C++中STL容器总结
STL容器
- 1、容器分类
- 2、顺序型容器
- 2.1 vector容器
- 2.2 list容器
- 2.3 deque容器
- 3、有序关联容器
- 3.1 set(集合)和 multiset(多重集合)
- 3.2 map(映射)和multimap(多重映射)
- 4、无序关联容器
- 4.1 unordered_map/unordered_multimap
- 4.2 unordered_set/unordered_multiset
- 5、容器适配器
- 5.1 stack容器
- 5.2 queue容器
- 5.3 priority_queue容器
整理博客不易,如果本文对你有所帮助,请给博主 点赞 + 收藏 + 关注!谢谢!
1、容器分类
STL中通常将容器分为三类:顺序容器、关联容器和容器适配器。
1、顺序容器
是一种各元素之间有顺序关系的线性表,是一种线性结构的可序群集。顺序性容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。顺序容器的元素排列次序与元素值无关,而是由元素添加到容器里的次序决定。
顺序容器包括:
vector(向量)、list(列表)、deque(队列)。
2、关联容器
关联式容器是非线性的树结构,更准确的说是二叉树结构。排序的容器底层是通过红黑树实现的,散列的是通过哈希表实现的。
关联容器可分为两类:
(1)有序的:map(集合)、set(映射)、multimap(多重集合)、multiset(多重映射)。
(2)无序的:unordered_map、unordered_set、unordered_multimap、unordered_multiset
3、容器适配器
C++提供了三种容器适配器(container adapter):stack,queue和priority_queue。stack和queue基于deque实现,priority_queue基于vector实现。
适配器包括:
stack(栈) 、queue(队列) 、priority_queue(优先级队列) 。
容器类自动申请和释放内存,因此无需new和delete操作。
2、顺序型容器
2.1 vector容器
1、简介
头文件 #include
vector是STL提供的动态数组,数组的大小可以动态的变化,类似与一个线性数组,索引效率高,插入,删除的效率很低,需要遍历数据列表。
2、优缺点:
优点:支持随机访问,即 [] 操作和 .at(),查询效率高。
缺点:当向头部或中部,插入或删除元素,插入效率低。
3、插入、删除的时间复杂度:

4、定义与初始化
vector<int> vec1; //默认初始化,vec1为空
vector<int> vec2(vec1); //使用vec1初始化vec2
vector<int> vec3(vec1.begin(),vec1.end());//使用vec1初始化vec2
vector<int> vec4(10); //10个值为0的元素
vector<int> vec5(10,4); //10个值为4的元素
vector<string> vec6(10,"null"); //10个值为null的元素
vector<string> vec7(10,"hello"); //10个值为hello的元素
5、常用的操作方法
vec1.push_back(100); //添加元素
int size = vec1.size(); //元素个数
bool isEmpty = vec1.empty(); //判断是否为空
cout<<vec1[0]<<endl; //取得第一个元素
vec1.insert(vec1.end(),5,3); //从vec1.back位置插入5个值为3的元素
vec1.pop_back(); //删除末尾元素
vec1.erase(vec1.begin(),vec1.end());//删除之间的元素,其他元素前移
cout<<(vec1==vec2)?true:false; //判断是否相等==、!=、>=、<=...
