
4、Dataset的产生
1.DataFrame的缺陷
1.1、Row运行时无提供编译时类型检查
1.2、Row不能直接操作domin对象
1.3、函数风格编程,没有面向对象风格的API
2.DataFrame 和 Dataset 可以采用更加通用的语言(Scala 或 Python)来表达用户的查询请
求。此外,Dataset 可以更快捕捉错误,因为 SQL 是运行时捕获异常,而 Dataset 是编译时
检查错误。
5、DataFrame常用操作
1.DSL风格语法
1.1、打印DataFrame的Schema信息
studentDF.printSchema
1.2、查看DataFrame中的所有内容
studentDF.show
1.3、查看DataFrame部分列中的内容
studentDF.select("name","age").show
studentDF.select(col("name"), col("age")).show
studentDF.select(studentDF.col("name"), studentDF.col("age")).show
1.4、查询所有的 name 和 age,并将 age+1
studentDF.select(col("id"),col("name"),col("age")+1).show
studentDF.select(studentDF ("id"), studentDF ("name"), studentDF ("age") + 1).show
1.5、过滤 age 大于等于 20 的
studentDF.filter(col("age") >= 20).show
1.6、按年龄进行分组并统计相同年龄的人数
studentDF.groupBy("age").count().show()
2.SQL风格语法
2.1、Session 范围内的临时表
studentDF.createOrReplaceTempView(“t_student”)
只在 Session 范围内有效,Session 结束临时表自动销毁
2.2、全局范围内的临时表
studentDF.createGlobalTempView(“t_student”)
所有 Session 共享
2.3、查询年龄最大的前五名
sqlContext.sql("select * from t_student order by age desc limit 5").show
2.4、显示表的 Schema 信息
sqlContext.sql("desc t_student ").show
2.5、统计学生数超过 6 个的部门和该部门的学生人数。并且按照学生的个数降序排序
sqlContext.sql("select department, count(*) as total from t_student group by department
having total > 6 order by total desc").show
(四)Spark Streaming
1、Spark Streaming概述
1.Spark Streaming用于流式数据的处理,例如实时推荐、实时网站性能分析等
2.特点
2.1、高吞吐量
2.2、容错能力强
2.3、支持的数据输入源很多
2.4、结果能保存在很多地方
3.处理机制
接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine
处理这些批数据,最终得到处理后的y一批批结果数据。对应的批数据,在Spark内核对应一
个RDD实例,因此,对应流的DStream可以看出是一组RDDs,即RDD的一个序列。
总结:Spark Streaming 的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然
后以类似批处理的方式处理每个时间片数据。
2、Spark Streaming核心术语
1.离散流或DStream
这是对Spark Streaming对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据
流,在Spark Streaming中对应着一个DStream实例。
2.批数据
这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数
据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
3.时间片或批处理时间间隔
这是人为的对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的
数据对应一个RDD实例。
4.窗口长度
一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数。
5.滑动时间间隔
前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。
6.Input DStream
一个Input DStream是一个特殊的DStream,将Spark Streaming连接到一个外部数据源来读
取数据。
3、DStream相关操作
1.特殊的Transformations
1.1、UpdateStateByKey Operation
UpdateStateByKey Operation原语用于记录历史记录。若不用UpdateStateByKey 来更新
状态,那么每次数据进来后分析完成后,结果输出后将不再保存。
要使用此功能,必须进行以下两个步骤:
(1)定义状态-状态可以是任意的数据类型
(2)定义状态更新函数-用一个函数指定如何使用先前的状态和从输入流中获取的新值更
新状态。
1.2、Transform Operation
Transfrom原语允许DStream上执行任意的RDD-to-RDD函数。通过该函数可以方便的扩
展Spark API。此外,机器学习以及图计算也是通过本函数来结合的。
1.3、Window Operations
Window Operations类似于Storm中的state,可以设置窗口的大小和滑动窗口的间隔来动
