本篇分享讲爬取中国高校排名前100名并将其写入MySQL,这样做的好处是:1.将数据存入数据库,能永久利用;2.能利用数据库技术做一些其他操作。爬取的网页是:http://gaokao.xdf.cn/201702/10612921.html
1. 环境:
- windows10
- python3
- mysql 5.7
2.开始
安装各个模块:
pip install bs4
pip install pymysql
导入:
import bs4
import pymysql
import urllib.request
from bs4 import BeautifulSoup
先利用urllib和BeautifulSoup爬取前100名的表格,返回list形式,再利用MySQLdb将list写入数据中,其代码如下:
def get_html(url):
html = urllib.request.urlopen(url)
content = html.read()
html.close()
soup = BeautifulSoup(content, "lxml")
table = soup.find('tbody')
count = 0
lst = []
for tr in table.children:
if isinstance(tr, bs4.element.Tag):
td = tr('td')
if count >= 2:
lst.append([td[i]('p')[0].string.replace('\n','').replace('\t','') for i in range(8) if i != 3])
count += 1
return lst
在mysql数据库中建立数据库:gaoxiao
该段代码实现了爬取中国高校前100名的表格,并保留了名次、学校名称、地区、总分、办学类型、星级排名、办学层次这7个字段。其中的url即为开始提到的网站网址。
url = 'http://gaokao.xdf.cn/201702/10612921.html'
universities_lst = get_html(url)
name = 'root'
password = '123456' #替换为自己的用户名和密码
# 打开数据库连接
db = pymysql.connect('localhost', name, password, 'gaoxiao', charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 使用execute方法执行SQL语句创建表
cursor.execute("""create table university_rank(排名 int(3),高校 varchar(20),地区 varchar(10),总分 decimal(9,2),办学类型 varchar(10),
星级排名 varchar(8),办学层次 varchar(40)) default charset = utf8""")
for x in universities_lst:
sql = "insert into university_rank values('%s','%s','%s','%s','%s','%s','%s')"%(x[0],x[1],x[2],x[3],x[4],x[5],x[6])
cursor.execute(sql)
db.commit()
# 关闭数据库连接
db.close()
print("Create table already! Please check Mysql!")
该段代码将上述爬取的表格写入MySQL数据库中,先新建一张university_rank表格,再将值插入。我们可以去MySQL中查看。
也可以打开:MySQL Command Line Client:
输入:
use gaoxiao #gaoxiao是数据库的名称
在输入:
select * from university_rank; #university_rank为表名称
结果:

图片.png
这说明我们确实将爬取的高校排名写入了MySQL,接下来我们就只需要对数据库进行操作了,比如说我想知道在这前100中,每个省份的学校数量,可以通过以下命令实现:
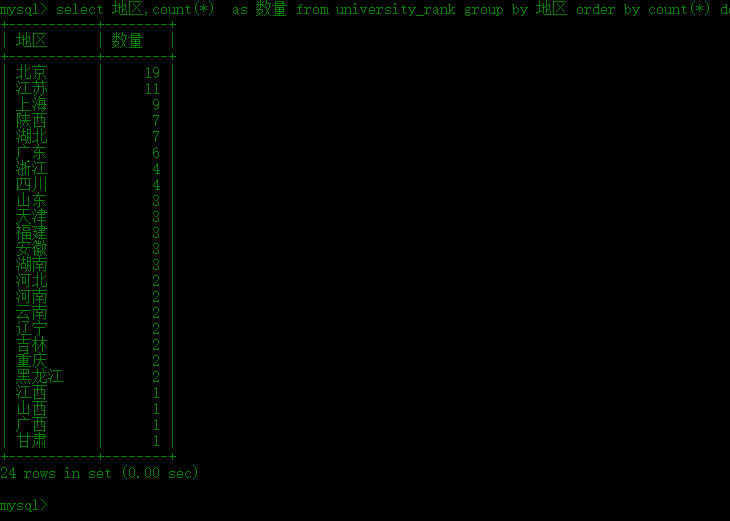
select 地区,count(*) as 数量 from university_rank group by 地区 order by count(*) desc;
结果:
图片.png
从中我们可以,前100名中的高校中,北京最多,有19所,江苏其次,11所,上海第三,有9所。当然,我们还可以用该数据库做一些其他有趣的事情~~
P.S.附上本篇分享的整个程序:
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 29 16:13:29 2017
@author: JayMo
"""
import bs4
import pymysql
import urllib.request
from bs4 import BeautifulSoup
#先利用urllib和BeautifulSoup爬取前100名的表格,返回list形式,再利用MySQLdb将list写入数据中
def get_html(url):
html = urllib.request.urlopen(url)
content = html.read()
html.close()
soup = BeautifulSoup(content, "lxml")
table = soup.find('tbody')
count = 0
lst = []
for tr in table.children:
if isinstance(tr, bs4.element.Tag):
td = tr('td')
if count >= 2:
lst.append([td[i]('p')[0].string.replace('\n','').replace('\t','') for i in range(8) if i != 3])
count += 1
print(lst)
return lst
url = 'http://gaokao.xdf.cn/201702/10612921.html'
universities_lst = get_html(url)
name = 'root'
password = '123456' #替换为自己的用户名和密码
# 打开数据库连接
db = pymysql.connect('localhost', name, password, 'gaoxiao', charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 使用execute方法执行SQL语句创建表
cursor.execute("""create table university_rank(排名 int(3),高校 varchar(20),地区 varchar(10),总分 decimal(9,2),办学类型 varchar(10),
星级排名 varchar(8),办学层次 varchar(40)) default charset = utf8""")
for x in universities_lst:
sql = "insert into university_rank values('%s','%s','%s','%s','%s','%s','%s')"%(x[0],x[1],x[2],x[3],x[4],x[5],x[6])
cursor.execute(sql)
db.commit()
# 关闭数据库连接
db.close()
print("Create table already! Please check Mysql!")