vector<int>::iterator iter = vec1.begin(); //获取迭代器首地址
vector<int>::const_iterator c_iter = vec1.begin(); //获取const类型迭代器
vec1.clear(); //清空元素
6、遍历方法
//下标法(vector的特有访问方法,一般容器只能通过迭代器访问)
int length = vec1.size();
for(int i=0;i<length;i++) {
cout<<vec1[i]<<endl;
}
//迭代器法
vector<int>::const_iterator iterator = vec1.begin();
for(;iterator != vec1.end();iterator++) {
cout<<*iterator<<endl;
}
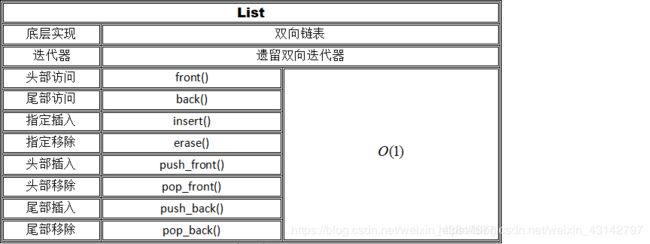
2.2 list容器
1、简介
头文件 #include
由 deque 实现而成,元素也存放在堆中。设计目的是令容器任何位置的添加和删除操作都很快速,作为代价不支持元素的随机访问——为了访问一个元素,只能遍历整个容器。
2、优缺点:
优点:内存不连续,动态操作,可在任意位置插入或删除且效率高。
缺点:不支持随机访问。
3、插入、删除的时间复杂度:
4、定义与初始化
list<int> lst1; //创建空list
list<int> lst2(3); //创建含有三个元素的list
list<int> lst3(3,2); //创建含有三个元素的值为2的list
list<int> lst4(lst2); //使用lst2初始化lst4
list<int> lst5(lst2.begin(),lst2.end()); //同lst4
5、常用的操作方法
lst1.assign(lst2.begin(),lst2.end()); //分配值
lst1.push_back(10); //添加值
lst1.pop_back(); //删除末尾值
lst1.begin(); //返回首值的迭代器
lst1.end(); //返回尾值的迭代器
lst1.clear(); //清空值
bool isEmpty1 = lst1.empty(); //判断为空
lst1.erase(lst1.begin(),lst1.end()); //删除元素
lst1.front(); //返回第一个元素的引用
lst1.back(); //返回最后一个元素的引用
lst1.insert(lst1.begin(),3,2); //从指定位置插入3个值为2的元素
lst1.rbegin(); //返回第一个元素的前向指针
lst1.remove(2); //相同的元素全部删除
lst1.reverse(); //反转
lst1.size(); //含有元素个数
lst1.sort(); //排序
lst1.unique(); //删除相邻重复元素
6、遍历方法
//迭代器法
for(list<int>::const_iterator iter = lst1.begin();iter != lst1.end();iter++) {
cout<<*iter<<endl;
}
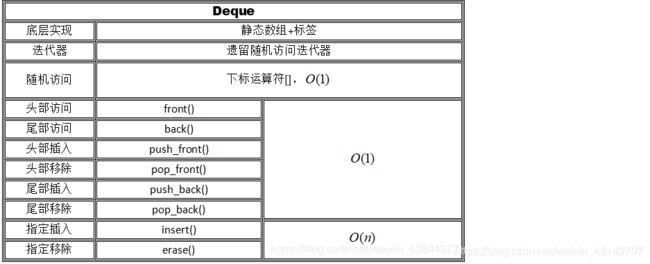
2.3 deque容器
1、简介
头文件 #include
deque容器类与vector类似,支持随机访问和快速插入删除,它在容器中某一位置上的操作所花费的是线性时间。与vector不同的是,deque还支持从开始端插入数据:push_front()。其余类似vector操作方法的使用。
2、优缺点:
优点:支持随机访问,即 [] 操作和 .at(),查询效率高;当向两端,插入或删除元素,插入效率高。
缺点:当向中部,插入或删除元素,插入效率低。
3、插入、删除的时间复杂度:
4、定义与初始化
deque<int> c ; //产生一个空的deque,其中没有任何元素
deque<int> c1(c2); //产生另一个同型deque的副本(所有元素都被拷贝)
deque<int> c(n) ; //产生一个大小为n的deque
deque<int> c(n , elem) ; //产生一个大小为n的deque,每个元素值都是elem。
dequer<int> c(begin,end); //产生一个deque,以区间[begin ; end]做为元素初值
5、常用的操作方法
c.size(); //返回当前的元素数量
c.empty(); //判断大小是否为零。等同于c.size() == 0,但可能更快
c.max_size(); //可容纳元素的最大数量
c.at(idx) ; //返回索引为idx所标示的元素。如果idx越界,抛出out_of_range
c[idx] ; //返回索引idx所标示的元素。不进行范围检查
c.front() ; //返回第一个元素,不检查元素是否存在
c.back(); //返回最后一个元素
c.begin(); //返回一个随机迭代器,指向第一个元素
c.end(); //返回一个随机迭代器,指向最后元素的下一位置
c1 = c2 ; //将c2的所有元素赋值给c1;
c.assign(n , elem); //将n个elem副本赋值给c
c.assing(beg , end); //将区间[beg;end]中的元素赋值给c;
c.push_back(elem); //在尾部添加元素elem