态的获取当前Streaming的状态。
在Spark Streaming中,数据处理是按批处理的,而数据采集是逐条进行的,因此会先设
置好批处理间隔,当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给
系统去处理。
例如,批处理间隔是 1 个时间单位,窗口间隔是 3 个时间单位,滑动间隔是 2 个时间单
位。对于初始的窗口 time 1-time 3,只有窗口间隔满足了才触发数据的处理。这里需要注意
的一点是,初始的窗口有可能流入的数据没有撑满,但是随着时间的推进,窗口最终会被撑
满。当每隔 2 个时间单位,窗口滑动一次后,会有新的数据流入窗口,这时窗口会移去最早
的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成新的窗口(time3-
time5)。
2.Output Operations
Output Operations 可以将 DStream 的数据输出到外部的数据库或文件系统,当某个 Output
Operations 原语被调用时(与 RDD 的 Action 相同),Streaming 程序才会开始真正的计算过
程。
4、Spark Streaming编程步骤
1.创建完成 StreamingContext
2.通过输入源创建Input DStream
3.对DStream进行Transformation和output操作,这样构成了后期流式计算的逻辑
4.通过streamingContext.start()方法启动接收和处理数据的流程
5.使用 streamingContext.awaitTermination()方法等待程序结束(手动停止或出错停止)
6.也可以调用 streamingContext.stop()方法结束程序的运行
关于StreamingContext值得注意:
(1)在StreamingContext启动之前,要定义好所有的计算逻辑。启动后,增加新的操作不
起作用。停止后,不能重新启动,若要重新计算,需要重新运行整个程序。
(2)在单个JVM中,一段时间内不能出现两个active状态的StreamingContext。
(3)当在调用streamingContext的stop方法时,默认情况下sparkContext也会被停止掉。如
果希望保留sparkCOntext,则需要在stop方法中传入参数stopSparkContext=false。
(4)一个SparkContext可以创建多个StreamingContext,只要前一个StreamingContext已
经停止了。
5、InputDStreams和Receivers
1.InputDStream指的是从数据流的源头接受的输入数据流。除文件流外,每个InputDStream都
关联着一个Receiver对象,该Receiver对象接受数据源传来的数据并将其保持在内存中以便后
期Spark处理。
2.SparkStreaming支持的流数据源
2.1、basic sources(基础流数据源)
直接通过API创建,例如文件系统、sosocket连接以及akka的Actor
2.2、advanced sources(高级流数据源)
如kafka、flume等,需要借助外部工具类
2.3、custom sources(自定义流数据源)
用户自定义receivers
3.注意
3.1、在本地运行Spark Streaming应用程序时,要使用‘local【n】’作为master url,n要大于
receivers都是数量。receivers自身就需要一个线程来运行。
3.2、在集群上运行Spark Streaming时,分配给程序的CPU核数也必须大于receivers的数
量,否则系统将只接受数据,无法处理数据。
(五)Kafka
1.JMS 规范是什么
(1)JMS 的基础
JMS 是什么:JMS 是 Java 提供的一套技术规范,即 Java 消息服务(Java Message Service)应用程序接口。是一个 Java 平台中关于面向消息中间件
的 API。用于在两个应用程序之间或分布式系统中发送消息,进行异步通信。Java 消息服务是一个与具体平台无关的 API
JMS 干什么用:用来异构系统集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活
通过什么方式:生产消费者模式(生产者、服务器、消费者)通常消息传递有两种类型的消息模式可用一种是点对点 queue 队列模式(p2p),
另一种是 topic 发布-订阅模式(public-subscribe)
(2)JMS 消息传输模型
1、点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的
消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
2、发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者
则监听主题的所有消息,即时当前订阅者不可用,处于离线状态
(3)JMS 核心组件
1、Destination:消息发送的目的地,也就是前面说的 Queue 和 Topic
2、Message:从字面上就可以看出是被发送的消息
a、StreamMessage:Java 数据流消息,用标准流操作来顺序的填充和读取
b、MapMessage:一个 Map 类型的消息;名称为 string 类型,而值为 Java 的基本类型
c、TextMessage:普通字符串消息,包含一个 String
d、ObjectMessage:对象消息,包含一个可序列化的 Java 对象
e、BytesMessage:二进制数组消息,包含一个 byte[]
f、XMLMessage: 一个 XML 类型的消息
最常用的是 TextMessage 和 ObjectMessage
3、Producer:消息的生产者,要发送一个消息,必须通过这个生产者来发送