c.pop_back() ; //移除最后一个元素(但不回传)
c.push_front() ; //在头部添加元素elem
c.pop_front() ; //移除头部一个元素(但不回传)
c.erase(pos) ; //移除pos位置上的元素,返回一元素位置,如 c.erase( c.begin() + 5)移除第五个元素
c.insert(pos , elem); //在pos位置插入一个元素elem,并返回新元素的位置
c.insert(pos , n , elem); //在pos位置插入n个元素elem,无返回值
c.insert(pos , beg , end);
c.resize(num); //将容器大小改为num。可更大或更小。
c.resize(num , elem); //将容器大小改为num,新增元素都为 elem
c.clear(); //移除所有元素,将容器清空
3、有序关联容器
3.1 set(集合)和 multiset(多重集合)
multiset 和 set用法几乎一致,只是multiset可以允许值重复而已,在此就不重复介绍了。
1、简介
头文件 #include
set(集合):由红黑树实现,其中每个元素只包含一个关键字并依据其值自动排序,支持高效的关键字查询操作,每个元素值只能出现一次,不允许重复。插入和删除效率比用其他序列容器高,因为对于关联容器来说,不需要做内存拷贝和内存移动。
multiset(多重集合):唯一的区别是插入的元素可以相同。
2、优缺点:
优点:关键字查询高效,且元素唯一,以及能自动排序。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
3、插入、删除的时间复杂度:

4、定义与初始化
set<int> iset(ivec.begin(), ivec.end()); // 根据迭代器范围内的元素初始化
set<int> set1; // 创建一个空的set集合
5、常用的操作方法
set1.insert("the"); //第一种方法:直接添加
iset2.insert(ivec.begin(), ivec.end());//第二种方法:通过指针迭代器
set1.size(); //元素个数
set1.empty(); //判断空
set1.find(); // 返回一个迭代器,此迭代器指向集合中其值与指定值相等的元素的位置。
set1.begin(); // 返回一个迭代器,此迭代器指向集合中的第一个元素。
set1.end(); // 返回超过末尾迭代器。
set1.cbegin(); // 返回一个常量迭代器,此迭代器指向集合中的第一个元素。
set1.cend(); // 返回一个超过末尾常量迭代器。
6、遍历方法
//正向迭代器
for(set<int>::iterator iter = set1.begin();iter!=set1.end();iter++) {
cout << *iter << endl;
}
//反向迭代
for(set<int>::iterator iter = set1.rbegin();iter!=set1.rend();iter++) {
cout << *iter << endl;
}
7、删除方法
set1.erase(iterator it); //删除迭代器指向的对象
set1.erase(iterator first,iterator last); //删除first到last迭代器范围中的内容
set1.erase(value); //通过值删除
set1.clear(); // 清空所有元素,相对于set1.erase(set1.begin(),set1.end());
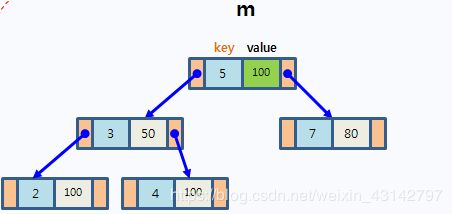
3.2 map(映射)和multimap(多重映射)
multimap 和 map用法几乎一致,只是multimap可以允许值重复而已,在此就不重复介绍了。
1、简介
头文件 #include
map(映射):由红黑树实现,其中每个元素都是一些 键值对(key-value):关键字起索引作用,值表示与索引相关联的数据。每个元素有一个键,是排序准则的基础。每一个键只能出现一次,不允许重复。插入和删除效率比用其他序列容器高,因为对于关联容器来说,不需要做内存拷贝和内存移动。
multimap(多重映射):唯一的区别是插入的元素(值)可以相同,即同一个键可以对应多个值。
2、优缺点:
优点:关键字查询高效,且元素唯一,以及能自动排序。把一个值映射成另一个值,可以创建字典。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
3、插入、删除的时间复杂度:

4、定义与初始化
map<k, v>m // 创建一个名为m的空map对象,其键和值的类型分别为k和v
map<k, v> m(m2) // 创建m2的副本m,m与m2必须有相同的键类型和值类型
map<k, v> m(b, e) // 创建map类型的对象m,存储迭代器b和e标记的范围内所有元素的副本。元素的类型必须能转换为pair5、常用的操作方法
// 插入元素
map1[3] = "Saniya"; //添加一个键为 3,值为"Saniya"的键-值对
map1.insert(map<int,string>::value_type(2,"Diyabi"));//插入元素
map1.insert(pair<int,string>(1,"Siqinsini")); //插入一个pair类型的键-值对
map1.insert(make_pair<int,string>(4,"V5")); //通过make_pair插入一个pair类型的键-值对
map1.insert(iterator first,iterator last); // 插入另一个map在迭代器范围内的数据
//其他
map<int,string>::iterator iter_map = map1.begin();//取得迭代器首地址
int key = iter_map->first; //取得key
string value = iter_map->second; //取得value
map1.size(); //元素个数
map1.empty(); //判断空
map1.find(); // 返回一个迭代器,此迭代器指向映射中其键与指定键相等的元素的位置。
map1.begin(); // 返回一个迭代器,此迭代器指向映射中的第一个元素。
map1.end(); // 返回超过末尾迭代器。
map1.cbegin(); // 返回一个常量迭代器,此迭代器指向映射中的第一个元素。
map1.cend(); // 返回一个超过末尾常量迭代器。
map1.count(); // 返回映射中其键与参数中指定的键匹配的元素数量。
6、遍历方法
//正向迭代器
for(map<int,string>::iterator iter = map1.begin();iter!=map1.end();iter++) {
int keyk = iter->first;
string valuev = iter->second;
}
//反向迭代
for(map<int,string>::iterator iter = map1.rbegin();iter!=map1.rend();iter++) {
int keyk = iter->first;
string valuev = iter->second;
}
7、删除方法
map1.erase(iterator it); //删除迭代器指向的对象
map1.erase(iterator first,iterator last); //删除first到last迭代器范围中的内容
map1.erase(const Key&key); //通过关键字删除
map1.clear(); // 清空所有元素,相对于map1.erase(map1.begin(),map1.end());
4、无序关联容器
4.1 unordered_map/unordered_multimap
unordered_multimap 和 unordered_map用法几乎一致,只是unordered_multimap 可以允许值重复而已,在此就不重复介绍了。
1、简介
头文件 #include
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。unordered_map的底层是一个防冗余的哈希表(开链法避免地址冲突)。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,时间复杂度为O(1);而代价仅仅是消耗比较多的内存。哈希表的查询时间虽然是O(1),但是并不是unordered_map查询时间一定比map短,因为实际情况中还要考虑到数据量。
2、优缺点:
优点: 因为内部实现了哈希表,因此其查找速度非常的快
缺点: 哈希表的建立比较耗费时间
3、初始化
unordered_map<string, int> map1; map1[string("abc")] = 1; map1["def"] = 2;//创建空map,再赋值
unordered_map<string, int> map2(map1); //拷贝构造
unordered_map<string, int> map3(map1.find("abc"), map1.end()); //迭代器构造
unordered_map<string, int> map4(move(map2)); //移动构造
unordered_map<string, int> map5 {{"this", 100},{"can", 100},};//使用initializer_list初始化
4、常见用法
map1.at("abc"); //查找具有指定key的元素,返回value
map1.find("abc"); //查找键为key的元素,找到返回迭代器,失败返回end()
map1.count("abc"); //返回指定key出现的次数,0或1
map1.emplace(make_pair("str1", 1)); //使用pair的转换移动构造函数,返回pair::iterator, bool>
map1.emplace("str2", 2); //使用pair的模板构造函数,如果key已经存在则什么都不做
map1.insert(pair<string ,int>("sex", 1));//插入元素,返回pair::iterator, bool>
map1.insert(unordered_map<string, int>::value_type("sex", 1));//插入元素,如果key已经存在则什么都不做
map1.insert(make_pair("sex", 1));//插入元素,返回pair::iterator, bool>,插入成功second为true,失败为flase
map1.insert({"sex", 1}); //使用initializer_list插入元素