4、MessageConsumer:与生产者相对应,这是消息的消费者或接收者,通过它来接收一个消息
5、通过与 ConnectionFactory 可以获得一个 connection
6、通过 connection 可以获得一个 session 会话
(4)常见的类 JMS 消息服务器
1、JMS 消息服务器 ActiveMQ
ActiveMQ 是 Apache 出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持 JMS1.1 和 J2EE 1.4 规范的
主要特点:
a、多种语言和协议编写客户端。语言: Java, C, C++, C#, Ruby, Perl, Python, PHP。应用协议:OpenWire,Stomp REST,WS Notification,XMPP,AMQP
b、完全支持 JMS1.1 和 J2EE 1.4 规范 (持久化,XA 消息,事务)
c、对 Spring 的支持,ActiveMQ 可以很容易内嵌到使用 Spring 的系统里面去,而且也支持Spring2.0 的特性
d、 通过了常见 J2EE 服务器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors 的配置,可以让 ActiveMQ
可以自动的部署到任何兼容 J2EE 1.4商业服务器上可以自动的部署到任何兼容 J2EE 1.4商业服务器上
e、支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
f、 支持通过 JDBC 和 journal 提供高速的消息持久化
g、 从设计上保证了高性能的集群,客户端-服务器,点对点
h、 支持 Ajax
i、 支持与 Axis 的整合
j、 可以很容易得调用内嵌 JMS provider 进行测试
2、分布式消息中间件 Metamorphosis
Metamorphosis(MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于 LinkedIn的 Kafka,具有消息存储顺序写、吞吐量大和支持本地
和 XA 事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源
主要特点:
a、生产者、服务器和消费者都可分布
b、消息存储顺序写
c、性能极高,吞吐量大
d、支持消息顺序
e、支持本地和 XA 事务
f、客户端 pull,随机读,利用 sendfile 系统调用,zero-copy ,批量拉数据
i、支持消费端事务
j、支持消息广播模式
k、支持异步发送消息
l、支持 http 协议
m、支持消息重试和 recover
n、数据迁移、扩容对用户透明
o、消费状态保存在客户端
p、支持同步和异步复制两种 HA
q、支持 group commit
3、分布式消息中间件 RocketMQ
RocketMQ 是一款分布式、队列模型的消息中间件
主要特点:
a、能够保证严格的消息顺序
b、提供丰富的消息拉取模式
c、高效的订阅者水平扩展能力
d、实时的消息订阅机制
e、亿级消息堆积能力
f、Metaq3.0 版本改名,产品名称改为 RocketMQ
4、其他 MQ
a、.NET 消息中间件 DotNetMQ
b、基于 HBase 的消息队列 HQueue
c、Go 的 MQ 框架 KiteQ
d、AMQP 消息服务器 RabbitMQ
e、MemcacheQ 是一个基于 MemcacheDB 的消息队列服务器
2.为什么需要消息队列
消息系统的核心作用就是三点:解耦,异步和并行
(1)用户注册的一般流程
用户注册---》发新手红包---》准备支付宝账号---》进行合法性验证---》通知SNS
问题:随着后端流程越来越多,每步流程都需要额外的耗费很多时间,从而会导致用户更长的等待延迟。
(2)用户注册的并行执行
用户注册---》发新手红包,准备支付宝账号,进行合法性验证,通知SNS
问题:系统并行的发起了 4 个请求,4 个请求中,如果某一个环节执行 1 分钟,其他环节再快,用户也需要等待 1 分钟。如果其中一个环节异常之后,整个服务挂掉了
(3)用户注册的最终一致
发送消息---》用户注册
1、 保证主流程的正常执行、执行成功之后,发送 MQ 消息出去。
2、 需要这个 destination 的其他系统通过消费数据再执行,最终一致。
消息队列投递---》发新手红包,准备支付宝账号,进行合法性验证,通知SNS
3.Kafka 的优点
(1)解耦
(2)冗余
(3)扩展性
(4)灵活性 & 峰值处理能力
(5)可恢复性
(6)顺序保证
(7)缓冲
(8)异步通信
4.Kafka 是什么
(1)Kafka 概述
1、在流式计算中,Kafka 一般用来缓存数据,Storm 通过消费 Kafka 的数据进行计算。经典架构:Flume + Kafka + Storm + Redis
2、Apache Kafka 最初是是由 LinkedIn 开发的一个基于发布订阅的分布式的消息系统,由 Scala编写,并于 2011 年初开源
3、Kafka 是一个分布式消息队列:具有生产者、消费者的功能。它提供了类似于 JMS 的特性,但是在设计实现上完全不同,此外它并不是 JMS 规范的实现
4、Kafka 对消息保存时根据 Topic 进行归类,发送消息者称为 Producer,消息接受者称为Consumer,此外 Kafka 集群有多个 Kafka 实例组成,每个实例(server)成为 broker。
5、无论是Kafka集群,还是Producer和Consumer都依赖于ZooKeeper集群保存一些meta信息,来保证系统可用性
(2)Kafka 特性
1、高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个 topic可以分多个 partition,consumer group 对 partition 进行消费操作
2、可扩展性:kafka 集群支持热扩展
3、持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
4、容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)
5、高并发:支持数千个客户端同时读写
5.Kafka 的应用场景
(1)消息系统
(2)跟踪网站活动
(3)运营指标
(4)日志聚合
(5)流处理
(6)采集日志
(7)提交日志
6.Kafka 核心组件
(1)工作模式
Kafka 是 LinkedIn 用于日志处理的分布式消息队列,同时支持离线和在线日志处理。
发送消息者就是 Producer,消息的发布描述为 Producer
消息接受者就是 Consumer,消息的订阅描述为 Consumer
每个 Kafka 实例称为 Broker,将中间的存储阵列称作 Broker(代理)
Kafka 的大致工作模式:
1、启动 ZooKeeper 的 server
2、启动 Kafka 的 server
3、Producer 生产数据,然后通过 ZooKeeper 找到 Broker,再将数据 push 到 Broker 保存
4、Consumer 通过 ZooKeeper 找到 Broker,然后再主动 pull 数据
(2)Kafka 的核心概念详解
1、Broker:Kafka 节点,一个 Kafka 节点就是一个 broker,多个 broker 可以组成一个 Kafka 集群。
2、Topic:一类消息,消息存放的目录即主题,例如 page view 日志、click 日志等都可以以 topic的形式存在,Kafka 集群能够同时负责多个 topic 的分发。
3、Partition:topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列
每个分区其实都是有序且顺序不可变的记录集,并且不断地追加到结构化的 commit log 文件。
4、Segment:partition 物理上由多个 segment 组成,每个 Segment 存着 message 信息
5、Producer : 生产 message 发送到 topic
6、Consumer : 订阅 topic 消费 message,consumer 作为一个线程来消费
a、 一个 Partition 的消息只会被 group 中的一个 Consumer 消费
b、 可以认为一个 group 就是一个“订阅者”
c、 一个 Topic 中的每个 Partition 只会被一个“订阅者”中的一个 Consumer 消费
7、Consumer Group:一个 Consumer Group 包含多个 consumer,这个是预先在配置文件中配置好的
一般来说:
a、一个 Topic 的 Partition 数量大于等于 Broker 的数量,可以提高吞吐率。
b、同一个 Partition 的 Replica 尽量分散到不同的机器,高可用。
(六)Storm
1.概述
Apache Storm 是一个 Twitter 开源的分布式、实时、可扩展、容错的计算系统。Apache Storm可以很容易做到可靠地处理无限的数据流,
像 Hadoop 批量处理大数据一样。Storm 处理速度很快,每个节点每秒钟可以处理超过百万的数据组。
常用于:实时分析、在线机器学习、持续计算、分布式 RPC、ETL 等等。
特点:快、可扩展、容错性、保证数据都能够被处理
2.集群架构
Apache Storm 分布式集群主要节点由控制节点(Nimbus 节点)和工作节点(Supervisor 节点),控制节点可以一个,工作节点多个组成的,
而 Zookeeper 主要负责 Nimbus 节点和 Supervisor节点之间的协调工作。
(1)Nimbus:即 Storm 的 Master,负责资源分配和任务调度。一个 Storm 集群只有一个 Nimbus。
(2)Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个 Worker 进程。
(3)Worker:进程,拓扑运行在一个或者多个 worker 上,每一 worker 是一个独立的 JVM 进程,进程里面包含一个或者多个 executor(线程),
一个线程会处理一个或者多个 Task(任务)。Config.TOPOLOGY_WORKERS 设置 worker 数量。
(4)Task:任务,在 Storm 集群中每个 Spout 或者 Bolt 对应多个 Task 来执行,每个任务都与一个执行线程相对应。Spout 或者 Bolt 设置多个并行度(setSpout/setBolt),
就有对应的多个 Task,Spout 的 nextTuple()或者 bolt 的 execute()会被执行。
(5)ZooKeeper:Storm 的集群的状态信息(Nimbus 分发的任务Supervisor、worker 的心跳等)都保存在 Zookeeper 上,通过 zookeeper 的分布式系统
协调来保证 Storm 集群的稳定性
3.核心概念
Apache Storm 是一个开源的分布式、实时计算应用,实时计算应用它是由 Topology、Stream、Spout、Bolt、Stream grouping 等元素组成的。
(1)Topology
Storm 的 Topology 是一个分布式实时计算应用、计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,
区别在于 MapReduce 的一个Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它 kill(stormkill topology-name [-w wait-time-secs])。
拓扑还可以理解成由一系列通过数据流(StreamGrouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构
拓扑运行模式:本地模式和分布式模式
运行一个拓扑只要把代码打包成一个 jar,然后在 storm 集群环境下,执行命令storm jar topology-jar-path class........