map1.insert(map1.end(), {"sex", 1});//指定插入位置,如果位置正确会减少插入时间
map1.insert(map2.begin(), map2.end());//使用范围迭代器插入
map1.erase("abc"); //删除操作,成功返回1,失败返回0
map1.erase(map1.find("abc")); //删除操作,成功返回下一个pair的迭代器
map1.erase(map1.begin(), map1.end()); //删除map1的所有元素,返回指向end的迭代器
map1.empty(); //是否为空
map1.size(); //大小
map1.bucket_count(); //返回容器中的桶数
map1.bucket_size(1); //返回1号桶中的元素数
map1.bucket("abc"); //abc这个key在哪一个桶
map1.load_factor(); //负载因子,返回每个桶元素的平均数,即size/float(bucket_count);
map1.max_load_factor();//返回最大负载因子
map1.max_load_factor(2);//设置最大负载因子为2,rehash(0)表示强制rehash
map1.rehash(20);//设置桶的数量为20,并且重新rehash
map1.reserve(20);//将容器中的桶数设置为最适合元素个数,如果20大于当前的bucket_count乘max_load_factor,则增加容器的bucket_count并强制重新哈希。如果20小于该值,则该功能可能无效。
unordered_map<string, int>::iterator it = map1.begin(); //返回指向map1首元素的迭代器
unordered_map<string, int>::const_iterator c_it = map1.cbegin(); //返回指向map1首元素的常量迭代器
unordered_map<string, int>::local_iterator it = map1.begin(1);//返回1号桶中的首元素迭代器
unordered_map<string, int>::const_local_iterator c_it = map1.cbegin(1);//返回1号桶中的首元素的常量迭代器
pair<unordered_map<string, int>::iterator, unordered_map<string, int>::iterator> it = map1.equal_range("abc");//返回一个pair,pair里面第一个变量是lower_bound返回的迭代器,第二个迭代器是upper_bound返回的迭代器
map1.clear(); //清空
5、示例

4.2 unordered_set/unordered_multiset
unordered_multiset 和 unordered_set 用法几乎一致,只是unordered_multiset 可以允许值重复而已,在此就不重复介绍了。
1、简介
头文件 #include
unordered_set基于哈希表,数据插入和查找的时间复杂度很低,几乎是常数时间,而代价是消耗比较多的内存,无自动排序功能。底层实现上,使用一个下标范围比较大的数组来存储元素,形成很多的桶,利用hash函数对key进行映射到不同区域进行保存。
2、优缺点:
优点: 因为内部实现了哈希表,因此其查找速度非常的快
缺点: 哈希表的建立比较耗费时间
3、初始化
unordered_set<int> set1; //创建空set
unordered_set<int> set2(set1); //拷贝构造
unordered_set<int> set3(set1.begin(), set1.end()); //迭代器构造
unordered_set<int> set4(arr,arr+5); //数组构造
unordered_set<int> set5(move(set2)); //移动构造
unordered_set<int> set6 {1,2,10,10};//使用initializer_list初始化
4、常见用法
set1.find(2); //查找2,找到返回迭代器,失败返回end()
set1.count(2); //返回指2出现的次数,0或1
set1.emplace(3); //使用转换移动构造函数,返回pair::iterator, bool>
set1.insert(3); //插入元素,返回pair::iterator, bool>
set1.insert({1,2,3}); //使用initializer_list插入元素
set1.insert(set1.end(), 4);//指定插入位置,如果位置正确会减少插入时间,返回指向插入元素的迭代器
set1.insert(set2.begin(), set2.end());//使用范围迭代器插入
set1.erase(1); //删除操作,成功返回1,失败返回0
set1.erase(set1.find(1)); //删除操作,成功返回下一个pair的迭代器
set1.erase(set1.begin(), set1.end()); //删除set1的所有元素,返回指向end的迭代器
set1.empty(); //是否为空
set1.size(); //大小
set1.bucket_count(); //返回容器中的桶数