(2)Streams
Streams 是 storm 最核心的抽象概念,一个 Stream 是分布式环境中并行创建和处理的一个没有边界的 tuple 序列,Streams 是由 Tuple(元组)组成的,
Streams 是 storm 最核心的抽象概念,一个 Stream 是分布式环境中并行创建和处理的一个没有边界的 tuple 序列,Streams 是由 Tuple(元组)组成的,
Tuple 支持的类型有 Integer、Long、Short、Byte、String、Double、Float、Boolean、Byte Arrays
当然,Tuple 也支持可序列化的对象。
数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
(3)Spouts 数据源
Spout 是拓扑的数据流的源头,Spout 不断的从外部读取数据(数据库、kafka 等外部资源),并发送到拓扑中进行实时的处理
Spout是主动模式,Spout继承 BaseRichSpout或者实现 IRichSpout接口不断的调用nextTuple()函数,然后通过 emit 发送数据流。
(4)Bolts
Bolt 接收 Spout 或者上游的 Bolt 发来的 Tuple(数据流),拓扑中所有的数据处理均是由 Bolt完成的。通过数据过滤(filter)、函数处理(function)、
聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,
而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
Bolt 是被动模式,Bolt 继承 BaseBasicBolt 类或者实现 IRichBolt 接口等来实现,当 Bolt 接收Spout 或者上游的 Bolt 发来的 Tuple(数据流)时调用 execute 方法,
并对数据流进行处理完,OutputCollector 的 emit 发送数据流,execute 方法在 Bolt 中负责接收数据流和发送数据流。
(5)Stream Grouping
Storm 是通过 Stream Grouping 把 spouts 和 Bolts 串联起来组成了流数据处理结构
八种数据流分组方式:
1、Shuffle grouping(随机分组)
2、Fields grouping(字段分组)
3、Partial Key grouping(部分字段分组)
4、All grouping(完全分组)
5、Global grouping(全局分组)
6、None grouping(无分组)
7、Direct grouping(直接分组)
8、Local or shuffle grouping(本地或随机分组)
4.并行度分析
Topology 主要是由 Worker、Executor、Task 组成的、Topology 对应一个或者多个 worker(是一个独立的 JVM 进程),worker 下又有多个 Executor 线程,
Executor 下对应一个或者多个Task,默认情况下一个 Executor 对应一个 Task(spout/bolt),这些 Task 都是同一个 spout/bolt组件。
我们在创建拓扑时,并配置 Worker 的数量、Executor 数量、Task 数量,也就是并行度,提高拓扑的并行度,能提高拓扑的计算能力。
说明:
Worker 数量:conf.setNumWorkers(num) /Config.TOPOLOGY_WORKERS
Executor 数量:builder.setBolt()/builder.setSpout()
Task 数量:builder.setBolt().setNumTasks(val)
(七)Scala
1.概述
(1)什么是 Scala
Scala 是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。
Scala(Scala Language 的简称)语言是一种能够运行于 JVM和.Net 平台之上的通用编程语言,既可用于大规模应用程序开发,也可用于脚本编程
(2)为什么要学 Scala
基于编程语言自身:
1、 优雅
2、 速度快
3、 能融合到 Hadoop 生态圈
基于活跃度:
1、作为流行的开源大数据内存计算引擎的源码编程语--Spark 有着良好的性能优势
2、Scala 将成为未来大数据处理的主流语言
3、最新 TIOBE 编程语言排行榜--Scala 进入前 20
2.Scala 函数式编程特点
(1)高阶函数(Higher-order functions)
(2)闭包(closures)
(3)模式匹配(Pattern matching)
(4)单一赋值(Single assignment)
(5)延迟计算(Lazy evaluation)
(6)类型推导(Type inference)
(7)尾部调用优化(Tail call optimization)
(8)类型推导(Type inference)
(八)RPC
**Java RPC**
1.概念
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
RPC 跨越了传输层和应用层。
第一层:应用层。定义了用于在网络中进行通信和传输数据的接口;
第二层:表示层。定义不同的系统中数据的传输格式,编码和解码规范等;
第三层:会话层。管理用户的会话,控制用户间逻辑连接的建立和中断;
第四层:传输层。管理着网络中的端到端的数据传输;
第五层:网络层。定义网络设备间如何传输数据;
第六层:链路层。将上面的网络层的数据包封装成数据帧,便于物理层传输;
第七层:物理层。这一层主要就是传输这些二进制数据。
实际应用过程中,五层协议结构里面是没有表示层和会话层的。应该说它们和应用层合并了。
我们应该将重点放在应用层和传输层这两个层面。因为 HTTP 是应用层协议,而 TCP 是传输层协议。
RPC 采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。
通俗的说: RPC 是指远程过程调用,也就是说两台服务器 A,B,一个应用部署在 A 服务器,想要调用 B 服务器提供的函数和方法,由于不在一个内存空间,
不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。也可以理解成不同进程之间的服务调用
(1)要解决通讯的问题,主要是通过在客户端和服务器之间建立 TCP 连接,远程过程调用的所有交换的数据都在这个连接里传输
(2)要解决寻址的问题,也就是说,A 服务器上的应用怎么告诉底层的 RPC 框架,如何连接到 B 服务器(如主机或 IP 地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。
(3)当 A 服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP 传递到 B 服务器,通过寻址和传输将序列化的二进制发送给 B 服务器
(4)第四,B 服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
(5)第五,返回值还要发送回服务器 A 上的应用,也要经过序列化的方式发送,服务器 A 接到后,再反序列化,恢复为内存中的表达方式,交给 A 服务器上的应用
2.为什么要有 RPC
RPC 框架的职责是:让调用方感觉就像调用本地函数一样调用远端函数、让服务提供方感觉就像实现一个本地函数一样来实现服务,并且屏蔽编程语言的差异性。
RPC 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。
简单的讲,对于客户端 A 来说,调用远程服务器 B 上的服务,就跟调用 A 上的自身服务一样。因为在客户端 A 上来说,会生成一个服务器 B 的代理。
3.Java 中流行的 RPC 框架
(1)RMI(远程方法调用)
(2)Hessian(基于 HTTP 的远程方法调用)
(3)Dubbo(阿里开源的基于 TCP 的 RPC 框架)
**Hadoop RPC**
1.概述
Hadoop RPC 分为四个部分:
(1)序列化层:Client 与 Server 端通信传递的信息采用了 Hadoop 里提供的序列化类或自定义的 Writable 类型;
(2)函数调用层:Hadoop RPC 通过动态代理以及 Java 反射实现函数调用;
(3)网络传输层:Hadoop RPC 采用了基于 TCP/IP 的 socket 机制;
(4)服务器端框架层:RPC Server利用Java NIO以及采用了事件驱动的I/O模型,提高RPC Server的并发处理能力;
2.涉及的技术
(1)代理
(2)反射----动态加载类
(3)序列化
(4)非阻塞的异步 IO(NIO)
3.对外提供的接口
(1)public static ProtocolProxy getProxy/waitForProxy(…)
构造一个客户端代理对象(该对象实现了某个协议),用于向服务器发送 RPC 请求。
(2)public static Server RPC.Builder (Configuration).build()
为某个协议(实际上是 Java 接口)实例构造一个服务器对象,用于处理客户端发送的请求。
4.使用 Hadoop RPC 构建应用的步骤
(1)定义 RPC 协议
RPC 协议是客户端和服务器端之间的通信接口,它定义了服务器端对外提供的服务接口。
(2)实现 RPC 协议
Hadoop RPC 协议通常是一个 Java 接口,用户需要实现该接口。
(3)构造和启动 RPC SERVER
直接使用静态类 Builder 构造一个 RPC Server,并调用函数 start()启动该 Server。
(4)构造 RPC Client 并发送请求
使用静态方法 getProxy 构造客户端代理对象,直接通过代理对象调用远程端的方法。
**Scala Actor**
1.概念
Scala 中的 Actor 能够实现并行编程的强大功能,它是基于事件模型的并发机制,Scala 是运用消息(message)的发送、接收来实现多线程的。使用 Scala 能够更容易地实现多线程应用的开发。
2.Actor 方法执行顺序
(1)首先调用 start()方法启动 Actor
(2)调用 start()方法后其 act()方法会被执行
(3)向 Actor 发送消息
**Akka Actor**
1.概述
Akka 基于 Actor 模型,提供了一个用于构建可扩展的(Scalable)、弹性的(Resilient)、快速响应的(Responsive)应用程序的平台。
Actor 模型是一个并行计算(Concurrent Computation)模型,它把 actor 作为并行计算的基本元素来对待:为响应一个接收到的消息,一个 actor 能够自己做出一些决策,如创建更多的 actor,或发送更多的消息,或者确定如何去响应接收到的下一个消息。
Actor 是 Akka 中最核心的概念,它是一个封装了状态和行为的对象,Actor 之间可以通过交换消息的方式进行通信,每个 Actor 都有自己的收件箱(Mailbox)。通过 Actor 能够简化锁及线程管理,可以非常容易地开发出正确地并发程序和并行系统
Actor 具有如下特性:
(1)提供了一种高级抽象,能够简化在并发(Concurrency)/并行(Parallelism)应用场景下的编程开发
(2)提供了异步非阻塞的、高性能的事件驱动编程模型
(3)超级轻量级事件处理(每 GB 堆内存几百万 Actor)
重要的生命周期方法:
(1)preStart()方法:该方法在 Actor 对象构造方法执行后执行,整个 Actor 生命周期中仅执行一次。
(2)receive()方法:该方法在 Actor 的 preStart 方法执行完成后执行,用于接收消息,会被反复执行。
Spark 的 RPC 是通过 Akka 类库实现的,Akka 用 Scala 语言开发,基于 Actor 并发模型实现,Akka 具有高可靠、高性能、可扩展等特点,使用 Akka 可以轻松实现分布式 RPC 功能。
(九)JVM
1.JVM 的组织结构
(1)JVM 组织关系
1、类加载器(ClassLoader):在 JVM 启动时或者在类运行时将需要的 class 加载到 JVM 中
2、执行引擎:负责执行 class 文件中包含的字节码指令
3、内存区(也叫运行时数据区):是在 JVM 运行的时候操作所分配的内存区。运行时内存区主要可以划分为 5 个区域
4、本地方法接口:主要是调用 C 或 C++实现的本地方法及返回结果。
方法区和堆是所有线程共享的内存区域;
而 Java 栈、本地方法栈和程序员计数器是运行时线程私有的内存区域。
(2)JVM 内存结构
JVM 内存结构主要有三大块:堆内存、方法区和栈
堆内存是 JVM 中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor 空间、To Survivor 空间,默认情况下年轻代按照 8:1:1 的比例来分配方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与 Java 堆区分,方法区还有一个别名 Non-Heap(非堆)
栈又分为 Java 虚拟机栈和本地方法栈和程序计数器,主要用于方法的执行
(3)控制参数
-Xms 设置堆的最小空间大小
-Xmx 设置堆的最大空间大小
-XX:NewSize 设置新生代最小空间大小
-XX:MaxNewSize 设置新生代最大空间大小
-XX:PermSize 设置永久代最小空间大小
-XX:MaxPermSize 设置永久代最大空间大小
-Xss 设置每个线程的堆栈大小
没有直接设置老年代的参数,但是可以设置堆空间大小和新生代空间大小两个参数来间接控制:老年代空间大小=堆空间大小-年轻代大空间大小
2.JVM 各区域的作用
(1)Java 堆(Heap)
对于大多数应用来说,Java 堆(Java Heap)是 Java 虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”。
Java 堆中还可以细分为:新生代和年老代;再细致一点话,新生代又分为 Eden 空间、From Survivor 空间、To Survivor空间等。
根据 Java 虚拟机规范的规定,Java 堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx 和-Xms 控制)。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出 OutOfMemoryError异常
(2)方法区(Method Area)
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
根据 Java 虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出 OutOfMemoryError异常。
(3)程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域
(4)Java 虚拟机栈(JVM Stacks)
Java 虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是 Java 方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
在 Java 虚拟机规范中,对这个区域规定了两种异常状况:
1、如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;
2、如果虚拟机栈可以动态扩展(当前大部分的 Java 虚拟机都可动态扩展,只不过 Java 虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError 异常。
(5)本地方法栈(Native Method Stacks)
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是
Java 虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的 Native 方法服务。
3.JVM 垃圾回收
(1)概述
JVM 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 Java 堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的。
(2)垃圾收集器(Garbage Collector (GC))
GC 其实是一种自动的内存管理工具,其行为主要包括 2 步
1、在 Java 堆中,为新创建的对象分配空间
2、在 Java 堆中,回收没用的对象占用的空间
(3)为什么需要 GC?