set1.bucket_size(1); //返回1号桶中的元素数
set1.bucket(1); //1在哪一个桶
set1.load_factor(); //负载因子,返回每个桶元素的平均数,即size/float(bucket_count);
set1.max_load_factor();//返回最大负载因子
set1.max_load_factor(2);//设置最大负载因子为2,rehash(0)表示强制rehash
set1.rehash(20);//设置桶的数量为20,并且重新rehash
set1.reserve(20);//将容器中的桶数设置为最适合元素个数,如果20大于当前的bucket_count乘max_load_factor,则增加容器的bucket_count并强制重新哈希。如果20小于该值,则该功能可能无效。
unordered_set<int>::iterator it = set1.begin(); //返回指向set1首元素的迭代器
unordered_set<int>::const_iterator c_it = set1.cbegin(); //返回指向set1首元素的常量迭代器
unordered_set<int>::local_iterator it = set1.begin(1);//返回1号桶中的首元素迭代器
unordered_set<int>::const_local_iterator c_it = set1.cbegin(1);//返回1号桶中的首元素的常量迭代器
pair<unordered_set<int>::iterator, unordered_set<int>::iterator> it = set1.equal_range(1);//返回一个pair,pair里面第一个变量是lower_bound返回的迭代器,第二个迭代器是upper_bound返回的迭代器
set1.clear(); //清空
5、容器适配器
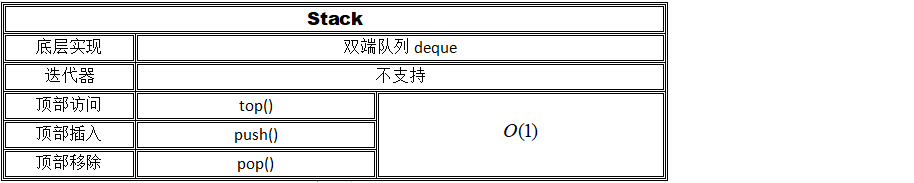
5.1 stack容器
1、简介
头文件 #include
C++ Stack(堆栈) 是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。
2、插入、删除的时间复杂度:
3、常用的操作方法
s1.empty() //堆栈为空则返回真
s1.pop() //移除栈顶元素
s1.push() //在栈顶增加元素
s1.size() //返回栈中元素数目
s1.top() //返回栈顶元素
5.2 queue容器
1、简介
头文件 #include
queue具有先进先出的数据结构。持新增元素、移除元素、从最底端加入元素、取最顶端元素。

2、插入、删除的时间复杂度:
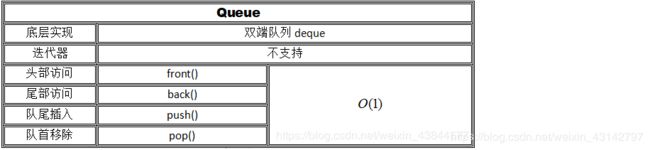
3、常用的操作方法
q.push(x); //入队,将x元素接到队列的末端;
q.pop(); //出队,弹出队列的第一个元素,并不会返回元素的值;
q.front(); //访问队首元素
q.back(); //访问队尾元素
q.size(); // 访问队中的元素个数
q.empty(); //判断队列是否为空
5.3 priority_queue容器
1、简介
头文件 #include
priority_queue实现了优先队列这一ADT,也就是我们常说的堆。但要明晰的是,优先队列是一种ADT,而堆是它的一种具体实现。在默认状态下,priority_queue实现的是大根堆,但你可以通过模板特化从而实现小根堆。
定义:priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式。
当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆,如下所示:
//升序队列,小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//降序队列,大顶堆
priority_queue <int,vector<int>,less<int> >q;
//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。
//其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
2、插入、删除的时间复杂度:
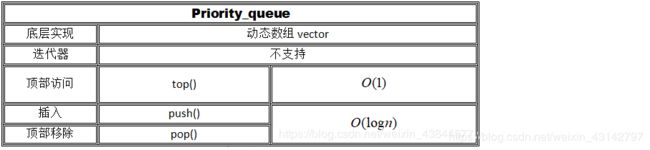
3、常用的操作方法
q.push(x); //入队,将x元素接到队列的末端,(并排序)
q.pop(); //出队,弹出队列的第一个元素,并不会返回元素的值;
q.front(); //访问队首元素
q.back(); //访问队尾元素
q.size(); // 访问队中的元素个数
q.empty(); //判断队列是否为空
整理博客不易,如果本文对你有所帮助,请给博主 点赞 + 收藏 + 关注!谢谢!
参考:https://blog.csdn.net/u014465639/article/details/70241850
https://blog.csdn.net/like_that/article/details/98446479
https://blog.csdn.net/weixin_43844677/article/details/104902417
https://blog.csdn.net/zhuikefeng/article/details/104738544