应用程序的回收目标是构建一个仅用来处理内存分配,而不执行任何真正的内存回收操作的GC。即仅当可用的 Java 堆耗尽的时候,才进行顺序的 JVM 停顿操作。
(4)为什么需要多种 GC?
首先,Java 平台被部署在各种各样的硬件资源上,其次,在 Java 平台上部署和运行着各种各样的应用,并且用户对不同的应用的性能指标(吞吐率和延迟)预期也不同,为了满足不同应用的对内存管理的不同需求
性能指标:
最大停顿时长:垃圾回收导致的应用停顿时间的最大值
吞吐率:垃圾回收停顿时长和应用运行总时长的比例
现有的 GC 包括:
1、序列化 GC(serial garbage collector):适合占用内存少的应用
2、并行 GC 或吞吐率 GC(Parallel or throughput Garbage Collector):适合占用内存较多,多CPU,追求高吞吐率的应用
3、并发 GC:适合占用内存较多,多 CPU 的应用,对延迟有要求的应用
(5)对象存活的判断
两种方式:
1、引用计数:每个对象有一个引用计数属性,新增一个引用时计数加 1,引用释放时计数减 1,计数为 0 时可以回收。此方法简单,缺点是无法解决对象相互循环引用的问题。
2、可达性分析(Reachability Analysis):从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的不可达对象。可解决对象相互循环引用的问题。
GC Roots 包括:
1、虚拟机栈中引用的对象
2、方法区中类静态属性实体引用的对象
3、方法区中常量引用的对象
4、本地方法栈中 JNI 引用的对象
(6)并发和并行
并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个 CPU 上。
(7)Minor GC 和 Full GC
新生代 GC(Minor GC):指发生在新生代的垃圾收集动作,因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
老年代 GC(Major GC / Full GC):指发生在老年代的 GC,出现了 Major GC,经常会伴随至少一次的 Minor GC(但非绝对的,在 Parallel Scavenge 收集器的收集策略里就有直接进行Major GC 的策略选择过程)。Major GC 的速度一般会比 Minor GC 慢 10 倍以上。
(8)垃圾回收算法
1、标记-清除算法
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
它的主要缺点有两个:
a、一个是效率问题,标记和清除过程的效率都不高;
b、另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2、复制算法
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
算法的代价是将内存缩小为原来的一半,持续复制长生存期的对象则导致效率降低。
在对象存活率较高时就要执行较多的复制操作,效率将会变低。在老年代一般不能直接选用这种算法。
3、标记-整理算法
标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
4、分代收集算法
“分代收集”(Generational Collection)算法,把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
新生代:存活对象数量少,复制算法
年老代:对象存活率高,标记-清除 或者 标记-整理
(9)垃圾收集器
收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现
1、Serial 收集器
串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会 Stop The World(服务暂停)
总结:单线程的 STW 模式
2、ParNew 收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本。
新生代并行,老年代串行;新生代复制算法、老年代标记-整理
总结:Serial 收集器的多线程版本
3、Parallel 收集器
Parallel 收集器更关注系统的吞吐量
吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总共运行了 100 分钟,其中垃圾收集花掉 1 分钟,那吞吐量就是 99%。
总结:关注吞吐量的多线程 ParNew 进化版
4、CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器
CMS 收集器是基于“标记-清除”算法实现的
运作过程:
a、初始标记(CMS initial mark)
b、并发标记(CMS concurrent mark)
c、重新标记(CMS remark)
d、并发清除(CMS concurrent sweep)
CMS 收集器的内存回收过程是与用户线程一起并发地执行
优点:并发收集、低停顿
缺点:产生大量空间碎片、并发阶段会降低吞吐量
总结:追求最短回收停顿时间的业务线程和 GC 线程并行运行的垃圾收集器
5、G1 收集器
与 CMS 收集器相比 G1 收集器有以下特点:
a、空间整合,G1 收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次 GC。
b、G1除了追求低停顿外,还能建立可预测的停顿时间模型
使用G1 收集器时,Java 堆的内存布局与其他收集器有很大差别,它将整个 Java 堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region 的集合。G1 的新生代收集跟 ParNew 类似,当新生代占用达到一定比例的时候,开始触发收集